Operating Systems Notes — Fundamentals to Kernel Programming
Comprehensive guide to OS concepts, memory, processes, scheduling and kernel internals

A Comprehensive Journey Through Operating System Concepts, Architecture, and Implementation
1. Introduction to Operating Systems
What is an Operating System?
An Operating System (OS) is sophisticated system software that manages computer hardware resources and provides an environment for application programs to execute efficiently. It serves as the critical intermediary layer between the bare metal hardware and user applications, abstracting complex hardware details while providing essential services.
Core Responsibilities:
- Resource Management: Orchestrates CPU time, memory allocation, storage access, and I/O device operations
- Hardware Abstraction: Shields applications from hardware complexity through standardized interfaces
- Process Isolation: Ensures programs run independently without interfering with each other
- Security Enforcement: Implements access controls and protection mechanisms
- User Interface: Provides means for users to interact with the system
Why Study Operating Systems?
Understanding operating systems is fundamental for several critical reasons:
Foundation of All Computing
- Nearly every application executes atop an operating system
- OS behavior directly impacts application performance, security, and reliability
- Modern cloud infrastructure, mobile devices, and embedded systems all rely on OS principles
Performance Optimization
- Deep OS knowledge enables writing high-performance code
- Understanding scheduling, caching, and memory management leads to better algorithmic choices
- Ability to diagnose and resolve performance bottlenecks
Security and Reliability
- OS provides the trust boundary for system security
- Knowledge of OS internals helps identify and prevent vulnerabilities
- Understanding process isolation and memory protection prevents common exploits
Career Advancement
- Essential knowledge for system programming, embedded development, and infrastructure roles
- Required for roles in kernel development, device drivers, and low-level software
- Valuable for cloud architecture, distributed systems, and high-performance computing
Historical Evolution
First Generation (1945-1955): Vacuum Tubes and Plugboards
- Characteristics: No operating system concept; direct hardware programming
- Programming Method: Machine language with plugboards for connections
- Key Limitation: One program at a time; no multiprogramming
- Example Systems: ENIAC, UNIVAC I
Second Generation (1955-1965): Transistors and Batch Systems
- Key Innovation: Introduction of batch processing
- Batch System Concept: Group similar jobs together; process sequentially
- Advantages: Reduced setup time; improved resource utilization
- Programming: Assembly language and early compilers (FORTRAN, COBOL)
- Notable Systems: IBM 7094, Atlas Computer
Third Generation (1965-1980): Integrated Circuits and Multiprogramming
- Breakthrough: Integrated circuits enabled smaller, faster, and cheaper computers
- Multiprogramming: Multiple jobs in memory simultaneously; CPU switches between them
- Time-Sharing: Interactive computing with multiple users
- Key Concepts: Spooling, virtual memory, file systems
- Landmark Systems: IBM System/360, UNIX (1969), MULTICS
Fourth Generation (1980-Present): Personal Computers
- Revolution: Microprocessors enabled personal computers
- GUI Introduction: Graphical User Interfaces (Windows, Mac OS, X Window System)
- Network Operating Systems: Client-server architectures
- Notable Systems: MS-DOS, Windows, Mac OS, Linux (1991)
Fifth Generation (1990-Present): Mobile and Distributed Computing
- Mobile OS: iOS (2007), Android (2008)
- Cloud Computing: Virtualization, containerization
- Distributed Systems: Microservices architecture
- IoT: Embedded and real-time operating systems
- Modern Trends: Rust-based OS development, RISC-V architecture
2. Computer Hardware Fundamentals
Understanding operating systems requires solid knowledge of underlying hardware components.
The Transistor: Building Block of Computing
A transistor is a semiconductor device functioning as an electronic switch with two states: conducting (ON) or non-conducting (OFF). These binary states represent the fundamental 0s and 1s of digital computing.
Key Facts:
- Modern CPUs contain billions of transistors (Apple M2: ~20 billion; AMD EPYC: ~40+ billion)
- Transistor density follows Moore’s Law: doubling approximately every two years
- Advanced manufacturing processes now reach 3nm and smaller
Transistor Evolution:
1947: First transistor (Bell Labs) - Point-contact type
1959: Planar silicon transistor - Foundation for ICs
1971: Intel 4004 - 2,300 transistors
2023: AMD EPYC Genoa - 57 billion transistorsIntegrated Circuits (ICs)
An Integrated Circuit is a complete electronic circuit fabricated on a single semiconductor wafer (typically silicon). It contains millions or billions of interconnected transistors, resistors, and capacitors forming complex circuitry.
Types:
- SSI (Small-Scale Integration): < 100 components
- MSI (Medium-Scale Integration): 100-1000 components
- LSI (Large-Scale Integration): 1000-100,000 components
- VLSI (Very Large-Scale Integration): > 100,000 components
- ULSI (Ultra Large-Scale Integration): > 1 million components
Central Processing Unit (CPU)
The CPU is the primary computational engine, often called the “brain” of the computer. It fetches instructions from memory, decodes them, executes operations, and stores results.
CPU Architecture Components
1. Arithmetic Logic Unit (ALU)
Functions:
├── Arithmetic Operations
│ ├── Addition, Subtraction
│ ├── Multiplication, Division
│ └── Modulo operations
└── Logical Operations
├── AND, OR, XOR, NOT
├── Bit shifting (Left/Right)
└── Comparison operationsImplementation Concept:
// Simplified ALU operation representation
uint32_t alu_execute(uint8_t operation, uint32_t operand_a, uint32_t operand_b) {
switch(operation) {
case ALU_ADD: return operand_a + operand_b;
case ALU_SUB: return operand_a - operand_b;
case ALU_AND: return operand_a & operand_b;
case ALU_OR: return operand_a | operand_b;
case ALU_XOR: return operand_a ^ operand_b;
case ALU_SHL: return operand_a << operand_b;
case ALU_SHR: return operand_a >> operand_b;
default: return 0; // Invalid operation
}
}2. Control Unit (CU)
The Control Unit orchestrates CPU operations by:
- Fetching instructions from memory
- Decoding instruction opcodes
- Generating control signals for other components
- Managing instruction sequencing
Instruction Cycle (Fetch-Decode-Execute):
1. FETCH: Retrieve instruction from memory[PC]
2. DECODE: Interpret opcode and extract operands
3. EXECUTE: Perform operation via ALU or other units
4. STORE: Write results back to registers/memory
5. INCREMENT: Update Program Counter (PC)3. Registers
Registers are ultra-fast storage locations within the CPU for immediate data access.
Essential Register Types:
| Register | Purpose | Description |
|---|---|---|
| Program Counter (PC) | Next Instruction Address | Points to memory address of next instruction to execute |
| Instruction Register (IR) | Current Instruction | Holds instruction currently being executed |
| Accumulator (ACC) | ALU Results | Stores intermediate arithmetic/logic results |
| Memory Address Register (MAR) | Memory Address | Contains address for memory read/write operations |
| Memory Data Register (MDR) | Memory Data | Buffer for data read from or written to memory |
| Stack Pointer (SP) | Stack Top | Points to top of the runtime stack |
| Status Register (FLAGS) | Processor State | Contains condition codes (Zero, Carry, Negative, Overflow) |
| General Purpose Registers | Data Storage | R0-R15 (ARM), RAX-R15 (x86-64) for various operations |
Register Example (x86-64 Architecture):
; Example: Adding two numbers using registers
mov rax, 10 ; Load 10 into RAX register
mov rbx, 20 ; Load 20 into RBX register
add rax, rbx ; Add RBX to RAX (result: RAX = 30)
mov [result], rax ; Store result in memory4. Cache Memory Hierarchy
Modern CPUs employ multi-level caching to bridge the speed gap between processor and main memory.
Cache Levels:
CPU Registers (< 1 KB)
↓ Access: 0 cycles
L1 Cache (32-64 KB per core)
↓ Access: 1-4 cycles
L2 Cache (256-512 KB per core)
↓ Access: 10-20 cycles
L3 Cache (8-64 MB shared)
↓ Access: 40-70 cycles
Main Memory (4-256 GB)
↓ Access: 100-300 cycles
SSD Storage (128 GB - 4 TB)
↓ Access: ~50,000 cycles
HDD Storage (500 GB - 20 TB)
↓ Access: ~10,000,000 cyclesCache Properties:
- Cache Line: Typically 64 bytes; unit of transfer between cache levels
- Cache Hit: Data found in cache (fast access)
- Cache Miss: Data not in cache, must fetch from lower level (slow)
- Cache Coherence: Maintaining consistency across multiple caches in multicore systems
Cache Coherence Protocols:
- MESI Protocol (Modified, Exclusive, Shared, Invalid)
- MOESI Protocol (adds Owned state)
- Ensures all CPUs see consistent memory values
Graphics Processing Unit (GPU)
GPUs are specialized processors optimized for parallel computation, originally designed for graphics rendering but now widely used for general-purpose computing.
Key Differences from CPUs:
| Aspect | CPU | GPU |
|---|---|---|
| Core Count | 4-64 high-performance cores | 1000s of simpler cores |
| Design Philosophy | Optimized for latency | Optimized for throughput |
| Task Suitability | Complex, sequential tasks | Highly parallel, repetitive tasks |
| Memory | Large cache hierarchy | High-bandwidth memory |
| Control Flow | Complex branching | SIMT (Single Instruction, Multiple Threads) |
GPU Applications:
- Graphics rendering and ray tracing
- Machine learning and deep neural networks
- Scientific simulations (computational fluid dynamics, molecular modeling)
- Cryptocurrency mining
- Video encoding/decoding
Memory Systems
Memory Hierarchy Goals:
- Speed: Fast access for frequently used data
- Capacity: Large storage for all program data
- Cost: Balance between performance and affordability
Primary Memory (Volatile)
Random Access Memory (RAM)
- DRAM (Dynamic RAM): Main memory; needs periodic refresh; slower but denser
- DDR4: 2133-3200 MT/s, 16-64 GB typical
- DDR5: 4800-8400 MT/s, 16-128 GB typical
- SRAM (Static RAM): Cache memory; no refresh needed; faster but more expensive
- Used in L1/L2/L3 caches
Memory Access Patterns:
// Demonstrating cache-friendly vs cache-unfriendly access
// Cache-friendly: Sequential access (spatial locality)
void sum_array_row_major(int arr[N][N]) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
sum += arr[i][j]; // Sequential memory access
}
}
}
// Cache-unfriendly: Column-major in row-major storage
void sum_array_column_major(int arr[N][N]) {
for (int j = 0; j < N; j++) {
for (int i = 0; i < N; i++) {
sum += arr[i][j]; // Jumps across cache lines
}
}
}Secondary Storage (Non-Volatile)
Solid State Drives (SSDs)
- Technology: NAND flash memory
- Speed: 500-7000 MB/s (SATA to NVMe)
- Latency: 50-100 microseconds
- Wear Leveling: Distributes writes to prevent cell degradation
Hard Disk Drives (HDDs)
- Technology: Magnetic storage on rotating platters
- Speed: 100-200 MB/s
- Latency: 5-15 milliseconds (seek time + rotational delay)
- Capacity: Up to 20 TB per drive
Storage Technologies Comparison:
| Technology | Speed | Latency | Cost per GB | Durability | Use Case |
|---|---|---|---|---|---|
| RAM | 20+ GB/s | 50-100 ns | High | Volatile | Active data |
| NVMe SSD | 3-7 GB/s | 50-100 μs | Medium | Limited writes | OS, applications |
| SATA SSD | 500 MB/s | 50-100 μs | Medium-Low | Limited writes | General storage |
| HDD | 100-200 MB/s | 5-15 ms | Low | High | Archival, bulk storage |
System Bus Architecture
The System Bus is a collection of parallel electrical conductors connecting CPU, memory, and I/O devices.
Bus Types:
1. Data Bus
- Carries actual data between components
- Width determines data transfer rate (32-bit, 64-bit)
- Bidirectional
2. Address Bus
- Carries memory addresses
- Width determines addressable memory space
- 32-bit: 4 GB (2³² bytes)
- 64-bit: 16 Exabytes (2⁶⁴ bytes)
- Unidirectional (CPU to memory/devices)
3. Control Bus
- Carries control signals (read, write, interrupt, clock)
- Coordinates bus operations
- Bidirectional
Bus Operation Example:
CPU wants to read memory location 0x1000:
1. CPU places 0x1000 on Address Bus
2. CPU asserts READ control signal on Control Bus
3. Memory responds by placing data at 0x1000 onto Data Bus
4. CPU reads data from Data Bus
5. CPU de-asserts READ signal3. Operating System Architecture
OS Design Principles
Separation of Mechanism and Policy
- Mechanism: How to do something (implementation)
- Policy: What should be done (decision-making)
- Benefit: Flexibility; policies can change without altering mechanisms
Example:
Mechanism: Context switching between processes
Policy: Which process to run next (scheduling algorithm)Optimization for Common Case
- Design decisions should favor frequently occurring scenarios
- Identify workload characteristics and usage patterns
- Balance generality with specialized optimization
Kernel Architectures
1. Monolithic Kernel
Concept: All OS services run in kernel space with full hardware access.
Structure:
User Space
│
├─ Application 1
├─ Application 2
└─ Application N
────────────── System Call Interface ──────────────
Kernel Space (Single Address Space)
│
├─ Process Management
├─ Memory Management
├─ File System
├─ Device Drivers
├─ Network Stack
└─ Scheduling
────────────── Hardware ──────────────Advantages of Monolithic Kernel:
- Performance: Direct function calls within kernel; no context switching overhead
- Simplicity: Straightforward design and implementation
- Efficiency: Minimal message passing overhead
Disadvantages of Monolithic Kernel:
- Reliability: Bug in any component can crash entire system
- Maintainability: Large, complex codebase difficult to maintain
- Security: Large attack surface; any vulnerability affects whole kernel
Examples: Linux, traditional UNIX, Windows 9x
Linux Kernel Structure:
// Simplified representation of kernel subsystems
struct linux_kernel {
struct process_manager {
struct task_struct *process_list;
struct scheduler *sched;
} pm;
struct memory_manager {
struct page_table *pgd;
struct vm_area *vma_list;
} mm;
struct file_system {
struct super_block *sb;
struct inode_cache *icache;
} fs;
struct network_stack {
struct socket *socket_list;
struct protocol_handler *protocols;
} net;
};2. Microkernel Architecture
Concept: Minimal kernel with essential services only; other services run in user space.
Structure:
User Space
│
├─ File Server
├─ Device Drivers
├─ Network Server
├─ Applications
────────────── IPC (Message Passing) ──────────────
Kernel Space (Minimal)
│
├─ IPC Mechanism
├─ Basic Scheduling
├─ Low-level Memory Management
└─ Hardware Abstraction
────────────── Hardware ──────────────Essential Kernel Services:
- Inter-Process Communication (IPC)
- Basic thread scheduling
- Low-level address space management
- Interrupt handling
Advantages of Microkernel:
- Fault Isolation: Service crash doesn’t affect kernel
- Modularity: Easy to add/remove services
- Security: Smaller trusted computing base (TCB)
- Portability: Hardware-specific code isolated
Disadvantages of Microkernel:
- Performance: IPC overhead for service communication
- Complexity: More complex system structure
- Development Effort: Requires careful IPC design
Examples: MINIX 3, L4 microkernel family, QNX, seL4
Microkernel IPC Example:
// Simplified IPC message passing
struct message {
int src_pid;
int dst_pid;
int msg_type;
char data[1024];
};
// Send message to file server
int read_file(const char *path, char *buffer, size_t size) {
struct message msg;
msg.src_pid = getpid();
msg.dst_pid = FILE_SERVER_PID;
msg.msg_type = MSG_READ_FILE;
strcpy(msg.data, path);
// Send to microkernel IPC
send_message(&msg);
// Wait for reply
receive_message(&msg);
// Copy data from reply
memcpy(buffer, msg.data, size);
return msg.msg_type; // Return value
}3. Hybrid Kernel
Concept: Combines monolithic and microkernel approaches; some services in kernel for performance, others in user space.
Structure:
User Space
│
├─ User-mode Services
├─ Device Drivers (some)
└─ Applications
────────────── Mixed Interface ──────────────
Kernel Space
│
├─ Core Kernel (Microkernel-like)
│ ├─ IPC
│ ├─ Scheduling
│ └─ Low-level MM
│
└─ Integrated Services (Monolithic-like)
├─ File System
├─ Device Drivers (critical)
└─ Network Stack
────────────── Hardware ──────────────Advantages:
- Balances performance and modularity
- Critical services in kernel for speed
- Non-critical services in user space for safety
Examples:
- Windows NT/modern Windows: NT kernel (hybrid)
- macOS XNU: Mach microkernel + BSD monolithic components
XNU (macOS/iOS Kernel) Architecture:
┌─────────────────────────────────────┐
│ User Space Applications │
├─────────────────────────────────────┤
│ System Libraries │
│ (libSystem, Foundation, etc.) │
├─────────────────────────────────────┤
│ XNU Kernel │
│ ┌─────────────────────────────┐ │
│ │ BSD Layer (Monolithic) │ │
│ │ - POSIX compatibility │ │
│ │ - Networking (TCP/IP) │ │
│ │ - VFS (Virtual File System)│ │
│ ├─────────────────────────────┤ │
│ │ Mach Layer (Microkernel) │ │
│ │ - IPC (Mach ports) │ │
│ │ - Virtual Memory │ │
│ │ - Task/Thread management │ │
│ ├─────────────────────────────┤ │
│ │ I/O Kit (C++ drivers) │ │
│ └─────────────────────────────┘ │
├─────────────────────────────────────┤
│ Hardware │
└─────────────────────────────────────┘4. Exokernel
Concept: Expose hardware resources directly to applications; OS provides minimal abstraction.
Philosophy: Applications know best how to manage resources for their specific needs.
Advantages:
- Maximum performance and flexibility
- Application-level resource management
- Eliminates unnecessary abstraction layers
Disadvantages:
- Complex application development
- Limited protection between applications
- Difficult to program
Examples: MIT Exokernel, Aegis
5. Unikernel
Concept: Single address space machine image; application and OS services compiled into single binary.
Structure:
┌──────────────────────────────┐
│ Application Code │
│ + OS Services (LibOS) │
│ (Single Binary) │
├──────────────────────────────┤
│ Hypervisor / Hardware │
└──────────────────────────────┘Advantages:
- Minimal attack surface
- Fast boot times (milliseconds)
- Small memory footprint
- Optimized for specific applications
Disadvantages:
- Lack of dynamic process management
- Limited debugging tools
- Application must be recompiled for changes
Examples: MirageOS (OCaml), IncludeOS (C++), HalVM (Haskell)
Use Cases:
- Cloud microservices
- IoT devices
- Network appliances
System Layers
User Mode vs Kernel Mode
Modern processors provide privilege levels (protection rings) to enforce security and stability.
x86 Protection Rings:
Ring 3 (Lowest Privilege) ─── User Applications
Ring 2 (Device Drivers - rarely used)
Ring 1 (Device Drivers - rarely used)
Ring 0 (Highest Privilege) ─── Operating System KernelARM Exception Levels (ARMv8):
EL0 ─── User Applications
EL1 ─── Operating System Kernel
EL2 ─── Hypervisor
EL3 ─── Secure Monitor (TrustZone)Mode Transition: User programs cannot directly access hardware or privileged instructions. They must request OS services via system calls, which trigger a mode switch.
Mode Switch Process:
1. Application executes syscall instruction (INT 0x80, SYSCALL, SVC)
2. CPU switches from User Mode to Kernel Mode
3. CPU saves user context (registers, program counter)
4. CPU jumps to kernel's system call handler
5. Kernel validates request and executes service
6. Kernel prepares return value
7. CPU restores user context
8. CPU switches back to User Mode
9. Application resumes with resultProtection Benefits:
- Isolation: Faulty applications can’t crash the system
- Security: Malicious code can’t directly manipulate hardware
- Stability: Critical OS data structures protected from corruption
4. Boot Process and System Initialization
x86 Boot Sequence
1. Power-On Self-Test (POST)
Power On → CPU Reset → POST
│
├─ Test CPU registers
├─ Check memory
├─ Initialize chipset
├─ Detect hardware
└─ Display boot screen2. BIOS/UEFI Initialization
Legacy BIOS (Basic Input/Output System):
- Stored in ROM/flash on motherboard
- Executes in 16-bit real mode
- Loads Master Boot Record (MBR) from boot device
MBR Structure (512 bytes):
Offset Size Description
0x000 446 Boot code
0x1BE 16 Partition entry 1
0x1CE 16 Partition entry 2
0x1DE 16 Partition entry 3
0x1EE 16 Partition entry 4
0x1FE 2 Boot signature (0x55AA)Simple MBR Boot Code (x86 Assembly):
; boot.asm - Minimal bootloader
BITS 16 ; 16-bit real mode
ORG 0x7C00 ; BIOS loads us at 0x7C00
start:
; Setup segments
xor ax, ax
mov ds, ax
mov es, ax
mov ss, ax
mov sp, 0x7C00
; Display message
mov si, message
call print_string
; Hang
jmp $
print_string:
lodsb ; Load byte from [SI] into AL
or al, al ; Check if zero (end of string)
jz done
mov ah, 0x0E ; BIOS teletype function
int 0x10 ; Call BIOS video interrupt
jmp print_string
done:
ret
message db 'Booting...', 0x0D, 0x0A, 0
times 510-($-$$) db 0 ; Pad to 510 bytes
dw 0xAA55 ; Boot signatureUEFI (Unified Extensible Firmware Interface):
- Modern replacement for BIOS
- Supports 32-bit and 64-bit modes
- GPT (GUID Partition Table) instead of MBR
- More secure (Secure Boot)
- Includes a boot manager
UEFI Boot Process:
Power On → UEFI Firmware → Boot Manager → Boot Loader → OS Kernel3. Bootloader Execution
GRUB (Grand Unified Bootloader):
Stage 1: Bootstrap code (in MBR or GPT)
↓
Stage 1.5: Filesystem drivers (if needed)
↓
Stage 2: Full GRUB with menu
↓
Kernel Loading: Load kernel image into memory
↓
Kernel Execution: Jump to kernel entry pointMultiboot Specification:
// Multiboot header (must be in first 8KB of kernel)
#define MULTIBOOT_HEADER_MAGIC 0x1BADB002
#define MULTIBOOT_HEADER_FLAGS 0x00000003
.section .multiboot
.align 4
multiboot_header:
.long MULTIBOOT_HEADER_MAGIC
.long MULTIBOOT_HEADER_FLAGS
.long -(MULTIBOOT_HEADER_MAGIC + MULTIBOOT_HEADER_FLAGS)4. Protected Mode Transition
Real mode has limitations:
- Only 1 MB addressable memory
- No memory protection
- 16-bit operations
Entering Protected Mode:
; Disable interrupts
cli
; Load Global Descriptor Table (GDT)
lgdt [gdt_descriptor]
; Set PE (Protection Enable) bit in CR0
mov eax, cr0
or eax, 0x1
mov cr0, eax
; Far jump to load CS with code segment selector
jmp 0x08:protected_mode
[BITS 32]
protected_mode:
; Setup data segments
mov ax, 0x10 ; Data segment selector
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
mov ss, ax
; Setup stack
mov esp, 0x90000
; Jump to kernel
call kernel_mainGlobal Descriptor Table (GDT):
struct gdt_entry {
uint16_t limit_low;
uint16_t base_low;
uint8_t base_middle;
uint8_t access;
uint8_t granularity;
uint8_t base_high;
} __attribute__((packed));
struct gdt_ptr {
uint16_t limit;
uint32_t base;
} __attribute__((packed));
struct gdt_entry gdt[5];
void gdt_set_gate(int num, uint32_t base, uint32_t limit, uint8_t access, uint8_t gran) {
gdt[num].base_low = (base & 0xFFFF);
gdt[num].base_middle = (base >> 16) & 0xFF;
gdt[num].base_high = (base >> 24) & 0xFF;
gdt[num].limit_low = (limit & 0xFFFF);
gdt[num].granularity = ((limit >> 16) & 0x0F) | (gran & 0xF0);
gdt[num].access = access;
}
void gdt_install() {
struct gdt_ptr gp;
gp.limit = (sizeof(struct gdt_entry) * 5) - 1;
gp.base = (uint32_t)&gdt;
gdt_set_gate(0, 0, 0, 0, 0); // Null segment
gdt_set_gate(1, 0, 0xFFFFFFFF, 0x9A, 0xCF); // Code segment
gdt_set_gate(2, 0, 0xFFFFFFFF, 0x92, 0xCF); // Data segment
gdt_set_gate(3, 0, 0xFFFFFFFF, 0xFA, 0xCF); // User code
gdt_set_gate(4, 0, 0xFFFFFFFF, 0xF2, 0xCF); // User data
gdt_flush(&gp); // Assembly function to load GDT
}ARM Boot Process
1. ROM Bootloader (Primary Bootloader)
- Hardcoded in SoC ROM
- Minimal functionality
- Loads secondary bootloader from boot media (SD, eMMC, SPI)
2. SPL (Secondary Program Loader) / U-Boot
- Initializes DRAM controller
- Sets up clocks and power management
- Loads main bootloader or kernel
U-Boot Commands:
# Load kernel from SD card
fatload mmc 0:1 ${kernel_addr_r} zImage
# Load device tree
fatload mmc 0:1 ${fdt_addr_r} bcm2710-rpi-3-b.dtb
# Boot kernel
bootz ${kernel_addr_r} - ${fdt_addr_r}3. Device Tree (DTB)
- Hardware description format
- Describes hardware topology, addresses, interrupts
- Passed to kernel during boot
Device Tree Example (Simplified):
/dts-v1/;
/ {
compatible = "raspberrypi,3-model-b", "brcm,bcm2837";
model = "Raspberry Pi 3 Model B";
memory@0 {
device_type = "memory";
reg = <0x00000000 0x40000000>; // 1GB
};
cpus {
#address-cells = <1>;
#size-cells = <0>;
cpu@0 {
device_type = "cpu";
compatible = "arm,cortex-a53";
reg = <0>;
};
// ... more CPUs
};
soc {
uart0: serial@7e201000 {
compatible = "brcm,bcm2835-uart";
reg = <0x7e201000 0x1000>;
interrupts = <2 25>;
};
};
};4. Kernel Initialization
Linux Kernel Boot (ARM64):
1. Decompress kernel (if compressed)
2. Setup initial page tables
3. Enable MMU and caches
4. Parse device tree
5. Initialize memory subsystem
6. Mount initial ramdisk (initramfs)
7. Initialize drivers
8. Start init process (PID 1)Kernel Initialization Deep Dive
Early Boot Process:
// Simplified Linux kernel initialization (kernel/init/main.c)
asmlinkage __visible void __init start_kernel(void) {
char *command_line;
// 1. Setup architecture-specific components
setup_arch(&command_line);
// 2. Initialize memory management
mm_init();
// 3. Setup scheduler
sched_init();
// 4. Initialize IRQs and timers
init_IRQ();
init_timers();
// 5. Initialize console for early output
console_init();
// 6. Initialize rest of kernel subsystems
vfs_caches_init();
signals_init();
// 7. Rest of initialization (drivers, etc.)
rest_init();
}
static noinline void __init rest_init(void) {
// Create kernel threads
kernel_thread(kernel_init, NULL, CLONE_FS);
kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
// CPU idle loop
cpu_startup_entry(CPUHP_ONLINE);
}
static int __init kernel_init(void *unused) {
// Try to run init program
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found.");
}5. Process Management
Process Concept
A process is an instance of a program in execution. It represents the dynamic, active entity, as opposed to a program which is a passive, static collection of instructions.
Process Components:
- Program Code (Text Section): Executable instructions
- Program Counter: Current instruction position
- Processor Registers: Register contents
- Stack: Temporary data (function parameters, return addresses, local variables)
- Data Section: Global variables
- Heap: Dynamically allocated memory
Process vs Program:
Program: Passive entity (file on disk containing instructions)
Process: Active entity (program loaded in memory and executing)
Example:
- "notepad.exe" is a program
- When you run it, each window is a separate processProcess Memory Layout
High Memory (0xFFFFFFFF)
┌─────────────────────┐
│ Kernel Space │ ← OS kernel (1GB on 32-bit Linux)
├─────────────────────┤
│ Stack │ ← Grows downward
│ ↓ │ Function calls, local variables
│ │
│ (Unused) │
│ │
│ ↑ │
│ Heap │ ← Grows upward
├─────────────────────┤ Dynamic allocation (malloc/new)
│ BSS Segment │ ← Uninitialized data
├─────────────────────┤
│ Data Segment │ ← Initialized data
├─────────────────────┤
│ Text Segment │ ← Program code (read-only)
└─────────────────────┘
Low Memory (0x00000000)Example:
#include <stdlib.h>
int global_initialized = 42; // Data segment
int global_uninitialized; // BSS segment
const char *text_data = "Hello"; // Text/Read-only segment
void function() {
int stack_var = 10; // Stack
int *heap_var = malloc(sizeof(int)); // Heap
*heap_var = 20;
free(heap_var);
}Process Control Block (PCB)
The PCB (also called Task Control Block or TCB) is the kernel data structure representing a process.
PCB Contents:
struct task_struct { // Linux representation (simplified)
// 1. Process State
volatile long state; // Running, Ready, Waiting, etc.
// 2. Process ID
pid_t pid; // Process ID
pid_t tgid; // Thread group ID
struct task_struct *parent; // Parent process
// 3. CPU Scheduling Information
int prio; // Priority
int static_prio; // Static priority
int normal_prio; // Normal priority
unsigned int policy; // Scheduling policy
struct sched_entity se; // Scheduling entity
// 4. Memory Management
struct mm_struct *mm; // Memory descriptor
// 5. File Descriptors
struct files_struct *files; // Open file information
// 6. CPU Context
struct thread_struct thread; // CPU registers, PC, SP
// 7. Signal Handling
struct signal_struct *signal;
// 8. Process Times
u64 utime; // User mode time
u64 stime; // Kernel mode time
// 9. Process Credentials
uid_t uid, euid; // User ID, Effective UID
gid_t gid, egid; // Group ID, Effective GID
// 10. List Management
struct list_head tasks; // Process list
struct list_head sibling; // Sibling list
struct list_head children; // Children list
};Process States
A process transitions through various states during its lifetime.
Five-State Model:
┌─────────┐
│ New │ ← Process being created
└────┬────┘
│
↓
┌─────────┐ Scheduler ┌─────────────┐
┌───→│ Ready │ ← ─ ─ ─ ─ ─ ─ ─ ─ ┤ Running │
│ └────┬────┘ Dispatch └──────┬──────┘
│ │ │
│ └────────────────────────────────┘
│ │
│ │ I/O or
│ I/O Complete │ Event Wait
│ ┌─────────────────────────────────┘
│ │
│ ↓
│ ┌─────────┐ ┌─────────────┐
└────┤ Waiting │ │ Terminated │
└─────────┘ └─────────────┘State Descriptions:
- New: Process is being created; PCB allocated but not ready
- Ready: Process is waiting to be assigned to CPU
- Running: Instructions are being executed
- Waiting (Blocked): Process waiting for event (I/O completion, signal)
- Terminated (Zombie): Process finished execution; waiting for parent to read exit status
State Transitions Example (Linux):
// Process states in Linux (linux/sched.h)
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1 // Can be woken by signals
#define TASK_UNINTERRUPTIBLE 2 // Cannot be interrupted
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
// State transition example
void state_transition() {
set_current_state(TASK_INTERRUPTIBLE); // Ready → Waiting
schedule(); // Yield CPU
// After wake-up
// Waiting → Ready → Running (when scheduled)
}Process Creation
UNIX: fork() System Call
fork() creates a new process by duplicating the calling process.
Characteristics:
- Child process gets a copy of parent’s address space (Copy-on-Write)
- Child has unique PID
- fork() returns twice: 0 in child, child’s PID in parent
Copy-on-Write Optimization: fork() doesn’t immediately copy all memory! Instead, parent and child share the same pages until one tries to write. This makes fork() extremely fast and memory-efficient, even for large processes.
Fork Example:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid;
int x = 10;
printf("Before fork: x = %d\n", x);
pid = fork();
if (pid < 0) {
// Fork failed
fprintf(stderr, "Fork failed\n");
return 1;
} else if (pid == 0) {
// Child process
x = 20;
printf("Child: x = %d, PID = %d\n", x, getpid());
} else {
// Parent process
x = 30;
printf("Parent: x = %d, Child PID = %d\n", x, pid);
}
return 0;
}
/* Output:
Before fork: x = 10
Child: x = 20, PID = 1235
Parent: x = 30, Child PID = 1235
*/exec() Family
exec() replaces the current process image with a new program.
Common exec variants:
execl(): List of argumentsexecv(): Vector (array) of argumentsexecle(): List + environmentexecve(): Vector + environment
Fork + Exec Pattern:
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
// Child: Replace with "/bin/ls" program
char *args[] = {"/bin/ls", "-l", "/tmp", NULL};
execv("/bin/ls", args);
// If execv returns, it failed
perror("execv failed");
return 1;
} else {
// Parent: Wait for child to finish
int status;
waitpid(pid, &status, 0);
printf("Child exited with status %d\n", WEXITSTATUS(status));
}
return 0;
}Windows: CreateProcess()
Windows doesn’t use fork(); it creates processes differently.
#include <windows.h>
#include <stdio.h>
int main() {
STARTUPINFO si;
PROCESS_INFORMATION pi;
ZeroMemory(&si, sizeof(si));
si.cb = sizeof(si);
ZeroMemory(&pi, sizeof(pi));
// Create child process
if (!CreateProcess(
NULL, // Application name
"notepad.exe", // Command line
NULL, // Process attributes
NULL, // Thread attributes
FALSE, // Inherit handles
0, // Creation flags
NULL, // Environment
NULL, // Current directory
&si, // Startup info
&pi // Process info
)) {
printf("CreateProcess failed (%d)\n", GetLastError());
return 1;
}
// Wait for child
WaitForSingleObject(pi.hProcess, INFINITE);
// Close handles
CloseHandle(pi.hProcess);
CloseHandle(pi.hThread);
return 0;
}Process Termination
Normal Termination:
- Program executes last statement
- Calls
exit()system call - Returns from
main()
Abnormal Termination:
- Fatal error (division by zero, segmentation fault)
- Killed by another process (kill command)
- Parent terminates (orphan processes)
Exit Status:
#include <stdlib.h>
int main() {
// exit(0) - Success
// exit(1) - General error
// exit(127) - Command not found
if (error_occurred) {
exit(EXIT_FAILURE);
}
return EXIT_SUCCESS;
}Zombie and Orphan Processes:
Zombie Process:
- Process terminated but PCB still exists
- Waiting for parent to read exit status via
wait() - Shows as
<defunct>inpsoutput
Zombie Processes: If a parent never calls wait(), the child’s PCB remains allocated even after the child terminates. This wastes kernel resources. Long-running parent processes should always wait() for their children or ignore SIGCHLD to automatically reap zombies.
// Creating a zombie
#include <unistd.h>
int main() {
if (fork() == 0) {
// Child exits immediately
exit(0);
}
// Parent doesn't call wait()
sleep(60); // Child becomes zombie for 60 seconds
return 0;
}Orphan Process:
- Parent terminates before child
- Child is adopted by init (PID 1) or systemd
- Init/systemd periodically calls
wait()to reap orphans
Process Wait Example:
#include <sys/wait.h>
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
printf("Child process\n");
sleep(2);
exit(42); // Exit with status 42
} else {
int status;
pid_t child = wait(&status); // Wait for any child
if (WIFEXITED(status)) {
printf("Child %d exited with status %d\n",
child, WEXITSTATUS(status));
}
// Alternative: waitpid() for specific child
// waitpid(pid, &status, 0);
}
return 0;
}Context Switching
Context Switch: Saving the state of current process and loading the state of the next process.
Context Switch Steps:
1. Save current process state (registers, PC, SP) to PCB
2. Update PCB (state, timing information)
3. Move PCB to appropriate queue (ready, waiting)
4. Select next process (scheduling algorithm)
5. Update new process PCB (state = RUNNING)
6. Restore new process context from PCB
7. Switch memory management (page tables)
8. Resume execution of new processContext Switch Overhead - A Hidden Cost:
- Direct Cost: Time to save/restore registers (~microseconds)
- Indirect Cost: Cache flush → huge performance hit! Modern CPUs with large caches can lose 1-10% performance per context switch
- TLB Flush: Virtual memory translation caches invalidated
- Pipeline Flush: CPU instruction pipeline emptied
Practical Impact: High context switch rates (>1000/sec) cause significant throughput degradation even though each individual switch is “fast”
Minimizing Context Switches:
- Use threads instead of processes (shared address space)
- Increase time slices (but hurts responsiveness)
- CPU affinity (keep process on same CPU)
- Reduce I/O operations (batch I/O requests)
Linux Context Switch Implementation (Simplified):
// arch/x86/include/asm/switch_to.h
#define switch_to(prev, next, last) do { \
/* Save previous task's context */ \
asm volatile( \
"pushfl\n\t" /* Save flags */ \
"pushl %%ebp\n\t" /* Save base pointer */\
"movl %%esp,%[prev_sp]\n\t" /* Save stack ptr */ \
"movl %[next_sp],%%esp\n\t" /* Load next stack*/\
"movl $1f,%[prev_ip]\n\t" /* Save return IP */ \
"pushl %[next_ip]\n\t" /* Push next IP */ \
"jmp __switch_to\n\t" /* Context switch */ \
"1:\t" \
"popl %%ebp\n\t" /* Restore base ptr */ \
"popfl\n" /* Restore flags */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip) \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
[prev] "a" (prev), \
[next] "d" (next) \
: "memory", "cc" \
); \
} while (0)Process Hierarchies
UNIX Process Tree:
init (PID 1) or systemd
├─ sshd
│ └─ bash (login shell)
│ └─ vim
├─ cron
│ └─ backup_script
├─ Apache httpd
│ ├─ httpd (worker 1)
│ ├─ httpd (worker 2)
│ └─ httpd (worker N)
└─ X Window System
└─ window_manager
├─ terminal_emulator
└─ browserViewing Process Tree (Linux):
$ pstree
init─┬─acpid
├─cron
├─dbus-daemon
├─dhclient
├─login───bash───pstree
├─rsyslogd───3*[{rsyslogd}]
├─sshd───sshd───bash
└─udevd───2*[udevd]
$ ps -ef # Full process list
$ ps aux # BSD-style format6. Thread Management and Concurrency
Thread Concept
A thread is the smallest unit of execution within a process. Unlike processes which have separate address spaces, threads share the same memory space and resources, making them lightweight and efficient.
Key Differences: Process vs Thread
| Aspect | Process | Thread |
|---|---|---|
| Memory Space | Separate address space | Shared address space |
| Resource Overhead | High (memory, file descriptors) | Low (shares with process) |
| Creation Time | Slow (milliseconds) | Fast (microseconds) |
| Context Switch | Expensive (page tables, cache misses) | Cheaper (same page tables) |
| Communication | IPC mechanisms needed | Direct memory access |
| Isolation | High (protected) | Low (shared memory) |
Thread Components:
Each thread has its own:
├── Program Counter (PC)
├── Stack (local variables, function calls)
├── CPU Registers
├── Thread-local storage
└── Stack pointer
Shared by all threads in process:
├── Process memory (heap, code, globals)
├── File descriptors
├── Signal handlers
└── Current working directoryUser-Level vs Kernel-Level Threads
User-Level Threads
- Managed by thread library (not OS)
- No kernel involvement
- Fast context switching
- Cannot utilize multiprocessors
- If one thread blocks, entire process blocked
// User-level thread example (POSIX Threads)
#include <pthread.h>
#include <stdio.h>
void* thread_function(void *arg) {
printf("Thread ID: %ld\n", (long)pthread_self());
return NULL;
}
int main() {
pthread_t thread;
// Create user-level thread
pthread_create(&thread, NULL, thread_function, NULL);
// Wait for thread completion
pthread_join(thread, NULL);
return 0;
}Kernel-Level Threads
- Managed by OS kernel
- Full kernel support
- Can run on multiple processors
- Slower context switching (syscall overhead)
- Better for I/O-bound operations
Thread Models
1. One-to-One Model
User Thread 1 ↔ Kernel Thread 1
User Thread 2 ↔ Kernel Thread 2
User Thread 3 ↔ Kernel Thread 3
Advantages:
- Full parallelism
- Blocking doesn't stop other threads
- OS sees all threads
Disadvantages:
- High kernel overhead
- Limited number of threads
- Resource consumption2. Many-to-One Model
User Thread 1 ┐
User Thread 2 ├→ Kernel Thread 1
User Thread 3 ┘
Advantages:
- Low overhead
- Fast context switching
- No syscalls needed
Disadvantages:
- No true parallelism
- One blocking thread blocks all
- Cannot use multiprocessors3. Many-to-Many Model
User Thread 1 ┐ ┌→ Kernel Thread 1
User Thread 2 ├─→ ├→ Kernel Thread 2
User Thread 3 ┤ └→ Kernel Thread 3
User Thread 4 ┘
Best of both worlds:
- Multiple kernel threads
- Efficient thread management
- True parallelism with low overheadThread Synchronization
Critical Section: Code segment that accesses shared resources
Mutual Exclusion Problem: Ensuring only one thread enters critical section at a time
Race Condition Danger: Without synchronization, the statement shared_counter++ (which consists of 3 operations: READ → INCREMENT → WRITE) can interleave between threads, causing lost updates. For example:
Thread 1: READ (10) → INCREMENT (11)
Thread 2: READ (10) → INCREMENT (11) ← Oops! Both read 10
Thread 1: WRITE (11)
Thread 2: WRITE (11) ← Expected 12, got 11!Solution 1: Mutex (Mutual Exclusion Lock)
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
int shared_counter = 0;
void* increment_counter(void *arg) {
for (int i = 0; i < 1000000; i++) {
pthread_mutex_lock(&mutex);
shared_counter++; // Critical section
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main() {
pthread_t threads[2];
pthread_create(&threads[0], NULL, increment_counter, NULL);
pthread_create(&threads[1], NULL, increment_counter, NULL);
pthread_join(threads[0], NULL);
pthread_join(threads[1], NULL);
printf("Counter value: %d (expected: 2000000)\n", shared_counter);
pthread_mutex_destroy(&mutex);
return 0;
}Solution 2: Semaphore
#include <semaphore.h>
#include <pthread.h>
#include <stdio.h>
sem_t semaphore;
int shared_resource = 0;
void* worker(void *arg) {
for (int i = 0; i < 5; i++) {
sem_wait(&semaphore); // Acquire (P operation)
printf("Thread %ld accessing resource\n",
(long)pthread_self());
shared_resource++;
sem_post(&semaphore); // Release (V operation)
}
return NULL;
}
int main() {
sem_init(&semaphore, 0, 1); // Binary semaphore
pthread_t threads[3];
for (int i = 0; i < 3; i++) {
pthread_create(&threads[i], NULL, worker, NULL);
}
for (int i = 0; i < 3; i++) {
pthread_join(threads[i], NULL);
}
sem_destroy(&semaphore);
return 0;
}Solution 3: Condition Variables
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t condition = PTHREAD_COND_INITIALIZER;
int ready = 0;
void* waiter_thread(void *arg) {
pthread_mutex_lock(&mutex);
while (!ready) { // Always use while, not if
printf("Waiting...\n");
pthread_cond_wait(&condition, &mutex);
}
printf("Proceeding!\n");
pthread_mutex_unlock(&mutex);
return NULL;
}
void* signaler_thread(void *arg) {
sleep(2);
pthread_mutex_lock(&mutex);
ready = 1;
pthread_cond_signal(&condition); // Wake one waiter
pthread_mutex_unlock(&mutex);
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, waiter_thread, NULL);
pthread_create(&t2, NULL, signaler_thread, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}Producer-Consumer Problem
Scenario: Producer generates data, Consumer uses data, bounded buffer between them
Classic Synchronization Problem: The Producer-Consumer problem demonstrates critical synchronization concepts:
- Mutual Exclusion: Only one thread accesses buffer at a time
- Resource Counting: Track empty/full slots
- Deadlock Avoidance: Proper ordering of semaphore operations
- Real-world Applications: Message queues, thread pools, I/O buffering
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <semaphore.h>
#define BUFFER_SIZE 5
int buffer[BUFFER_SIZE];
int in = 0, out = 0;
sem_t empty; // Counts empty slots
sem_t full; // Counts full slots
pthread_mutex_t mutex;
void* producer(void *arg) {
for (int i = 0; i < 10; i++) {
sem_wait(&empty); // Wait for empty slot
pthread_mutex_lock(&mutex);
buffer[in] = i * 10;
printf("Producer: Added %d at %d\n", buffer[in], in);
in = (in + 1) % BUFFER_SIZE;
pthread_mutex_unlock(&mutex);
sem_post(&full); // Signal full slot
}
return NULL;
}
void* consumer(void *arg) {
for (int i = 0; i < 10; i++) {
sem_wait(&full); // Wait for full slot
pthread_mutex_lock(&mutex);
int value = buffer[out];
printf("Consumer: Consumed %d from %d\n", value, out);
out = (out + 1) % BUFFER_SIZE;
pthread_mutex_unlock(&mutex);
sem_post(&empty); // Signal empty slot
}
return NULL;
}
int main() {
pthread_t prod, cons;
sem_init(&empty, 0, BUFFER_SIZE);
sem_init(&full, 0, 0);
pthread_mutex_init(&mutex, NULL);
pthread_create(&prod, NULL, producer, NULL);
pthread_create(&cons, NULL, consumer, NULL);
pthread_join(prod, NULL);
pthread_join(cons, NULL);
sem_destroy(&empty);
sem_destroy(&full);
pthread_mutex_destroy(&mutex);
return 0;
}7. CPU Scheduling Algorithms
Scheduling Criteria
Maximize:
- CPU Utilization: Keep CPU as busy as possible (40-90% is reasonable)
- Throughput: Number of processes completed per unit time
Minimize:
- Turnaround Time: Time from submission to completion
- Waiting Time: Time spent in ready queue
- Response Time: Time from submission to first response
Scheduling Algorithms (Complete Analysis)
1. First-Come-First-Served (FCFS)
Algorithm: Process executes for entire duration, no preemption
// FCFS Scheduler Implementation
struct process {
int pid;
int arrival_time;
int burst_time;
int start_time;
int end_time;
};
void fcfs_schedule(struct process procs[], int n) {
int current_time = 0;
double total_turnaround = 0, total_wait = 0;
for (int i = 0; i < n; i++) {
procs[i].start_time = current_time;
procs[i].end_time = current_time + procs[i].burst_time;
current_time = procs[i].end_time;
int turnaround = procs[i].end_time - procs[i].arrival_time;
int wait = procs[i].start_time - procs[i].arrival_time;
total_turnaround += turnaround;
total_wait += wait;
printf("P%d: Wait=%d, Turnaround=%d\n",
procs[i].pid, wait, turnaround);
}
printf("Average Wait Time: %.2f\n", total_wait / n);
printf("Average Turnaround: %.2f\n", total_turnaround / n);
}
/*
Example: Processes with burst times [24, 3, 3]
FCFS: P1_____________________ P2__ P3__
0 24 27 30
Waiting times: P1=0, P2=24, P3=27
Average wait: 17ms
*/Convoy Effect Problem: Short processes become stuck behind long ones in the queue, causing massive average waiting time degradation. In this example, P2 and P3 must wait 24 and 27 time units respectively just for P1 to finish - this is highly inefficient! FCFS is rarely used in practice due to this critical limitation.
2. Shortest Job First (SJF)
Non-preemptive: Each process runs completely
void sjf_schedule(struct process procs[], int n) {
// Sort by burst time (ascending)
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (procs[j].burst_time > procs[j+1].burst_time) {
struct process temp = procs[j];
procs[j] = procs[j+1];
procs[j+1] = temp;
}
}
}
fcfs_schedule(procs, n); // Then apply FCFS on sorted list
}
/*
Example: Processes [24, 3, 3]
Sorted: [3, 3, 24]
Gantt Chart:
P2_ P3_ P1_____________________
0 3 6 30
Average wait: (0 + 3 + 6) / 3 = 3ms (vs 17ms for FCFS!)
*/SJF Optimization: Notice the dramatic improvement! Average waiting time dropped from 17ms (FCFS) to just 3ms (SJF) - an 82% reduction! SJF is provably optimal for minimizing average waiting time when all processes arrive simultaneously.
Starvation Risk: Long processes may never execute if short processes keep arriving. Not practical in real systems without aging mechanisms.
Preemptive SJF (Shortest Remaining Time First - SRTF)
void srtf_schedule(struct process procs[], int n) {
int remaining[n];
for (int i = 0; i < n; i++) {
remaining[i] = procs[i].burst_time;
}
int time = 0;
int total_processes = n;
while (total_processes > 0) {
// Find process with shortest remaining time
int min_index = -1;
int min_remaining = INT_MAX;
for (int i = 0; i < n; i++) {
if (remaining[i] > 0 && remaining[i] < min_remaining &&
procs[i].arrival_time <= time) {
min_remaining = remaining[i];
min_index = i;
}
}
if (min_index == -1) {
time++;
continue;
}
// Execute for 1 time unit
remaining[min_index]--;
time++;
if (remaining[min_index] == 0) {
total_processes--;
}
}
}3. Round Robin (RR) Scheduling
Overview: Round Robin is a preemptive scheduling algorithm that assigns a fixed time slice (quantum) to each process in the ready queue. It’s designed specifically for time-sharing systems where fairness and responsiveness are critical.
Key Concept: Time Quantum (Time Slice) - Fixed time period allocated to each process
Time Quantum Selection is Critical:
- Too small (1-10ms): Excessive context switching overhead → CPU thrashing
- Too large (100ms+): Behaves like FCFS → poor response time
- Sweet spot: 80% of CPU bursts should be shorter than the quantum
- Linux default: ~100ms (configurable via
sched_latency_ns)
Characteristics:
- Preemptive: CPU is preempted after time quantum expires
- Fair: All processes get equal CPU time in rotation
- FIFO Queue: Processes are arranged in circular queue
- No Starvation: Every process eventually gets CPU time
Round Robin Algorithm Flow
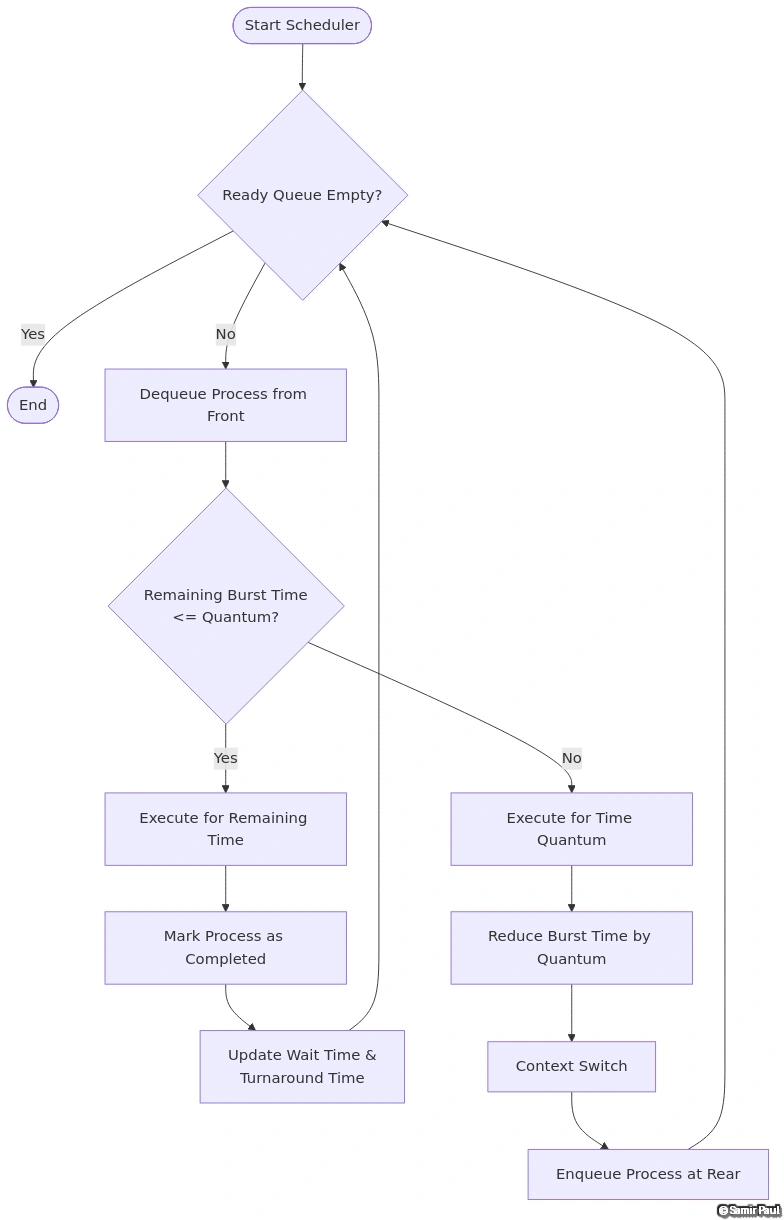
Figure 1: Round Robin scheduling algorithm flowchart illustrating the process dequeue, execution, and re-queue mechanism with time quantum management.
Process State Transitions in Round Robin
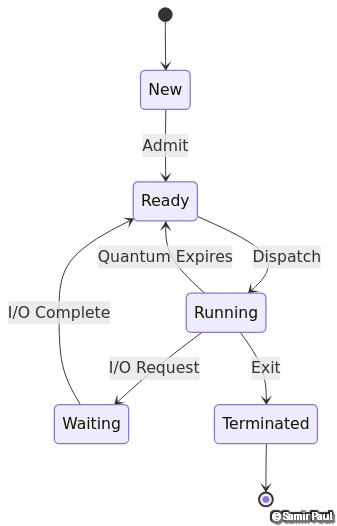
Figure 2: Process state transitions in Round Robin scheduling with time quantum expiration triggering preemption and re-queueing of processes.
Circular Queue Mechanism

Figure 3: Circular ready queue mechanism showing how processes are dispatched to CPU and re-enqueued when time quantum expires before completion.
Detailed Implementation with Comments
#include <stdio.h>
#include <stdlib.h>
// Process structure with all necessary attributes
typedef struct {
int pid; // Process ID
int arrival_time; // When process arrives in ready queue
int burst_time; // Total CPU time needed
int remaining_time; // Remaining CPU time
int completion_time; // When process completes
int waiting_time; // Total time spent waiting
int turnaround_time; // completion_time - arrival_time
int response_time; // First time process gets CPU - arrival_time
int first_response; // Flag to track first CPU allocation
} Process;
// Circular queue for ready processes
typedef struct {
Process *processes[100];
int front;
int rear;
int count;
} ReadyQueue;
// Initialize queue
void init_queue(ReadyQueue *q) {
q->front = 0;
q->rear = -1;
q->count = 0;
}
// Check if queue is empty
int is_empty(ReadyQueue *q) {
return q->count == 0;
}
// Enqueue process at rear
void enqueue(ReadyQueue *q, Process *p) {
q->rear = (q->rear + 1) % 100; // Circular increment
q->processes[q->rear] = p;
q->count++;
}
// Dequeue process from front
Process* dequeue(ReadyQueue *q) {
if (is_empty(q)) return NULL;
Process *p = q->processes[q->front];
q->front = (q->front + 1) % 100; // Circular increment
q->count--;
return p;
}
/**
* Round Robin Scheduling Algorithm
*
* Parameters:
* processes: Array of processes to schedule
* n: Number of processes
* time_quantum: Fixed time slice for each process
*
* Algorithm Steps:
* 1. Create ready queue and add all processes
* 2. While queue is not empty:
* a. Dequeue process from front
* b. If remaining_time <= quantum: Execute completely
* c. Else: Execute for quantum, then re-enqueue
* 3. Calculate metrics (waiting time, turnaround time)
*/
void round_robin_schedule(Process processes[], int n, int time_quantum) {
ReadyQueue ready_queue;
init_queue(&ready_queue);
// Add all processes to ready queue (assume all arrive at time 0)
for (int i = 0; i < n; i++) {
processes[i].remaining_time = processes[i].burst_time;
processes[i].first_response = 0; // Not yet responded
enqueue(&ready_queue, &processes[i]);
}
int current_time = 0;
int completed = 0;
printf("\n=== Round Robin Scheduling (Quantum = %d) ===\n\n", time_quantum);
printf("Time\tProcess\tAction\n");
printf("----\t-------\t------\n");
// Main scheduling loop
while (!is_empty(&ready_queue)) {
// Dequeue next process from front of ready queue
Process *current = dequeue(&ready_queue);
// Record response time (first time process gets CPU)
if (current->first_response == 0) {
current->response_time = current_time - current->arrival_time;
current->first_response = 1;
}
// Determine execution time for this time slice
int execution_time;
if (current->remaining_time <= time_quantum) {
// Process will complete within this quantum
execution_time = current->remaining_time;
current->remaining_time = 0;
printf("%d\tP%d\tExecute for %dms (COMPLETE)\n",
current_time, current->pid, execution_time);
current_time += execution_time;
current->completion_time = current_time;
current->turnaround_time = current->completion_time - current->arrival_time;
current->waiting_time = current->turnaround_time - current->burst_time;
completed++;
} else {
// Process needs more time - will be preempted
execution_time = time_quantum;
current->remaining_time -= time_quantum;
printf("%d\tP%d\tExecute for %dms (PREEMPT, %dms remaining)\n",
current_time, current->pid, execution_time, current->remaining_time);
current_time += execution_time;
// Context switch: Re-enqueue at rear of ready queue
enqueue(&ready_queue, current);
}
}
printf("\n=== Process Completion Summary ===\n");
printf("PID\tBurst\tCompletion\tTurnaround\tWaiting\tResponse\n");
printf("---\t-----\t----------\t----------\t-------\t--------\n");
float avg_turnaround = 0, avg_waiting = 0, avg_response = 0;
for (int i = 0; i < n; i++) {
printf("P%d\t%d\t%d\t\t%d\t\t%d\t%d\n",
processes[i].pid,
processes[i].burst_time,
processes[i].completion_time,
processes[i].turnaround_time,
processes[i].waiting_time,
processes[i].response_time);
avg_turnaround += processes[i].turnaround_time;
avg_waiting += processes[i].waiting_time;
avg_response += processes[i].response_time;
}
printf("\n=== Performance Metrics ===\n");
printf("Average Turnaround Time: %.2f ms\n", avg_turnaround / n);
printf("Average Waiting Time: %.2f ms\n", avg_waiting / n);
printf("Average Response Time: %.2f ms\n", avg_response / n);
printf("Number of Context Switches: %d\n", current_time / time_quantum);
}Gantt Chart Example
Example Problem: Schedule 3 processes with Round Robin (Quantum = 4ms)
| Process | Burst Time |
|---|---|
| P1 | 24 ms |
| P2 | 3 ms |
| P3 | 3 ms |
Execution Timeline:
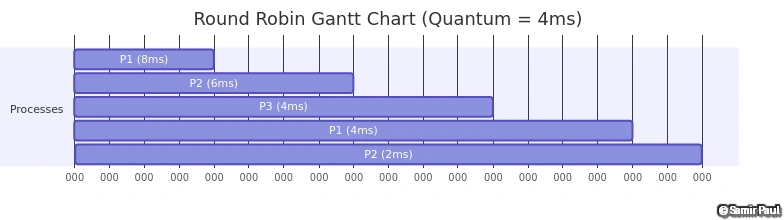
Figure 4: Gantt chart visualization of Round Robin scheduling with quantum=4ms, demonstrating process interleaving and completion times.
Step-by-Step Execution:
Time 0-4: P1 executes (24-4=20ms remaining) → Re-queue
Time 4-7: P2 executes (3-3=0ms) → Complete ✓
Time 7-10: P3 executes (3-3=0ms) → Complete ✓
Time 10-14: P1 executes (20-4=16ms remaining) → Re-queue
Time 14-18: P1 executes (16-4=12ms remaining) → Re-queue
Time 18-22: P1 executes (12-4=8ms remaining) → Re-queue
Time 22-26: P1 executes (8-4=4ms remaining) → Re-queue
Time 26-30: P1 executes (4-4=0ms) → Complete ✓Metrics Calculation:
- P1: Turnaround = 30-0 = 30ms, Waiting = 30-24 = 6ms, Response = 0ms
- P2: Turnaround = 7-0 = 7ms, Waiting = 7-3 = 4ms, Response = 4ms
- P3: Turnaround = 10-0 = 10ms, Waiting = 10-3 = 7ms, Response = 7ms
Impact of Time Quantum
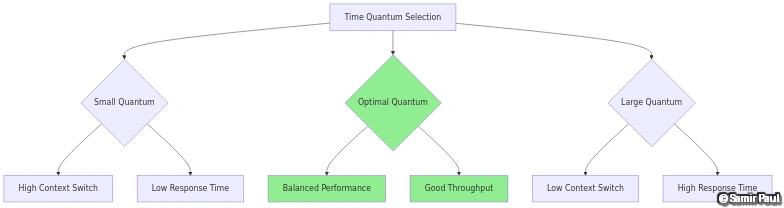
Figure 5: Comparative analysis of time quantum values demonstrating the balance between response time, context switch overhead, and throughput in Round Robin scheduling.
Quantum Selection Guidelines:
- Rule of Thumb: 80% of CPU bursts should be shorter than quantum
- Typical Values: 10-100 milliseconds
- Linux Default: ~100ms (adjustable via
sched_latency_ns) - Context Switch Cost: Usually 1-10 microseconds
Quantum Comparison Example
// Demonstrate effect of different quantum values
void compare_quantum_values() {
Process procs[] = {
{1, 0, 53, 0, 0, 0, 0, 0, 0},
{2, 0, 17, 0, 0, 0, 0, 0, 0},
{3, 0, 68, 0, 0, 0, 0, 0, 0},
{4, 0, 24, 0, 0, 0, 0, 0, 0}
};
int quantum_values[] = {1, 5, 10, 20, 100};
printf("Quantum\tAvg Wait\tAvg Response\tContext Switches\n");
printf("-------\t--------\t------------\t----------------\n");
for (int i = 0; i < 5; i++) {
Process test_procs[4];
memcpy(test_procs, procs, sizeof(procs));
int quantum = quantum_values[i];
round_robin_schedule(test_procs, 4, quantum);
// Results would show:
// Q=1: High wait time, excellent response, ~162 switches
// Q=5: Good wait time, good response, ~32 switches
// Q=10: Good wait time, good response, ~16 switches
// Q=20: Moderate wait, moderate response, ~8 switches
// Q=100: High wait time, poor response, ~2 switches (like FCFS)
}
}Advantages and Disadvantages
Advantages: ✓ Fair CPU allocation: Every process gets equal time ✓ No starvation: All processes eventually execute ✓ Good response time: Especially for interactive systems ✓ Simple to implement: Easy to understand and code ✓ Preemptive: Can handle time-sharing systems
Disadvantages: ✗ Context switch overhead: More switches = more overhead ✗ Higher average turnaround: Compared to SJF ✗ Performance depends on quantum: Hard to choose optimal value ✗ Not ideal for batch systems: Throughput may suffer ✗ Penalizes CPU-bound processes: Long processes wait repeatedly
Real-World Usage
Linux Time-Sharing Scheduler (Pre-CFS):
// Simplified Linux Round Robin concept (older versions)
#define DEF_TIMESLICE (100 * HZ / 1000) // 100ms default
void schedule() {
struct task_struct *next;
// Select next task from run queue
next = pick_next_task_rr();
if (next->time_slice == 0) {
// Quantum expired - move to expired array
next->time_slice = DEF_TIMESLICE;
enqueue_task_expired(next);
} else {
// Continue with current process
context_switch(prev, next);
}
}Modern Applications:
- Interactive Systems: Desktop environments, mobile OS
- Time-Sharing Systems: Multi-user Unix/Linux systems
- Real-Time Systems: Combined with priority scheduling
- Virtual Machines: CPU time sharing among VMs
Practice Problems
Problem 1: Four processes arrive at time 0 with burst times P1=10, P2=1, P3=2, P4=1. Calculate average waiting time for quantum=1.
Solution:
Time 0-1: P1 → Re-queue (9 remaining)
Time 1-2: P2 → Complete
Time 2-4: P3 → Complete
Time 4-5: P4 → Complete
Time 5-6: P1 → Re-queue (8 remaining)
... continues ...
Time 12-13: P1 → Complete
Waiting Times: P1=(13-10)=3, P2=(2-1)=1, P3=(4-2)=2, P4=(5-1)=4
Average = (3+1+2+4)/4 = 2.5msProblem 2: Why is quantum=1 inefficient even though it provides best response time?
Answer: Context switch overhead dominates. If context switch takes 0.1ms and quantum is 1ms, system spends ~9% of time just switching contexts rather than executing processes.
4. Priority Scheduling
void priority_schedule(struct process procs[], int n) {
// Sort by priority (lower number = higher priority)
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (procs[j].priority > procs[j+1].priority) {
struct process temp = procs[j];
procs[j] = procs[j+1];
procs[j+1] = temp;
}
}
}
// Apply FCFS on priority-sorted list
fcfs_schedule(procs, n);
}
/*
Priority Inversion Problem:
- Low-priority task holds resource needed by high-priority task
- High-priority task waits for low-priority task
- Solution: Priority inheritance (boost lock holder's priority)
*/5. Linux CFS (Completely Fair Scheduler)
Concept: Each process gets fair share of CPU based on nice value
// Simplified CFS concept
typedef struct {
long vruntime; // Virtual runtime
long weight; // Priority weight
} cfs_task;
void cfs_update_runtime(cfs_task *task, long delta_exec) {
// Nice value determines weight:
// weight = 1024 / (1.25 ^ nice_value)
task->vruntime += (delta_exec * 1024) / task->weight;
}
/*
Red-Black Tree maintains tasks by vruntime:
P2 (vruntime=10)
/ \
P1 P3
(v=5) (v=15)
Selection: Always pick leftmost (smallest vruntime)
This ensures fairness while minimizing context switches
*/Context Switching Overhead
Costs of Context Switching:
Direct Cost: ~1-10 microseconds
- Save/restore registers
- Switch address space (if different process)
Indirect Cost: ~milliseconds
- Cache misses (cold cache)
- TLB misses
- Increased memory bandwidth
Example:
- Context switch: 10 μs
- CPU stall for cache miss: 100 ns
- 100+ misses per switch = 10 μs + 10 μs = 20 μs visible cost8. Synchronization Primitives
Race Conditions and Critical Sections
Race Condition: Multiple threads/processes access shared data, result depends on timing
// Classic race condition example
int counter = 0;
// Without synchronization (WRONG!)
void increment_unsafe() {
counter++; // Not atomic! Translates to:
// 1. Load counter into register
// 2. Increment register
// 3. Store register back to counter
}
// With synchronization (CORRECT)
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void increment_safe() {
pthread_mutex_lock(&lock);
counter++; // Now atomic
pthread_mutex_unlock(&lock);
}
/*
Without locks, with 1000 increments per thread (2 threads):
Expected: 2000
Actual: Random (often 1200, 1500, etc.)
Reason: Interleaved execution:
Thread 1: Load (0) Increment (1) ...
Thread 2: Load (0) Increment (1) Store (1) ...
Thread 1: ... Store (1)
Result: Both stored 1, lost an increment
*/Semaphores Detailed
Binary Semaphore (value: 0 or 1)
#include <semaphore.h>
sem_t mutex;
sem_init(&mutex, 0, 1); // Initial value = 1
// Usage
sem_wait(&mutex); // P() operation - decrement
// Critical section
sem_post(&mutex); // V() operation - increment
Counting Semaphore (value: 0 to N)
sem_t available_resources;
sem_init(&available_resources, 0, 5); // 5 resources available
void* worker(void *arg) {
sem_wait(&available_resources); // Acquire resource
// Use resource
printf("Using resource\n");
sleep(1);
sem_post(&available_resources); // Release resource
return NULL;
}
/*
Example with 3 threads and 2 resources:
Thread 1: sem_wait() → success (available=1)
Thread 2: sem_wait() → success (available=0)
Thread 3: sem_wait() → blocks (available=0)
Thread 1: sem_post() → (available=1), wakes Thread 3
*/Readers-Writers Problem
Requirement: Multiple readers can access resource simultaneously, but writers need exclusive access
#include <pthread.h>
#include <semaphore.h>
#include <stdio.h>
int read_count = 0;
int shared_data = 0;
pthread_mutex_t read_count_lock = PTHREAD_MUTEX_INITIALIZER;
sem_t write_lock;
void* reader(void *arg) {
while (1) {
// Entry section
pthread_mutex_lock(&read_count_lock);
read_count++;
if (read_count == 1) {
sem_wait(&write_lock); // First reader blocks writers
}
pthread_mutex_unlock(&read_count_lock);
// Critical section (read)
printf("Reader %ld: %d\n", (long)pthread_self(), shared_data);
// Exit section
pthread_mutex_lock(&read_count_lock);
read_count--;
if (read_count == 0) {
sem_post(&write_lock); // Last reader allows writers
}
pthread_mutex_unlock(&read_count_lock);
}
return NULL;
}
void* writer(void *arg) {
while (1) {
sem_wait(&write_lock); // Exclusive access
// Critical section (write)
shared_data++;
printf("Writer %ld: Updated to %d\n",
(long)pthread_self(), shared_data);
sem_post(&write_lock);
}
return NULL;
}Atomic Operations and Memory Barriers
#include <stdatomic.h>
#include <stdint.h>
// Atomic variable
atomic_int counter = ATOMIC_VAR_INIT(0);
void increment_atomic() {
atomic_fetch_add(&counter, 1); // Guaranteed atomic
}
// Memory barriers
void process_data(int *data) {
*data = 42;
atomic_thread_fence(memory_order_release); // Release barrier
// All writes before this point visible to other threads
}
void read_data(int *data) {
atomic_thread_fence(memory_order_acquire); // Acquire barrier
// All reads after this point see changes made before
int value = *data;
}
/*
Memory Ordering Options:
- memory_order_relaxed: No synchronization
- memory_order_release: Release semantics
- memory_order_acquire: Acquire semantics
- memory_order_seq_cst: Sequential consistency (default, most expensive)
*/Lock-Free Data Structures
#include <stdatomic.h>
// Lock-free counter
typedef struct {
atomic_long value;
} LockFreeCounter;
void increment(LockFreeCounter *counter) {
atomic_fetch_add(&counter->value, 1);
}
// Lock-free stack using Compare-And-Swap (CAS)
typedef struct Node {
int data;
struct Node *next;
} Node;
typedef struct {
atomic_ptr_t top;
} LockFreeStack;
void push(LockFreeStack *stack, int value) {
Node *new_node = malloc(sizeof(Node));
new_node->data = value;
Node *old_top;
do {
old_top = atomic_load(&stack->top);
new_node->next = old_top;
} while (!atomic_compare_exchange_strong(&stack->top,
&old_top,
new_node));
}
/*
CAS (Compare-And-Swap):
- Atomically compare value at address with expected
- If equal, store new value
- Return whether operation succeeded
- No explicit locks needed
- Wait-free for many scenarios
*/9. Deadlock Handling
9.1 Understanding Deadlocks
A deadlock is a situation where a set of processes are blocked because each process is holding a resource and waiting for another resource held by another process in the set.
Coffman Conditions (Necessary Conditions for Deadlock)
For a deadlock to occur, all four conditions must hold simultaneously:
- Mutual Exclusion: At least one resource must be held in a non-shareable mode
- Hold and Wait: A process must be holding at least one resource and waiting for additional resources
- No Preemption: Resources cannot be forcibly removed from processes
- Circular Wait: A circular chain of processes exists where each process holds resources needed by the next
/*
* Example: Deadlock Scenario
* Process P1 holds Resource R1, needs R2
* Process P2 holds Resource R2, needs R1
*/
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
pthread_mutex_t resource1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t resource2 = PTHREAD_MUTEX_INITIALIZER;
void* process1(void *arg) {
printf("P1: Acquiring Resource 1...\n");
pthread_mutex_lock(&resource1);
printf("P1: Got Resource 1\n");
sleep(1); // Simulate some work
printf("P1: Acquiring Resource 2...\n");
pthread_mutex_lock(&resource2); // DEADLOCK! P2 holds R2
printf("P1: Got Resource 2\n");
// Critical section
printf("P1: Working with both resources\n");
pthread_mutex_unlock(&resource2);
pthread_mutex_unlock(&resource1);
return NULL;
}
void* process2(void *arg) {
printf("P2: Acquiring Resource 2...\n");
pthread_mutex_lock(&resource2);
printf("P2: Got Resource 2\n");
sleep(1); // Simulate some work
printf("P2: Acquiring Resource 1...\n");
pthread_mutex_lock(&resource1); // DEADLOCK! P1 holds R1
printf("P2: Got Resource 1\n");
// Critical section
printf("P2: Working with both resources\n");
pthread_mutex_unlock(&resource1);
pthread_mutex_unlock(&resource2);
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, process1, NULL);
pthread_create(&t2, NULL, process2, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}9.2 Deadlock Prevention
Strategy: Ensure at least one Coffman condition cannot hold.
9.2.1 Breaking Mutual Exclusion
- Make resources shareable (not always possible)
- Use read-write locks for read-heavy workloads
#include <pthread.h>
pthread_rwlock_t shared_resource = PTHREAD_RWLOCK_INITIALIZER;
void* reader(void *arg) {
pthread_rwlock_rdlock(&shared_resource); // Multiple readers OK
// Read data
printf("Reader %ld reading\n", (long)pthread_self());
pthread_rwlock_unlock(&shared_resource);
return NULL;
}
void* writer(void *arg) {
pthread_rwlock_wrlock(&shared_resource); // Exclusive write
// Write data
printf("Writer %ld writing\n", (long)pthread_self());
pthread_rwlock_unlock(&shared_resource);
return NULL;
}9.2.2 Breaking Hold and Wait
- Require processes to request all resources at once
#include <pthread.h>
#include <stdbool.h>
typedef struct {
pthread_mutex_t *locks;
int num_locks;
pthread_mutex_t allocation_lock;
} ResourceManager;
// Acquire all resources atomically
bool acquire_all_resources(ResourceManager *rm, int *resource_ids, int count) {
pthread_mutex_lock(&rm->allocation_lock);
// Try to acquire all locks
for (int i = 0; i < count; i++) {
if (pthread_mutex_trylock(&rm->locks[resource_ids[i]]) != 0) {
// Failed to acquire, release all acquired locks
for (int j = 0; j < i; j++) {
pthread_mutex_unlock(&rm->locks[resource_ids[j]]);
}
pthread_mutex_unlock(&rm->allocation_lock);
return false;
}
}
pthread_mutex_unlock(&rm->allocation_lock);
return true;
}9.2.3 Breaking No Preemption
- Allow resources to be preempted (forcibly removed)
- Save process state and restore later
// Conceptual example - actual implementation is OS-specific
void preemptable_resource_request(Process *p, Resource *r) {
if (!try_acquire(r)) {
// Release all currently held resources
release_all_resources(p);
// Save process state
save_state(p);
// Add to waiting queue
add_to_queue(p, r);
// Context switch to another process
schedule_next_process();
}
}9.2.4 Breaking Circular Wait
- Resource Ordering: Impose total ordering on all resources
/*
* Deadlock Prevention: Resource Ordering
* Always acquire resources in increasing order of their IDs
*/
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t resource1 = PTHREAD_MUTEX_INITIALIZER; // ID: 1
pthread_mutex_t resource2 = PTHREAD_MUTEX_INITIALIZER; // ID: 2
void* safe_process1(void *arg) {
// Always acquire in order: R1 before R2
pthread_mutex_lock(&resource1);
printf("P1: Got Resource 1\n");
pthread_mutex_lock(&resource2);
printf("P1: Got Resource 2\n");
// Critical section - NO DEADLOCK!
printf("P1: Working safely\n");
pthread_mutex_unlock(&resource2);
pthread_mutex_unlock(&resource1);
return NULL;
}
void* safe_process2(void *arg) {
// Also acquire in order: R1 before R2
pthread_mutex_lock(&resource1);
printf("P2: Got Resource 1\n");
pthread_mutex_lock(&resource2);
printf("P2: Got Resource 2\n");
// Critical section
printf("P2: Working safely\n");
pthread_mutex_unlock(&resource2);
pthread_mutex_unlock(&resource1);
return NULL;
}9.3 Deadlock Avoidance
Strategy: Make informed decisions about resource allocation to ensure the system never enters an unsafe state.
9.3.1 Safe State
A state is safe if there exists a sequence of all processes <P1, P2, …, Pn> such that for each Pi, the resources that Pi can still request can be satisfied by:
- Currently available resources
- Resources held by all Pj where j < i
9.3.2 Banker’s Algorithm
Developed by Edsger Dijkstra, simulates allocation to test for safe state.
#include <stdio.h>
#include <stdbool.h>
#include <string.h>
#define NUM_PROCESSES 5
#define NUM_RESOURCES 3
typedef struct {
int available[NUM_RESOURCES]; // Available resources
int maximum[NUM_PROCESSES][NUM_RESOURCES]; // Max demand
int allocation[NUM_PROCESSES][NUM_RESOURCES]; // Currently allocated
int need[NUM_PROCESSES][NUM_RESOURCES]; // Remaining need
} BankersState;
// Calculate need matrix: Need = Maximum - Allocation
void calculate_need(BankersState *state) {
for (int i = 0; i < NUM_PROCESSES; i++) {
for (int j = 0; j < NUM_RESOURCES; j++) {
state->need[i][j] = state->maximum[i][j] - state->allocation[i][j];
}
}
}
// Check if system is in safe state
bool is_safe_state(BankersState *state) {
int work[NUM_RESOURCES];
bool finish[NUM_PROCESSES] = {false};
int safe_sequence[NUM_PROCESSES];
int count = 0;
// Initialize work = available
memcpy(work, state->available, sizeof(work));
// Find a process that can finish
while (count < NUM_PROCESSES) {
bool found = false;
for (int i = 0; i < NUM_PROCESSES; i++) {
if (!finish[i]) {
// Check if process i can finish
bool can_finish = true;
for (int j = 0; j < NUM_RESOURCES; j++) {
if (state->need[i][j] > work[j]) {
can_finish = false;
break;
}
}
if (can_finish) {
// Process i can finish
// Add its allocated resources back to work
for (int j = 0; j < NUM_RESOURCES; j++) {
work[j] += state->allocation[i][j];
}
safe_sequence[count++] = i;
finish[i] = true;
found = true;
}
}
}
if (!found) {
// No process could finish - not in safe state
printf("System is NOT in safe state!\n");
return false;
}
}
// Found safe sequence
printf("System is in SAFE state.\nSafe sequence: ");
for (int i = 0; i < NUM_PROCESSES; i++) {
printf("P%d ", safe_sequence[i]);
}
printf("\n");
return true;
}
// Request resources using Banker's Algorithm
bool request_resources(BankersState *state, int process_id, int request[]) {
printf("\nProcess P%d requesting: ", process_id);
for (int i = 0; i < NUM_RESOURCES; i++) {
printf("%d ", request[i]);
}
printf("\n");
// Check if request <= need
for (int i = 0; i < NUM_RESOURCES; i++) {
if (request[i] > state->need[process_id][i]) {
printf("Error: Process exceeded its maximum claim!\n");
return false;
}
}
// Check if request <= available
for (int i = 0; i < NUM_RESOURCES; i++) {
if (request[i] > state->available[i]) {
printf("Process must wait - resources not available\n");
return false;
}
}
// Pretend to allocate resources
BankersState test_state = *state;
for (int i = 0; i < NUM_RESOURCES; i++) {
test_state.available[i] -= request[i];
test_state.allocation[process_id][i] += request[i];
test_state.need[process_id][i] -= request[i];
}
// Check if resulting state is safe
if (is_safe_state(&test_state)) {
// Safe - commit the allocation
*state = test_state;
printf("Request GRANTED\n");
return true;
} else {
// Unsafe - rollback
printf("Request DENIED (would lead to unsafe state)\n");
return false;
}
}
// Example usage
int main() {
BankersState state = {
.available = {3, 3, 2},
.maximum = {
{7, 5, 3}, // P0
{3, 2, 2}, // P1
{9, 0, 2}, // P2
{2, 2, 2}, // P3
{4, 3, 3} // P4
},
.allocation = {
{0, 1, 0}, // P0
{2, 0, 0}, // P1
{3, 0, 2}, // P2
{2, 1, 1}, // P3
{0, 0, 2} // P4
}
};
calculate_need(&state);
printf("Initial state:\n");
printf("Available: ");
for (int i = 0; i < NUM_RESOURCES; i++) {
printf("%d ", state.available[i]);
}
printf("\n\n");
is_safe_state(&state);
// P1 requests (1, 0, 2)
int request1[] = {1, 0, 2};
request_resources(&state, 1, request1);
return 0;
}
/*
Output Analysis:
- Algorithm checks if granting request leads to safe state
- If safe: Grant request
- If unsafe: Process must wait
- Prevents deadlock by conservative allocation
*/9.4 Deadlock Detection
Strategy: Allow deadlocks to occur, detect them, and recover.
9.4.1 Resource Allocation Graph (RAG)
#include <stdio.h>
#include <stdbool.h>
#define MAX_PROCESSES 10
#define MAX_RESOURCES 10
typedef struct {
int num_processes;
int num_resources;
// Adjacency matrix: graph[i][j] = 1 if edge from i to j
int graph[MAX_PROCESSES + MAX_RESOURCES][MAX_PROCESSES + MAX_RESOURCES];
} RAG;
// Detect cycle using DFS
bool has_cycle_util(RAG *rag, int v, bool visited[], bool rec_stack[]) {
if (!visited[v]) {
visited[v] = true;
rec_stack[v] = true;
int total_nodes = rag->num_processes + rag->num_resources;
for (int i = 0; i < total_nodes; i++) {
if (rag->graph[v][i]) {
if (!visited[i] && has_cycle_util(rag, i, visited, rec_stack)) {
return true;
} else if (rec_stack[i]) {
return true;
}
}
}
}
rec_stack[v] = false;
return false;
}
bool detect_deadlock(RAG *rag) {
int total_nodes = rag->num_processes + rag->num_resources;
bool visited[MAX_PROCESSES + MAX_RESOURCES] = {false};
bool rec_stack[MAX_PROCESSES + MAX_RESOURCES] = {false};
for (int i = 0; i < total_nodes; i++) {
if (has_cycle_util(rag, i, visited, rec_stack)) {
printf("DEADLOCK DETECTED! Cycle found in RAG\n");
return true;
}
}
printf("No deadlock detected\n");
return false;
}9.4.2 Wait-For Graph (for single-instance resources)
/*
* Wait-For Graph: Variant of RAG for single-instance resources
* Process Pi waits for Pj if Pi is waiting for a resource held by Pj
* Deadlock exists iff WFG contains a cycle
*/
typedef struct {
int num_processes;
bool wait_for[MAX_PROCESSES][MAX_PROCESSES]; // wait_for[i][j] = true if Pi waits for Pj
} WaitForGraph;
// Detect cycle in wait-for graph
bool detect_deadlock_wfg(WaitForGraph *wfg) {
for (int start = 0; start < wfg->num_processes; start++) {
bool visited[MAX_PROCESSES] = {false};
int current = start;
while (true) {
if (visited[current]) {
if (current == start) {
printf("Deadlock: Cycle detected starting at P%d\n", start);
return true;
}
break;
}
visited[current] = true;
// Find next process in potential cycle
bool found_next = false;
for (int next = 0; next < wfg->num_processes; next++) {
if (wfg->wait_for[current][next]) {
current = next;
found_next = true;
break;
}
}
if (!found_next) break;
}
}
return false;
}9.5 Deadlock Recovery
Once deadlock is detected, recovery strategies include:
9.5.1 Process Termination
/*
* Recovery Strategy 1: Abort processes to break cycle
*/
// Abort all deadlocked processes
void abort_all_deadlocked() {
// Terminate all processes in deadlock
// Restart them from beginning
// Simple but expensive
}
// Abort processes one at a time
void abort_one_at_a_time(int *deadlocked_processes, int count) {
// Selection criteria (choose minimum cost):
// 1. Process priority
// 2. How long process has computed
// 3. Resources used
// 4. Resources needed to complete
// 5. Number of processes that need to be terminated
int min_cost_process = select_min_cost_process(deadlocked_processes, count);
terminate_process(min_cost_process);
// Check if deadlock still exists
if (detect_deadlock()) {
abort_one_at_a_time(deadlocked_processes, count - 1);
}
}9.5.2 Resource Preemption
/*
* Recovery Strategy 2: Preempt resources from processes
*/
typedef struct {
int process_id;
int resources_held[MAX_RESOURCES];
int execution_time;
int priority;
} ProcessInfo;
// Select victim process for preemption
int select_victim(ProcessInfo *processes, int count) {
int victim = 0;
int min_cost = INT_MAX;
for (int i = 0; i < count; i++) {
// Cost factors:
// - Number of resources held
// - Execution time (prefer younger processes)
// - Priority (prefer low priority)
int resource_count = 0;
for (int j = 0; j < MAX_RESOURCES; j++) {
resource_count += processes[i].resources_held[j];
}
int cost = resource_count * 10 +
processes[i].execution_time -
processes[i].priority * 5;
if (cost < min_cost) {
min_cost = cost;
victim = i;
}
}
return victim;
}
// Rollback victim to safe state
void rollback_and_preempt(int victim_id) {
// 1. Save state (checkpoint)
save_checkpoint(victim_id);
// 2. Preempt resources
release_all_resources(victim_id);
// 3. Rollback to previous checkpoint
restore_checkpoint(victim_id);
// To avoid starvation: use aging or limits on preemption count
}9.6 Practical Deadlock Handling in Modern Systems
Linux Approach
/*
* Linux uses multiple strategies:
* 1. Timeouts on lock acquisition (trylock with timeout)
* 2. Lock ordering conventions
* 3. Lockdep: Runtime deadlock detector (detects potential deadlocks)
*/
#include <pthread.h>
#include <errno.h>
#include <time.h>
// Trylock with timeout
bool acquire_with_timeout(pthread_mutex_t *lock, int timeout_ms) {
struct timespec timeout;
clock_gettime(CLOCK_REALTIME, &timeout);
timeout.tv_sec += timeout_ms / 1000;
timeout.tv_nsec += (timeout_ms % 1000) * 1000000;
if (timeout.tv_nsec >= 1000000000) {
timeout.tv_sec++;
timeout.tv_nsec -= 1000000000;
}
int result = pthread_mutex_timedlock(lock, &timeout);
if (result == ETIMEDOUT) {
printf("Lock acquisition timeout - potential deadlock\n");
return false;
}
return (result == 0);
}Database Systems
/*
* Database Deadlock Handling:
* - Wait-Die: Older transaction waits, younger dies
* - Wound-Wait: Older transaction wounds (preempts) younger
*/
typedef struct {
int transaction_id;
long timestamp; // Transaction start time
} Transaction;
// Wait-Die Scheme
void wait_die(Transaction *requester, Transaction *holder) {
if (requester->timestamp < holder->timestamp) {
// Older transaction waits
wait_for_resource(requester);
} else {
// Younger transaction dies (aborts)
abort_transaction(requester);
restart_transaction(requester);
}
}
// Wound-Wait Scheme
void wound_wait(Transaction *requester, Transaction *holder) {
if (requester->timestamp < holder->timestamp) {
// Older wounds younger (preempts)
abort_transaction(holder);
grant_resource(requester);
} else {
// Younger waits
wait_for_resource(requester);
}
}9.7 Comparison of Deadlock Handling Methods
| Method | Prevention | Avoidance | Detection + Recovery |
|---|---|---|---|
| Approach | Prevent one Coffman condition | Don’t enter unsafe state | Allow deadlock, then fix |
| Resource Utilization | Low (conservative) | Medium | High (optimistic) |
| Runtime Overhead | Low | Medium (safety check) | Low (periodic detection) |
| Implementation | Easiest | Complex (Banker’s) | Medium |
| Used In | Simple systems | Real-time systems | Databases, OSes |
Key Takeaways
- Deadlock requires all 4 Coffman conditions simultaneously
- Prevention: Break at least one condition (most common: resource ordering)
- Avoidance: Use Banker’s algorithm to stay in safe state
- Detection: Use RAG or WFG to find cycles
- Recovery: Terminate processes or preempt resources
- Real systems use hybrid approaches: Prevention + detection with timeouts
10. Memory Management
10.1 Memory Management Basics
Memory management is responsible for:
- Keeping track of which parts of memory are in use
- Allocating and deallocating memory for processes
- Managing the swap between main memory and disk
- Protecting memory space between processes
Memory Hierarchy
Registers (CPU) <-- Fastest, smallest, most expensive
↓
Cache (L1, L2, L3)
↓
Main Memory (RAM)
↓
Secondary Storage (SSD)
↓
Tertiary Storage (HDD) <-- Slowest, largest, cheapest10.2 Address Binding
Address binding is the process of mapping logical addresses to physical addresses.
/*
* Types of Addresses:
* 1. Symbolic address: Variable names in source code (e.g., "x")
* 2. Relocatable address: Relative address from program start (e.g., "14 bytes from start")
* 3. Absolute address: Physical memory address (e.g., "0x400014")
*/
// Example: Compile-time binding (rarely used)
// Address is fixed at compile time
int x = 10; // Compiler assigns absolute address 0x1000
// Run-time binding (most common in modern systems)
// Address determined when process loads
int *ptr = malloc(sizeof(int)); // Address assigned at runtime
Binding Times
- Compile time: If memory location known a priori (obsolete)
- Load time: Addresses generated when program loaded
- Execution time: Addresses can change during execution (requires hardware support - MMU)
10.3 Logical vs Physical Address Space
/*
* Logical Address (Virtual Address):
* - Generated by CPU
* - Used by user programs
* - Address space from 0 to MAX
*
* Physical Address:
* - Actual location in memory
* - Seen by memory unit
* - Mapped by MMU (Memory Management Unit)
*/
// Example: MMU Translation
typedef struct {
uint32_t logical_address;
uint32_t physical_address;
uint32_t base_register; // Relocation register
uint32_t limit_register; // Size of process memory
} AddressTranslation;
uint32_t mmu_translate(AddressTranslation *at, uint32_t logical_addr) {
// Check if address is within bounds
if (logical_addr >= at->limit_register) {
printf("ERROR: Segmentation fault - address out of bounds\n");
return 0xFFFFFFFF; // Error indicator
}
// Simple relocation: Physical = Logical + Base
at->physical_address = logical_addr + at->base_register;
printf("Logical: 0x%X → Physical: 0x%X\n",
logical_addr, at->physical_address);
return at->physical_address;
}
// Example usage
int main() {
AddressTranslation at = {
.base_register = 0x10000, // Process starts at 0x10000
.limit_register = 0x5000 // Process size is 0x5000 bytes
};
// Translate logical address 0x1234
mmu_translate(&at, 0x1234); // → Physical: 0x11234
// Attempt to access beyond limit
mmu_translate(&at, 0x6000); // → ERROR!
return 0;
}10.4 Contiguous Memory Allocation
Fixed Partitioning (Static)
#define NUM_PARTITIONS 4
typedef struct {
uint32_t start_address;
uint32_t size;
bool is_allocated;
int process_id;
} Partition;
Partition partitions[NUM_PARTITIONS] = {
{0x00000, 0x10000, false, -1}, // 64KB
{0x10000, 0x20000, false, -1}, // 128KB
{0x30000, 0x30000, false, -1}, // 192KB
{0x60000, 0x40000, false, -1} // 256KB
};
/*
* Problems with fixed partitioning:
* 1. Internal fragmentation: Unused space within partition
* 2. Limited number of processes
* 3. Inflexible partition sizes
*/Dynamic Partitioning (Variable)
typedef struct MemoryBlock {
uint32_t start_address;
uint32_t size;
bool is_free;
int process_id;
struct MemoryBlock *next;
} MemoryBlock;
// Global memory list
MemoryBlock *memory_list = NULL;
void init_memory(uint32_t total_size) {
memory_list = malloc(sizeof(MemoryBlock));
memory_list->start_address = 0;
memory_list->size = total_size;
memory_list->is_free = true;
memory_list->process_id = -1;
memory_list->next = NULL;
}
// Display current memory state
void display_memory() {
MemoryBlock *current = memory_list;
printf("\n=== Memory Map ===\n");
while (current != NULL) {
printf("[0x%06X - 0x%06X] Size: %6d bytes | ",
current->start_address,
current->start_address + current->size - 1,
current->size);
if (current->is_free) {
printf("FREE\n");
} else {
printf("Process %d\n", current->process_id);
}
current = current->next;
}
printf("==================\n\n");
}10.5 Memory Allocation Algorithms
10.5.1 First Fit
Allocate the first hole that is large enough.
/*
* First Fit: Fast, but may leave small unusable holes at beginning
*/
bool first_fit(int process_id, uint32_t required_size) {
MemoryBlock *current = memory_list;
while (current != NULL) {
if (current->is_free && current->size >= required_size) {
// Found suitable block
if (current->size > required_size) {
// Split the block
MemoryBlock *new_block = malloc(sizeof(MemoryBlock));
new_block->start_address = current->start_address + required_size;
new_block->size = current->size - required_size;
new_block->is_free = true;
new_block->process_id = -1;
new_block->next = current->next;
current->next = new_block;
current->size = required_size;
}
current->is_free = false;
current->process_id = process_id;
printf("First Fit: Allocated %d bytes for Process %d at 0x%X\n",
required_size, process_id, current->start_address);
return true;
}
current = current->next;
}
printf("First Fit: Allocation failed for Process %d\n", process_id);
return false;
}10.5.2 Best Fit
Allocate the smallest hole that is large enough.
/*
* Best Fit: Minimizes wasted space but slower (searches entire list)
* May create many tiny unusable holes
*/
bool best_fit(int process_id, uint32_t required_size) {
MemoryBlock *current = memory_list;
MemoryBlock *best_block = NULL;
uint32_t min_leftover = UINT32_MAX;
// Search for best fitting block
while (current != NULL) {
if (current->is_free && current->size >= required_size) {
uint32_t leftover = current->size - required_size;
if (leftover < min_leftover) {
min_leftover = leftover;
best_block = current;
}
}
current = current->next;
}
if (best_block == NULL) {
printf("Best Fit: Allocation failed for Process %d\n", process_id);
return false;
}
// Allocate the best block
if (best_block->size > required_size) {
MemoryBlock *new_block = malloc(sizeof(MemoryBlock));
new_block->start_address = best_block->start_address + required_size;
new_block->size = best_block->size - required_size;
new_block->is_free = true;
new_block->process_id = -1;
new_block->next = best_block->next;
best_block->next = new_block;
best_block->size = required_size;
}
best_block->is_free = false;
best_block->process_id = process_id;
printf("Best Fit: Allocated %d bytes for Process %d at 0x%X (leftover: %d)\n",
required_size, process_id, best_block->start_address, min_leftover);
return true;
}10.5.3 Worst Fit
Allocate the largest hole.
/*
* Worst Fit: Leaves largest leftover (may be more usable)
* Slowest (searches entire list)
*/
bool worst_fit(int process_id, uint32_t required_size) {
MemoryBlock *current = memory_list;
MemoryBlock *worst_block = NULL;
uint32_t max_size = 0;
// Search for largest block
while (current != NULL) {
if (current->is_free && current->size >= required_size) {
if (current->size > max_size) {
max_size = current->size;
worst_block = current;
}
}
current = current->next;
}
if (worst_block == NULL) {
printf("Worst Fit: Allocation failed for Process %d\n", process_id);
return false;
}
// Allocate the worst (largest) block
if (worst_block->size > required_size) {
MemoryBlock *new_block = malloc(sizeof(MemoryBlock));
new_block->start_address = worst_block->start_address + required_size;
new_block->size = worst_block->size - required_size;
new_block->is_free = true;
new_block->process_id = -1;
new_block->next = worst_block->next;
worst_block->next = new_block;
worst_block->size = required_size;
}
worst_block->is_free = false;
worst_block->process_id = process_id;
printf("Worst Fit: Allocated %d bytes for Process %d at 0x%X\n",
required_size, process_id, worst_block->start_address);
return true;
}10.5.4 Next Fit
Similar to First Fit, but starts search from last allocation point.
/*
* Next Fit: Variant of First Fit that continues from last allocation
* Distributes holes more evenly across memory
*/
MemoryBlock *last_allocated = NULL;
bool next_fit(int process_id, uint32_t required_size) {
if (last_allocated == NULL) {
last_allocated = memory_list;
}
MemoryBlock *current = last_allocated;
MemoryBlock *start = current;
// Search from last allocation point
do {
if (current->is_free && current->size >= required_size) {
// Found suitable block
if (current->size > required_size) {
MemoryBlock *new_block = malloc(sizeof(MemoryBlock));
new_block->start_address = current->start_address + required_size;
new_block->size = current->size - required_size;
new_block->is_free = true;
new_block->process_id = -1;
new_block->next = current->next;
current->next = new_block;
current->size = required_size;
}
current->is_free = false;
current->process_id = process_id;
last_allocated = current->next ? current->next : memory_list;
printf("Next Fit: Allocated %d bytes for Process %d at 0x%X\n",
required_size, process_id, current->start_address);
return true;
}
current = current->next ? current->next : memory_list;
} while (current != start);
printf("Next Fit: Allocation failed for Process %d\n", process_id);
return false;
}10.6 Fragmentation
External Fragmentation
Total memory space exists to satisfy request, but it’s not contiguous.
/*
* Example of External Fragmentation:
*
* Before:
* [P1: 10KB] [FREE: 5KB] [P2: 10KB] [FREE: 5KB] [P3: 10KB]
*
* Request: 8KB process
* Problem: Total free = 10KB, but largest contiguous = 5KB
*
* Solution: Compaction
*/
void compact_memory() {
MemoryBlock *current = memory_list;
uint32_t compact_address = 0;
printf("Starting memory compaction...\n");
// Move all allocated blocks to beginning
while (current != NULL) {
if (!current->is_free) {
if (current->start_address != compact_address) {
printf("Moving Process %d from 0x%X to 0x%X\n",
current->process_id,
current->start_address,
compact_address);
// In real system, copy memory content here
current->start_address = compact_address;
}
compact_address += current->size;
}
current = current->next;
}
// Merge all free blocks at the end
current = memory_list;
MemoryBlock *prev = NULL;
uint32_t total_free = 0;
while (current != NULL) {
if (current->is_free) {
total_free += current->size;
MemoryBlock *temp = current;
current = current->next;
if (prev != NULL) {
prev->next = current;
}
free(temp);
} else {
prev = current;
current = current->next;
}
}
// Create single large free block
if (total_free > 0) {
MemoryBlock *free_block = malloc(sizeof(MemoryBlock));
free_block->start_address = compact_address;
free_block->size = total_free;
free_block->is_free = true;
free_block->process_id = -1;
free_block->next = NULL;
if (prev != NULL) {
prev->next = free_block;
} else {
memory_list = free_block;
}
}
printf("Compaction complete. Free space: %d bytes at 0x%X\n",
total_free, compact_address);
}Internal Fragmentation
Allocated memory is larger than requested, wasted space within allocated block.
/*
* Example: Internal Fragmentation
* Process requests 1 byte, system allocates minimum block of 64 bytes
* Wasted: 63 bytes (internal fragmentation)
*/
#define MIN_ALLOCATION_SIZE 64
void* allocate_with_internal_frag(size_t requested_size) {
size_t actual_size = requested_size;
if (actual_size < MIN_ALLOCATION_SIZE) {
actual_size = MIN_ALLOCATION_SIZE;
printf("Internal Fragmentation: Requested %zu, allocated %zu, wasted %zu bytes\n",
requested_size, actual_size, actual_size - requested_size);
}
return malloc(actual_size);
}10.7 Buddy System Allocator
Efficient compromise between fixed and variable partitioning.
#include <math.h>
#define MAX_ORDER 10 // 2^10 = 1024 units
#define MEMORY_SIZE (1 << MAX_ORDER)
typedef struct BuddyBlock {
uint32_t address;
int order; // Block size = 2^order
bool is_free;
struct BuddyBlock *next;
} BuddyBlock;
BuddyBlock *free_lists[MAX_ORDER + 1];
void init_buddy_system() {
for (int i = 0; i <= MAX_ORDER; i++) {
free_lists[i] = NULL;
}
// Initially one large free block
free_lists[MAX_ORDER] = malloc(sizeof(BuddyBlock));
free_lists[MAX_ORDER]->address = 0;
free_lists[MAX_ORDER]->order = MAX_ORDER;
free_lists[MAX_ORDER]->is_free = true;
free_lists[MAX_ORDER]->next = NULL;
}
// Calculate buddy address
uint32_t get_buddy_address(uint32_t address, int order) {
return address ^ (1 << order);
}
void* buddy_alloc(size_t size) {
// Find minimum order that fits request
int order = 0;
while ((1 << order) < size) {
order++;
}
if (order > MAX_ORDER) {
printf("Buddy: Request too large\n");
return NULL;
}
// Find available block
int current_order = order;
while (current_order <= MAX_ORDER && free_lists[current_order] == NULL) {
current_order++;
}
if (current_order > MAX_ORDER) {
printf("Buddy: No memory available\n");
return NULL;
}
// Remove block from free list
BuddyBlock *block = free_lists[current_order];
free_lists[current_order] = block->next;
// Split block until we reach desired order
while (current_order > order) {
current_order--;
// Create buddy block
BuddyBlock *buddy = malloc(sizeof(BuddyBlock));
buddy->address = block->address + (1 << current_order);
buddy->order = current_order;
buddy->is_free = true;
buddy->next = free_lists[current_order];
free_lists[current_order] = buddy;
printf("Buddy: Split block at 0x%X (order %d) into 0x%X and 0x%X\n",
block->address, current_order + 1,
block->address, buddy->address);
}
block->order = order;
block->is_free = false;
printf("Buddy: Allocated %d bytes (2^%d) at 0x%X\n",
1 << order, order, block->address);
return (void *)(uintptr_t)block->address;
}
void buddy_free(void *ptr, int order) {
uint32_t address = (uint32_t)(uintptr_t)ptr;
printf("Buddy: Freeing block at 0x%X (order %d)\n", address, order);
// Try to coalesce with buddy
while (order < MAX_ORDER) {
uint32_t buddy_addr = get_buddy_address(address, order);
// Search for free buddy
BuddyBlock *prev = NULL;
BuddyBlock *current = free_lists[order];
bool found_buddy = false;
while (current != NULL) {
if (current->address == buddy_addr && current->is_free) {
// Found free buddy - coalesce
if (prev != NULL) {
prev->next = current->next;
} else {
free_lists[order] = current->next;
}
free(current);
found_buddy = true;
printf("Buddy: Coalescing 0x%X and 0x%X into order %d\n",
address, buddy_addr, order + 1);
// Move to parent block
address = address < buddy_addr ? address : buddy_addr;
order++;
break;
}
prev = current;
current = current->next;
}
if (!found_buddy) {
break;
}
}
// Add to free list
BuddyBlock *new_block = malloc(sizeof(BuddyBlock));
new_block->address = address;
new_block->order = order;
new_block->is_free = true;
new_block->next = free_lists[order];
free_lists[order] = new_block;
}
/*
* Buddy System Advantages:
* - Fast allocation/deallocation (O(log n))
* - Automatic coalescing
* - Reduces external fragmentation
*
* Disadvantages:
* - Internal fragmentation (power of 2 sizes)
* - Complex implementation
*/10.8 Slab Allocator (Linux Kernel)
Efficient allocator for kernel objects.
/*
* Slab Allocator: Cache objects for quick reuse
* Used in Linux kernel for allocating kernel structures
*/
#define SLAB_SIZE 4096 // One page
#define OBJECTS_PER_SLAB 64
typedef struct SlabObject {
bool is_free;
void *data;
struct SlabObject *next;
} SlabObject;
typedef struct Slab {
void *memory; // Actual slab memory
SlabObject *free_list; // Free objects in this slab
int free_count;
struct Slab *next;
} Slab;
typedef struct SlabCache {
size_t object_size;
Slab *partial_slabs; // Slabs with some free objects
Slab *full_slabs; // Slabs with no free objects
Slab *empty_slabs; // Slabs with all objects free
void (*constructor)(void *); // Object constructor
void (*destructor)(void *); // Object destructor
} SlabCache;
SlabCache* slab_cache_create(size_t object_size,
void (*ctor)(void *),
void (*dtor)(void *)) {
SlabCache *cache = malloc(sizeof(SlabCache));
cache->object_size = object_size;
cache->partial_slabs = NULL;
cache->full_slabs = NULL;
cache->empty_slabs = NULL;
cache->constructor = ctor;
cache->destructor = dtor;
printf("Slab: Created cache for %zu-byte objects\n", object_size);
return cache;
}
Slab* slab_create(size_t object_size) {
Slab *slab = malloc(sizeof(Slab));
slab->memory = malloc(SLAB_SIZE);
slab->free_count = OBJECTS_PER_SLAB;
slab->next = NULL;
// Initialize free list
slab->free_list = NULL;
for (int i = 0; i < OBJECTS_PER_SLAB; i++) {
SlabObject *obj = malloc(sizeof(SlabObject));
obj->is_free = true;
obj->data = (char *)slab->memory + (i * object_size);
obj->next = slab->free_list;
slab->free_list = obj;
}
printf("Slab: Created new slab with %d objects\n", OBJECTS_PER_SLAB);
return slab;
}
void* slab_alloc(SlabCache *cache) {
Slab *slab = cache->partial_slabs;
// No partial slabs, try empty or create new
if (slab == NULL) {
slab = cache->empty_slabs;
if (slab != NULL) {
// Move from empty to partial
cache->empty_slabs = slab->next;
slab->next = cache->partial_slabs;
cache->partial_slabs = slab;
} else {
// Create new slab
slab = slab_create(cache->object_size);
slab->next = cache->partial_slabs;
cache->partial_slabs = slab;
}
}
// Allocate object from slab
SlabObject *obj = slab->free_list;
slab->free_list = obj->next;
obj->is_free = false;
slab->free_count--;
// Call constructor if present
if (cache->constructor) {
cache->constructor(obj->data);
}
// Move to full list if no more free objects
if (slab->free_count == 0) {
cache->partial_slabs = slab->next;
slab->next = cache->full_slabs;
cache->full_slabs = slab;
}
printf("Slab: Allocated object at %p (free in slab: %d)\n",
obj->data, slab->free_count);
return obj->data;
}
void slab_free(SlabCache *cache, void *ptr) {
// Find which slab contains this object
// (In real implementation, use more efficient lookup)
// Simplified: assume we know the slab
// In reality, calculate from ptr and SLAB_SIZE
printf("Slab: Freed object at %p\n", ptr);
// Call destructor if present
if (cache->destructor) {
cache->destructor(ptr);
}
// Return object to slab's free list
// Move slab between lists as needed
}
/*
* Slab Allocator Benefits:
* 1. No repeated initialization overhead
* 2. Cache-friendly (objects close in memory)
* 3. Minimal fragmentation
* 4. Fast allocation (pre-allocated slabs)
*
* Used in Linux for:
* - task_struct (process descriptors)
* - file descriptors
* - inode caching
* - dentry caching
*/10.9 Memory Allocation Comparison
| Algorithm | Speed | Fragmentation | Use Case |
|---|---|---|---|
| First Fit | Fast | Medium external | General purpose |
| Best Fit | Slow | High external (tiny holes) | Memory constrained |
| Worst Fit | Slow | Low external | Large requests |
| Next Fit | Fast | Medium external | Balanced distribution |
| Buddy System | Medium | Medium internal | Kernel memory |
| Slab Allocator | Very Fast | Low | Kernel objects |
10.10 Practical Example: Complete Memory Manager
// Complete example demonstrating multiple allocation strategies
int main() {
printf("=== Memory Management Demo ===\n\n");
// Initialize memory: 1MB
init_memory(0x100000);
printf("--- First Fit Allocation ---\n");
first_fit(1, 0x10000); // P1: 64KB
first_fit(2, 0x20000); // P2: 128KB
first_fit(3, 0x15000); // P3: 84KB
display_memory();
printf("--- Deallocation ---\n");
// Free P2 (creates hole in middle)
MemoryBlock *current = memory_list;
while (current != NULL) {
if (current->process_id == 2) {
current->is_free = true;
current->process_id = -1;
printf("Freed Process 2\n");
break;
}
current = current->next;
}
display_memory();
printf("--- Compaction ---\n");
compact_memory();
display_memory();
printf("--- Buddy System Demo ---\n");
init_buddy_system();
void *p1 = buddy_alloc(100); // Will allocate 128 (2^7)
void *p2 = buddy_alloc(200); // Will allocate 256 (2^8)
void *p3 = buddy_alloc(50); // Will allocate 64 (2^6)
buddy_free(p2, 8); // Free and coalesce
buddy_free(p1, 7);
buddy_free(p3, 6);
return 0;
}Key Takeaways
- Memory management handles allocation, deallocation, and protection
- First Fit is fastest, Best Fit minimizes waste, Worst Fit leaves larger holes
- External fragmentation: Free memory is scattered (solution: compaction)
- Internal fragmentation: Allocated block larger than needed
- Buddy System: Power-of-2 allocation with fast coalescing
- Slab Allocator: Pre-allocates objects for fast reuse (Linux kernel)
- Modern systems use hybrid approaches combining multiple strategies
11. Virtual Memory Systems
11.1 Virtual Memory Overview
Virtual Memory separates logical memory from physical memory, allowing:
- Larger address space than physical RAM
- Efficient use of physical memory
- Process isolation and protection
- Memory sharing between processes
- Simplified programming model
/*
* Key Benefits:
* 1. Programs larger than physical RAM can run
* 2. Each process has own address space (0 to MAX)
* 3. Protection: process cannot access others' memory
* 4. Shared libraries occupy physical memory once
*/
// Example: 32-bit system
#define VIRTUAL_ADDRESS_SPACE 0xFFFFFFFF // 4GB per process
// Even if physical RAM is only 1GB!
11.2 Demand Paging
Demand paging loads pages into memory only when needed.
/*
* Demand Paging Process:
* 1. CPU generates virtual address
* 2. MMU looks up page table
* 3. If page present: translate to physical address
* 4. If page not present: PAGE FAULT
* a. OS handles page fault
* b. Load page from disk
* c. Update page table
* d. Restart instruction
*/
#include <stdint.h>
#include <stdbool.h>
#define PAGE_SIZE 4096 // 4KB pages
#define NUM_PAGES 1024 // 1024 pages = 4MB address space
#define NUM_FRAMES 256 // 256 frames = 1MB physical RAM
typedef struct {
bool present; // Is page in memory?
uint32_t frame; // Physical frame number
bool dirty; // Modified since loaded?
bool accessed; // Recently accessed? (for LRU)
uint32_t protection; // Read/Write/Execute bits
} PageTableEntry;
typedef struct {
PageTableEntry entries[NUM_PAGES];
} PageTable;
// Simulate page fault handler
void handle_page_fault(PageTable *pt, uint32_t page_number) {
printf("Page Fault! Loading page %d from disk...\n", page_number);
// Find free frame (or evict a page)
uint32_t free_frame = find_free_frame();
if (free_frame == UINT32_MAX) {
// No free frames - need to evict
free_frame = page_replacement_algorithm(pt);
}
// Load page from disk (simulated)
load_page_from_disk(page_number, free_frame);
// Update page table
pt->entries[page_number].present = true;
pt->entries[page_number].frame = free_frame;
pt->entries[page_number].dirty = false;
pt->entries[page_number].accessed = true;
printf("Page %d loaded into frame %d\n", page_number, free_frame);
}
// Virtual to physical address translation
uint32_t translate_address(PageTable *pt, uint32_t virtual_address) {
uint32_t page_number = virtual_address / PAGE_SIZE;
uint32_t offset = virtual_address % PAGE_SIZE;
if (page_number >= NUM_PAGES) {
printf("ERROR: Invalid virtual address 0x%X\n", virtual_address);
return UINT32_MAX;
}
PageTableEntry *pte = &pt->entries[page_number];
if (!pte->present) {
// Page fault!
handle_page_fault(pt, page_number);
}
// Mark as accessed (for page replacement)
pte->accessed = true;
// Calculate physical address
uint32_t physical_address = (pte->frame * PAGE_SIZE) + offset;
printf("Virtual 0x%X (page %d, offset %d) → Physical 0x%X (frame %d)\n",
virtual_address, page_number, offset, physical_address, pte->frame);
return physical_address;
}11.3 Page Replacement Algorithms
When all frames are occupied, must choose a victim page to evict.
11.3.1 FIFO (First-In-First-Out)
/*
* FIFO: Replace oldest page in memory
* Simple but suffers from Belady's Anomaly
*/
#include <stdint.h>
#define MAX_FRAMES 3
typedef struct {
uint32_t frames[MAX_FRAMES];
int front; // Oldest page index
int count;
} FIFOQueue;
void init_fifo(FIFOQueue *q) {
q->front = 0;
q->count = 0;
for (int i = 0; i < MAX_FRAMES; i++) {
q->frames[i] = UINT32_MAX;
}
}
bool is_page_in_memory(FIFOQueue *q, uint32_t page) {
for (int i = 0; i < MAX_FRAMES; i++) {
if (q->frames[i] == page) {
return true;
}
}
return false;
}
int fifo_replace(FIFOQueue *q, uint32_t page) {
if (is_page_in_memory(q, page)) {
printf("Page %d already in memory\n", page);
return 0; // No fault
}
if (q->count < MAX_FRAMES) {
// Still have free frames
q->frames[q->count] = page;
q->count++;
printf("FIFO: Loaded page %d into frame %d\n", page, q->count - 1);
} else {
// Replace oldest page
uint32_t victim = q->frames[q->front];
q->frames[q->front] = page;
q->front = (q->front + 1) % MAX_FRAMES;
printf("FIFO: Replaced page %d with page %d\n", victim, page);
}
return 1; // Page fault occurred
}
// Example: Belady's Anomaly
void demonstrate_belady_anomaly() {
uint32_t reference_string[] = {1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5};
int length = sizeof(reference_string) / sizeof(reference_string[0]);
FIFOQueue queue;
init_fifo(&queue);
int page_faults = 0;
printf("=== FIFO Page Replacement ===\n");
for (int i = 0; i < length; i++) {
printf("Accessing page %d: ", reference_string[i]);
page_faults += fifo_replace(&queue, reference_string[i]);
}
printf("Total page faults: %d\n\n", page_faults);
}11.3.2 LRU (Least Recently Used)
/*
* LRU: Replace page that hasn't been used for longest time
* Optimal but expensive to implement exactly
*/
typedef struct {
uint32_t page;
uint64_t last_access_time;
} LRUFrame;
typedef struct {
LRUFrame frames[MAX_FRAMES];
int count;
uint64_t current_time;
} LRUCache;
void init_lru(LRUCache *cache) {
cache->count = 0;
cache->current_time = 0;
for (int i = 0; i < MAX_FRAMES; i++) {
cache->frames[i].page = UINT32_MAX;
cache->frames[i].last_access_time = 0;
}
}
int find_lru_victim(LRUCache *cache) {
int victim_idx = 0;
uint64_t oldest_time = cache->frames[0].last_access_time;
for (int i = 1; i < MAX_FRAMES; i++) {
if (cache->frames[i].last_access_time < oldest_time) {
oldest_time = cache->frames[i].last_access_time;
victim_idx = i;
}
}
return victim_idx;
}
int lru_access(LRUCache *cache, uint32_t page) {
cache->current_time++;
// Check if page already in memory
for (int i = 0; i < cache->count; i++) {
if (cache->frames[i].page == page) {
cache->frames[i].last_access_time = cache->current_time;
printf("LRU: Page %d hit (updated access time)\n", page);
return 0; // No fault
}
}
// Page fault
if (cache->count < MAX_FRAMES) {
// Free frame available
cache->frames[cache->count].page = page;
cache->frames[cache->count].last_access_time = cache->current_time;
cache->count++;
printf("LRU: Loaded page %d into frame %d\n", page, cache->count - 1);
} else {
// Replace LRU page
int victim_idx = find_lru_victim(cache);
uint32_t victim_page = cache->frames[victim_idx].page;
cache->frames[victim_idx].page = page;
cache->frames[victim_idx].last_access_time = cache->current_time;
printf("LRU: Replaced page %d (LRU) with page %d\n", victim_page, page);
}
return 1; // Page fault
}
// Approximate LRU using Clock algorithm (Second Chance)
typedef struct {
uint32_t page;
bool reference_bit;
} ClockFrame;
typedef struct {
ClockFrame frames[MAX_FRAMES];
int hand; // Clock hand position
int count;
} ClockAlgorithm;
void init_clock(ClockAlgorithm *clock) {
clock->hand = 0;
clock->count = 0;
for (int i = 0; i < MAX_FRAMES; i++) {
clock->frames[i].page = UINT32_MAX;
clock->frames[i].reference_bit = false;
}
}
int clock_replace(ClockAlgorithm *clock, uint32_t page) {
// Check if already in memory
for (int i = 0; i < clock->count; i++) {
if (clock->frames[i].page == page) {
clock->frames[i].reference_bit = true; // Set reference bit
return 0; // No fault
}
}
// Page fault
if (clock->count < MAX_FRAMES) {
// Free frame available
clock->frames[clock->count].page = page;
clock->frames[clock->count].reference_bit = true;
clock->count++;
printf("Clock: Loaded page %d into frame %d\n", page, clock->count - 1);
} else {
// Search for victim using clock algorithm
while (true) {
if (!clock->frames[clock->hand].reference_bit) {
// Found victim (reference bit = 0)
uint32_t victim = clock->frames[clock->hand].page;
clock->frames[clock->hand].page = page;
clock->frames[clock->hand].reference_bit = true;
printf("Clock: Replaced page %d with page %d\n", victim, page);
clock->hand = (clock->hand + 1) % MAX_FRAMES;
break;
} else {
// Give second chance
clock->frames[clock->hand].reference_bit = false;
clock->hand = (clock->hand + 1) % MAX_FRAMES;
}
}
}
return 1; // Page fault
}11.3.3 Optimal (MIN)
/*
* Optimal: Replace page that will not be used for longest time
* Theoretical best, not implementable (requires future knowledge)
* Used as benchmark to compare other algorithms
*/
int optimal_replace(uint32_t current_pages[], int num_frames,
uint32_t reference_string[], int length,
int current_position) {
// Find page not used for longest time in future
int victim_idx = -1;
int farthest = current_position;
for (int i = 0; i < num_frames; i++) {
int j;
for (j = current_position; j < length; j++) {
if (current_pages[i] == reference_string[j]) {
if (j > farthest) {
farthest = j;
victim_idx = i;
}
break;
}
}
// Page never used again - perfect victim!
if (j == length) {
return i;
}
}
return victim_idx != -1 ? victim_idx : 0;
}11.4 Translation Lookaside Buffer (TLB)
TLB is a hardware cache for page table entries.
/*
* TLB (Translation Lookaside Buffer):
* Fast cache for page table entries
* Typically 64-128 entries, fully associative
* 95%+ hit rate in practice
*/
#define TLB_SIZE 16
typedef struct {
uint32_t page_number;
uint32_t frame_number;
bool valid;
} TLBEntry;
typedef struct {
TLBEntry entries[TLB_SIZE];
int next_replacement; // For FIFO replacement
uint64_t hits;
uint64_t misses;
} TLB;
void init_tlb(TLB *tlb) {
for (int i = 0; i < TLB_SIZE; i++) {
tlb->entries[i].valid = false;
}
tlb->next_replacement = 0;
tlb->hits = 0;
tlb->misses = 0;
}
bool tlb_lookup(TLB *tlb, uint32_t page_number, uint32_t *frame_number) {
for (int i = 0; i < TLB_SIZE; i++) {
if (tlb->entries[i].valid &&
tlb->entries[i].page_number == page_number) {
*frame_number = tlb->entries[i].frame_number;
tlb->hits++;
printf("TLB HIT: Page %d → Frame %d\n", page_number, *frame_number);
return true;
}
}
tlb->misses++;
printf("TLB MISS: Page %d\n", page_number);
return false;
}
void tlb_insert(TLB *tlb, uint32_t page_number, uint32_t frame_number) {
// FIFO replacement in TLB
tlb->entries[tlb->next_replacement].page_number = page_number;
tlb->entries[tlb->next_replacement].frame_number = frame_number;
tlb->entries[tlb->next_replacement].valid = true;
tlb->next_replacement = (tlb->next_replacement + 1) % TLB_SIZE;
printf("TLB INSERT: Page %d → Frame %d\n", page_number, frame_number);
}
void tlb_flush(TLB *tlb) {
// Called on context switch
for (int i = 0; i < TLB_SIZE; i++) {
tlb->entries[i].valid = false;
}
printf("TLB FLUSHED (context switch)\n");
}
// Complete address translation with TLB
uint32_t translate_with_tlb(TLB *tlb, PageTable *pt, uint32_t virtual_addr) {
uint32_t page_number = virtual_addr / PAGE_SIZE;
uint32_t offset = virtual_addr % PAGE_SIZE;
uint32_t frame_number;
// Step 1: Check TLB
if (tlb_lookup(tlb, page_number, &frame_number)) {
// TLB hit - fast path!
return (frame_number * PAGE_SIZE) + offset;
}
// Step 2: TLB miss - check page table
if (!pt->entries[page_number].present) {
// Page fault
handle_page_fault(pt, page_number);
}
frame_number = pt->entries[page_number].frame;
// Step 3: Update TLB
tlb_insert(tlb, page_number, frame_number);
return (frame_number * PAGE_SIZE) + offset;
}
void print_tlb_stats(TLB *tlb) {
uint64_t total = tlb->hits + tlb->misses;
double hit_rate = (double)tlb->hits / total * 100.0;
printf("\n=== TLB Statistics ===\n");
printf("Hits: %lu\n", tlb->hits);
printf("Misses: %lu\n", tlb->misses);
printf("Hit Rate: %.2f%%\n", hit_rate);
}11.5 Multi-Level Page Tables
Reduce memory overhead of large page tables.
/*
* Problem: Single-level page table for 32-bit address space
* 4KB pages: 2^32 / 2^12 = 2^20 (1 million) entries
* If each entry = 4 bytes: 4MB per process!
*
* Solution: Multi-level (hierarchical) page tables
*/
// Two-level page table for 32-bit address space
#define PAGE_DIR_SIZE 1024 // 10 bits
#define PAGE_TABLE_SIZE 1024 // 10 bits
// Offset: 12 bits
// Total: 10 + 10 + 12 = 32 bits
typedef struct {
PageTableEntry entries[PAGE_TABLE_SIZE];
} SecondLevelPageTable;
typedef struct {
SecondLevelPageTable *tables[PAGE_DIR_SIZE];
bool present[PAGE_DIR_SIZE];
} PageDirectory;
void init_page_directory(PageDirectory *pd) {
for (int i = 0; i < PAGE_DIR_SIZE; i++) {
pd->tables[i] = NULL;
pd->present[i] = false;
}
}
uint32_t translate_two_level(PageDirectory *pd, uint32_t virtual_addr) {
// Extract indices
uint32_t dir_index = (virtual_addr >> 22) & 0x3FF; // Bits 31-22
uint32_t table_index = (virtual_addr >> 12) & 0x3FF; // Bits 21-12
uint32_t offset = virtual_addr & 0xFFF; // Bits 11-0
printf("Virtual 0x%08X: dir=%d, table=%d, offset=%d\n",
virtual_addr, dir_index, table_index, offset);
// Check if page table exists
if (!pd->present[dir_index]) {
printf("Page directory entry not present - allocate page table\n");
pd->tables[dir_index] = malloc(sizeof(SecondLevelPageTable));
pd->present[dir_index] = true;
}
SecondLevelPageTable *page_table = pd->tables[dir_index];
PageTableEntry *pte = &page_table->entries[table_index];
if (!pte->present) {
// Page fault
printf("Page fault at dir=%d, table=%d\n", dir_index, table_index);
return UINT32_MAX;
}
uint32_t physical_addr = (pte->frame * PAGE_SIZE) + offset;
return physical_addr;
}
/*
* Advantages of Multi-Level Page Tables:
* 1. Only allocate page tables for used address space
* 2. Typical process uses small fraction of address space
* 3. Example: Process using 8MB of 4GB space
* - Single level: 4MB page table
* - Two level: ~8KB page tables
* 4. Can extend to 3, 4, or more levels (x86-64 uses 4 levels)
*/11.6 Page Table Entry Structure
/*
* Typical Page Table Entry (x86)
*/
typedef struct {
unsigned int present : 1; // 1 = page in memory
unsigned int rw : 1; // 1 = read/write, 0 = read-only
unsigned int user : 1; // 1 = user mode can access
unsigned int pwt : 1; // Page write-through
unsigned int pcd : 1; // Page cache disabled
unsigned int accessed : 1; // Has page been accessed?
unsigned int dirty : 1; // Has page been written to?
unsigned int pat : 1; // Page attribute table
unsigned int global : 1; // Don't flush on context switch
unsigned int available : 3; // Available for OS use
unsigned int frame : 20; // Physical frame number (4KB aligned)
} x86_PTE;
void print_pte(x86_PTE *pte) {
printf("PTE: Frame=%d, P=%d, R/W=%d, U/S=%d, A=%d, D=%d\n",
pte->frame, pte->present, pte->rw, pte->user,
pte->accessed, pte->dirty);
}
// Check page permissions
bool check_access(x86_PTE *pte, bool is_write, bool is_user_mode) {
if (!pte->present) {
printf("Page fault: Page not present\n");
return false;
}
if (is_write && !pte->rw) {
printf("Protection fault: Write to read-only page\n");
return false;
}
if (is_user_mode && !pte->user) {
printf("Protection fault: User mode accessing supervisor page\n");
return false;
}
return true;
}11.7 Inverted Page Tables
Alternative approach for large address spaces.
/*
* Inverted Page Table:
* One entry per physical frame (not per virtual page)
* Saves space for 64-bit systems
*/
#define NUM_PHYSICAL_FRAMES 256
typedef struct {
uint32_t pid; // Process ID
uint32_t virtual_page; // Virtual page number
bool valid;
} InvertedPageTableEntry;
typedef struct {
InvertedPageTableEntry entries[NUM_PHYSICAL_FRAMES];
} InvertedPageTable;
uint32_t inverted_translate(InvertedPageTable *ipt, uint32_t pid,
uint32_t virtual_addr) {
uint32_t virtual_page = virtual_addr / PAGE_SIZE;
uint32_t offset = virtual_addr % PAGE_SIZE;
// Search for matching entry (linear search or use hash table)
for (int frame = 0; frame < NUM_PHYSICAL_FRAMES; frame++) {
if (ipt->entries[frame].valid &&
ipt->entries[frame].pid == pid &&
ipt->entries[frame].virtual_page == virtual_page) {
uint32_t physical_addr = (frame * PAGE_SIZE) + offset;
printf("Inverted PT: Found frame %d for PID=%d, VPage=%d\n",
frame, pid, virtual_page);
return physical_addr;
}
}
printf("Page fault: No mapping found\n");
return UINT32_MAX;
}
/*
* Pros:
* - Fixed size regardless of address space size
* - One table for entire system
*
* Cons:
* - Slower lookup (need to search)
* - Difficult to implement shared memory
*
* Used in: IBM PowerPC, HP PA-RISC
*/11.8 Memory-Mapped Files
Map files directly into virtual address space.
/*
* Memory-Mapped Files:
* Access file contents as if they were in memory
* OS handles loading pages from file on demand
*/
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
void example_mmap() {
// Open file
int fd = open("example.dat", O_RDWR);
if (fd == -1) {
perror("open");
return;
}
// Get file size
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("fstat");
close(fd);
return;
}
// Map file into memory
char *mapped = mmap(NULL, // Let OS choose address
sb.st_size, // Map entire file
PROT_READ | PROT_WRITE, // Read/write access
MAP_SHARED, // Changes written to file
fd,
0); // Offset 0
if (mapped == MAP_FAILED) {
perror("mmap");
close(fd);
return;
}
printf("File mapped at %p, size %ld bytes\n", mapped, sb.st_size);
// Access file like normal memory!
mapped[0] = 'X'; // Modifies file
printf("First byte: %c\n", mapped[0]);
// Unmap when done
munmap(mapped, sb.st_size);
close(fd);
}
/*
* Benefits of mmap:
* 1. Simplified file I/O (no read/write calls)
* 2. Automatic caching by OS
* 3. Shared memory between processes
* 4. Efficient for large files (load on demand)
*/11.9 Copy-on-Write (COW)
Optimize fork() by deferring copying.
/*
* Copy-on-Write:
* When fork() called, don't copy pages immediately
* Parent and child share pages (marked read-only)
* On write attempt, copy page at that moment
*/
void demonstrate_cow() {
int *data = malloc(1000000 * sizeof(int));
// Fill with data...
pid_t pid = fork();
if (pid == 0) {
// Child process
printf("Child: data pointer = %p\n", data);
// Reading is fine (pages shared)
printf("Child reading: data[0] = %d\n", data[0]);
// Writing triggers copy
printf("Child writing to data[0]...\n");
data[0] = 999; // COW: Page copied now!
printf("Child: data[0] = %d\n", data[0]);
} else {
// Parent process
sleep(1);
printf("Parent: data[0] = %d\n", data[0]); // Still original value
}
}
/*
* COW Implementation:
* 1. Mark all pages as read-only in child's page table
* 2. Set COW bit in page table entries
* 3. On write, page fault handler:
* a. Check if COW page
* b. Allocate new frame
* c. Copy data
* d. Update page table (mark writable)
* e. Resume execution
*/11.10 Thrashing
When system spends more time paging than executing.
/*
* Thrashing occurs when:
* - Too many processes competing for limited frames
* - Each process doesn't have enough frames
* - Constant page faults
* - CPU utilization drops dramatically
*/
// Working Set Model
typedef struct {
uint32_t *pages; // Pages in working set
int size; // Current size
int max_size; // Window size
uint64_t time_window; // Time window (e.g., last 1000 refs)
} WorkingSet;
// Calculate working set size
int calculate_working_set(uint32_t reference_string[], int length, int window) {
bool in_working_set[NUM_PAGES] = {false};
int working_set_size = 0;
// Consider last 'window' references
int start = (length - window > 0) ? length - window : 0;
for (int i = start; i < length; i++) {
uint32_t page = reference_string[i];
if (!in_working_set[page]) {
in_working_set[page] = true;
working_set_size++;
}
}
return working_set_size;
}
/*
* Solutions to Thrashing:
* 1. Working Set Model: Allocate frames based on working set size
* 2. Page Fault Frequency: Adjust allocation based on fault rate
* 3. Suspend processes if insufficient memory
* 4. Increase physical memory
*/11.11 Page Replacement Algorithm Comparison
| Algorithm | Advantages | Disadvantages | Use Case |
|---|---|---|---|
| FIFO | Simple, low overhead | Belady’s anomaly | Rarely used alone |
| Optimal | Best possible (fewest faults) | Impossible to implement | Benchmark only |
| LRU | Good performance | Expensive to implement exactly | Common approximation target |
| Clock (Second Chance) | Good approximation of LRU | Slightly more complex than FIFO | Linux, Windows |
| LFU | Protects frequently used pages | Difficult to implement | Specialized cases |
Key Takeaways
Virtual Memory Fundamentals - Master These Concepts:
- Virtual memory separates logical from physical address space → Programs can use more memory than physically available
- Demand paging loads pages only when accessed (lazy loading) → Saves memory, improves startup time
- TLB caches page table entries for fast translation (95%+ hit rate) → Critical for performance!
- Multi-level page tables save space for sparse address spaces → 4-level on x86-64
- Page replacement algorithms: FIFO (simple), LRU (optimal), Clock (practical) → Choose based on workload
- Copy-on-Write optimizes fork() by deferring page copying → Makes process creation fast
- Thrashing occurs when system spends more time paging than executing → Monitor page fault rate!
- Memory-mapped files provide efficient file I/O → Zero-copy I/O
12. File Systems
12.1 File System Basics
A file system organizes and stores data on storage devices, providing:
- Persistent storage
- Hierarchical namespace
- Access control and permissions
- Efficient space management
/*
* File: Named collection of related information
* Directory: Container for files and other directories
* Path: Location of file in hierarchy
*/
// File attributes (metadata)
typedef struct {
char name[256];
uint64_t size; // Size in bytes
uint32_t inode_number; // Unique identifier
uint16_t mode; // Permissions
uint32_t uid; // Owner user ID
uint32_t gid; // Owner group ID
time_t created; // Creation time
time_t modified; // Last modification
time_t accessed; // Last access
uint32_t link_count; // Number of hard links
} FileMetadata;12.2 File Operations
/*
* Core File Operations (System Calls)
*/
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
// Open file: Get file descriptor
int fd = open("file.txt", O_RDWR | O_CREAT, 0644);
if (fd == -1) {
perror("open");
return -1;
}
// Read from file
char buffer[1024];
ssize_t bytes_read = read(fd, buffer, sizeof(buffer));
printf("Read %zd bytes\n", bytes_read);
// Write to file
const char *data = "Hello, World!";
ssize_t bytes_written = write(fd, data, strlen(data));
// Move file pointer (seek)
off_t new_pos = lseek(fd, 0, SEEK_SET); // Seek to beginning
// SEEK_CUR: relative to current position
// SEEK_END: relative to end of file
// Get file information
struct stat file_info;
if (fstat(fd, &file_info) == 0) {
printf("File size: %ld bytes\n", file_info.st_size);
printf("Inode: %lu\n", file_info.st_ino);
printf("Permissions: %o\n", file_info.st_mode & 0777);
}
// Close file
close(fd);
/*
* File Descriptor Table:
* Process maintains table mapping fd to open file structures
* fd 0: stdin, fd 1: stdout, fd 2: stderr
* New files get lowest available fd
*/12.3 Directory Structure
Unix/Linux File System Hierarchy
/*
* Unix/Linux Filesystem Hierarchy Standard (FHS)
*
* / Root directory
* ├── bin/ Essential user binaries (ls, cp, mv)
* ├── boot/ Boot loader files (kernel, initrd)
* ├── dev/ Device files (disks, terminals)
* ├── etc/ System configuration files
* ├── home/ User home directories
* ├── lib/ Shared libraries
* ├── mnt/ Temporary mount points
* ├── opt/ Optional application packages
* ├── proc/ Process information (virtual filesystem)
* ├── root/ Root user's home directory
* ├── sbin/ System binaries (fsck, init)
* ├── sys/ Kernel and system information (virtual)
* ├── tmp/ Temporary files
* ├── usr/ User programs and data
* │ ├── bin/ User binaries
* │ ├── lib/ Libraries
* │ └── share/ Shared data
* └── var/ Variable data (logs, mail, temp files)
* ├── log/ System logs
* └── tmp/ Temporary files
*/
// Directory operations
#include <dirent.h>
void list_directory(const char *path) {
DIR *dir = opendir(path);
if (!dir) {
perror("opendir");
return;
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) {
printf("%s", entry->d_name);
// Determine file type
switch (entry->d_type) {
case DT_REG: printf(" (file)\n"); break;
case DT_DIR: printf(" (directory)\n"); break;
case DT_LNK: printf(" (symlink)\n"); break;
case DT_CHR: printf(" (char device)\n"); break;
case DT_BLK: printf(" (block device)\n"); break;
case DT_FIFO: printf(" (FIFO)\n"); break;
case DT_SOCK: printf(" (socket)\n"); break;
default: printf(" (unknown)\n"); break;
}
}
closedir(dir);
}12.4 File Allocation Methods
12.4.1 Contiguous Allocation
/*
* Contiguous Allocation:
* File occupies consecutive blocks on disk
*
* Pros:
* - Simple
* - Fast sequential access
* - Easy random access
*
* Cons:
* - External fragmentation
* - Difficult to grow files
* - Need to know file size in advance
*/
typedef struct {
char filename[256];
uint32_t start_block; // Starting block number
uint32_t length; // Number of blocks
} ContiguousFile;
void read_contiguous_file(ContiguousFile *file, uint32_t offset) {
uint32_t block_size = 4096;
uint32_t block_number = file->start_block + (offset / block_size);
uint32_t block_offset = offset % block_size;
printf("Reading from block %d, offset %d\n", block_number, block_offset);
// Read from disk block...
}12.4.2 Linked Allocation
/*
* Linked Allocation:
* Each block contains pointer to next block
*
* Pros:
* - No external fragmentation
* - File can grow easily
* - No need to know size in advance
*
* Cons:
* - Slow random access
* - Space overhead (pointers)
* - Poor reliability (broken link loses rest of file)
*/
#define BLOCK_SIZE 4096
#define DATA_SIZE (BLOCK_SIZE - sizeof(uint32_t))
typedef struct FileBlock {
uint8_t data[DATA_SIZE];
uint32_t next_block; // Next block number (or -1 for end)
} FileBlock;
typedef struct {
char filename[256];
uint32_t first_block;
} LinkedFile;
void read_linked_file(LinkedFile *file, uint32_t offset) {
uint32_t current_block = file->first_block;
uint32_t bytes_to_skip = offset;
// Follow chain to find correct block
while (bytes_to_skip > DATA_SIZE) {
FileBlock block;
// Read block from disk...
current_block = block.next_block;
if (current_block == (uint32_t)-1) {
printf("Offset beyond end of file\n");
return;
}
bytes_to_skip -= DATA_SIZE;
}
printf("Reading from block %d, offset %d\n", current_block, bytes_to_skip);
}
// FAT (File Allocation Table) Variant
#define NUM_BLOCKS 10000
typedef struct {
uint32_t fat[NUM_BLOCKS]; // fat[i] = next block after block i
} FAT;
/*
* FAT Advantages:
* - Random access improved (FAT can be cached in memory)
* - Only need to traverse FAT, not actual disk blocks
* Used in: MS-DOS, FAT32
*/12.4.3 Indexed Allocation
/*
* Indexed Allocation:
* Index block contains pointers to all data blocks
*
* Pros:
* - Fast random access
* - No external fragmentation
* - Supports direct access
*
* Cons:
* - Index block overhead
* - Maximum file size limited by index block size
*/
#define POINTERS_PER_BLOCK (BLOCK_SIZE / sizeof(uint32_t)) // 1024 pointers
typedef struct {
uint32_t block_pointers[POINTERS_PER_BLOCK];
} IndexBlock;
typedef struct {
char filename[256];
uint32_t index_block_number;
uint32_t file_size;
} IndexedFile;
void read_indexed_file(IndexedFile *file, uint32_t offset) {
uint32_t block_num = offset / BLOCK_SIZE;
uint32_t block_offset = offset % BLOCK_SIZE;
if (block_num >= POINTERS_PER_BLOCK) {
printf("File too large for single index block\n");
return;
}
// Read index block
IndexBlock index;
// read_disk_block(file->index_block_number, &index);
uint32_t data_block = index.block_pointers[block_num];
printf("Reading from block %d, offset %d\n", data_block, block_offset);
}
// Multi-level Indexed (used in Unix inode)
typedef struct {
uint32_t direct[12]; // Direct block pointers
uint32_t single_indirect; // Points to block of pointers
uint32_t double_indirect; // Points to block of indirect blocks
uint32_t triple_indirect; // Three levels of indirection
} MultiLevelIndex;
/*
* Unix inode addressing:
* - Direct: 12 * 4KB = 48KB
* - Single indirect: 1024 * 4KB = 4MB
* - Double indirect: 1024 * 1024 * 4KB = 4GB
* - Triple indirect: 1024 * 1024 * 1024 * 4KB = 4TB
* Total: ~4TB max file size
*/12.5 Unix/Linux Inode Structure
/*
* Inode: Index Node
* Contains all file metadata except name
* Name stored in directory entry
*/
typedef struct {
uint16_t mode; // File type and permissions
uint16_t uid; // User ID
uint32_t size; // File size in bytes
uint32_t atime; // Access time
uint32_t ctime; // Change time (metadata)
uint32_t mtime; // Modification time (content)
uint32_t dtime; // Deletion time
uint16_t gid; // Group ID
uint16_t links_count; // Hard link count
uint32_t blocks; // Number of 512-byte blocks
uint32_t flags; // File flags
uint32_t block[15]; // Block pointers (12 direct + 3 indirect)
} Inode;
// Directory entry
typedef struct {
uint32_t inode_number;
uint16_t rec_len; // Length of this directory entry
uint8_t name_len; // Length of filename
uint8_t file_type; // File type
char name[255]; // Filename (variable length)
} DirEntry;
/*
* Hard Link: Multiple directory entries point to same inode
* Symbolic Link: File containing path to another file
*/
// Create hard link
link("original.txt", "hardlink.txt"); // Both point to same inode
// Create symbolic link
symlink("original.txt", "symlink.txt"); // Contains path string
// Differences:
// - Hard link: Same inode, survives if original deleted
// - Sym link: Different inode, breaks if original deleted
12.6 Virtual File System (VFS)
/*
* VFS: Abstract layer above file systems
* Provides uniform interface for different FS types
* Allows ext4, FAT, NFS, etc. to coexist
*/
// VFS abstraction
typedef struct FileSystemOperations {
int (*open)(const char *path, int flags);
ssize_t (*read)(int fd, void *buf, size_t count);
ssize_t (*write)(int fd, const void *buf, size_t count);
int (*close)(int fd);
int (*mkdir)(const char *path, mode_t mode);
// ... more operations
} FSOperations;
// Different file systems implement interface
FSOperations ext4_ops = {
.open = ext4_open,
.read = ext4_read,
.write = ext4_write,
// ...
};
FSOperations fat32_ops = {
.open = fat32_open,
.read = fat32_read,
.write = fat32_write,
// ...
};
/*
* VFS Components:
* 1. Superblock: Filesystem metadata
* 2. Inode: File metadata
* 3. Dentry: Directory entry cache
* 4. File: Open file representation
*/
typedef struct VFS_Superblock {
uint32_t magic; // Filesystem type
uint32_t block_size;
uint64_t total_blocks;
uint64_t free_blocks;
FSOperations *ops; // Filesystem-specific operations
} VFS_Superblock;12.7 Free Space Management
12.7.1 Bit Vector (Bitmap)
/*
* Bitmap: One bit per block
* 0 = free, 1 = allocated
*
* Pros: Simple, efficient to find free blocks
* Cons: Extra space overhead
*/
#define TOTAL_BLOCKS 100000
#define BITMAP_SIZE (TOTAL_BLOCKS / 8) // Bytes needed
uint8_t bitmap[BITMAP_SIZE];
// Set bit (mark block as allocated)
void mark_allocated(uint32_t block_num) {
uint32_t byte_index = block_num / 8;
uint8_t bit_offset = block_num % 8;
bitmap[byte_index] |= (1 << bit_offset);
}
// Clear bit (mark block as free)
void mark_free(uint32_t block_num) {
uint32_t byte_index = block_num / 8;
uint8_t bit_offset = block_num % 8;
bitmap[byte_index] &= ~(1 << bit_offset);
}
// Check if block is free
bool is_free(uint32_t block_num) {
uint32_t byte_index = block_num / 8;
uint8_t bit_offset = block_num % 8;
return (bitmap[byte_index] & (1 << bit_offset)) == 0;
}
// Find first free block
uint32_t find_free_block() {
for (uint32_t i = 0; i < BITMAP_SIZE; i++) {
if (bitmap[i] != 0xFF) { // Not all bits set
// Find first zero bit
for (uint8_t bit = 0; bit < 8; bit++) {
if ((bitmap[i] & (1 << bit)) == 0) {
return (i * 8) + bit;
}
}
}
}
return UINT32_MAX; // No free blocks
}12.7.2 Linked List
/*
* Linked List of Free Blocks
*
* Pros: No extra space needed (use free blocks themselves)
* Cons: Cannot efficiently find contiguous space
*/
typedef struct FreeBlock {
uint32_t next_free; // Stored in free block itself
} FreeBlock;
typedef struct {
uint32_t head; // First free block
} FreeList;
FreeList free_list = {.head = 0};
uint32_t allocate_block(FreeList *list) {
if (list->head == UINT32_MAX) {
return UINT32_MAX; // No free blocks
}
uint32_t allocated = list->head;
// Read free block to get next pointer
FreeBlock block;
// read_disk_block(allocated, &block);
list->head = block.next_free;
printf("Allocated block %d\n", allocated);
return allocated;
}
void free_block(FreeList *list, uint32_t block_num) {
FreeBlock block;
block.next_free = list->head;
// Write block back with updated pointer
// write_disk_block(block_num, &block);
list->head = block_num;
printf("Freed block %d\n", block_num);
}12.7.3 Grouping
/*
* Grouping: Store addresses of n free blocks in first free block
* Last address points to another block with n free addresses
*/
#define ADDRESSES_PER_BLOCK 512
typedef struct FreeBlockGroup {
uint32_t count;
uint32_t blocks[ADDRESSES_PER_BLOCK];
} FreeBlockGroup;12.8 Disk Layout Examples
ext4 Filesystem Layout
/*
* ext4 (Fourth Extended Filesystem) - Linux default
*
* Structure:
* [Boot Block][Block Group 0][Block Group 1]...[Block Group N]
*
* Each Block Group:
* - Superblock (backup in some groups)
* - Group Descriptors
* - Block Bitmap
* - Inode Bitmap
* - Inode Table
* - Data Blocks
*/
typedef struct ext4_superblock {
uint32_t s_inodes_count; // Total inodes
uint32_t s_blocks_count; // Total blocks
uint32_t s_r_blocks_count; // Reserved blocks
uint32_t s_free_blocks_count; // Free blocks
uint32_t s_free_inodes_count; // Free inodes
uint32_t s_first_data_block; // First data block
uint32_t s_log_block_size; // Block size = 1024 << s_log_block_size
uint32_t s_blocks_per_group; // Blocks per group
uint32_t s_inodes_per_group; // Inodes per group
uint32_t s_magic; // Magic signature (0xEF53)
// ... many more fields
} ext4_superblock_t;
#define EXT4_SUPER_MAGIC 0xEF5312.9 File System Operations Implementation
/*
* Create a new file
*/
int create_file(const char *path, mode_t mode) {
// 1. Parse path to find parent directory
char parent_path[PATH_MAX];
char filename[256];
// split_path(path, parent_path, filename);
// 2. Allocate new inode
uint32_t new_inode_num = allocate_inode();
if (new_inode_num == UINT32_MAX) {
return -ENOSPC; // No space
}
// 3. Initialize inode
Inode *inode = get_inode(new_inode_num);
inode->mode = mode | S_IFREG; // Regular file
inode->uid = getuid();
inode->gid = getgid();
inode->size = 0;
inode->atime = inode->mtime = inode->ctime = time(NULL);
inode->links_count = 1;
inode->blocks = 0;
// 4. Add directory entry in parent
DirEntry entry = {
.inode_number = new_inode_num,
.name_len = strlen(filename),
.file_type = DT_REG,
};
strcpy(entry.name, filename);
// add_dir_entry(parent_path, &entry);
printf("Created file: %s (inode %d)\n", path, new_inode_num);
return 0;
}
/*
* Delete a file
*/
int delete_file(const char *path) {
// 1. Find inode
uint32_t inode_num = path_to_inode(path);
if (inode_num == UINT32_MAX) {
return -ENOENT; // File not found
}
Inode *inode = get_inode(inode_num);
// 2. Decrement link count
inode->links_count--;
if (inode->links_count == 0) {
// 3. Free data blocks
for (int i = 0; i < 12 && inode->block[i] != 0; i++) {
free_block(&free_list, inode->block[i]);
}
// Handle indirect blocks...
// 4. Free inode
free_inode(inode_num);
printf("Deleted file: %s\n", path);
} else {
printf("Decremented link count for: %s (links remaining: %d)\n",
path, inode->links_count);
}
// 5. Remove directory entry
// remove_dir_entry(path);
return 0;
}12.10 File Permissions (Unix/Linux)
/*
* Unix File Permissions:
* 9 bits: rwx rwx rwx (owner, group, others)
* 3 special bits: setuid, setgid, sticky
*/
// Permission bits
#define S_IRUSR 0400 // User read
#define S_IWUSR 0200 // User write
#define S_IXUSR 0100 // User execute
#define S_IRGRP 0040 // Group read
#define S_IWGRP 0020 // Group write
#define S_IXGRP 0010 // Group execute
#define S_IROTH 0004 // Others read
#define S_IWOTH 0002 // Others write
#define S_IXOTH 0001 // Others execute
// Check permissions
bool can_access(Inode *inode, uid_t uid, gid_t gid, int required_perms) {
mode_t mode = inode->mode;
// Root can do anything
if (uid == 0) {
return true;
}
// Check owner permissions
if (uid == inode->uid) {
mode >>= 6; // Shift to owner bits
}
// Check group permissions
else if (gid == inode->gid) {
mode >>= 3; // Shift to group bits
}
// Others permissions (no shift needed)
return (mode & required_perms) == required_perms;
}
// Change permissions
int chmod_file(const char *path, mode_t new_mode) {
uint32_t inode_num = path_to_inode(path);
Inode *inode = get_inode(inode_num);
// Only owner or root can change permissions
if (getuid() != 0 && getuid() != inode->uid) {
return -EPERM;
}
inode->mode = (inode->mode & ~0777) | (new_mode & 0777);
printf("Changed permissions of %s to %o\n", path, new_mode);
return 0;
}
// Example usage
chmod("file.txt", 0644); // rw-r--r--
chmod("script.sh", 0755); // rwxr-xr-x
12.11 Journaling File Systems
/*
* Journaling: Log changes before applying them
* Ensures consistency after crash
*
* Types:
* 1. Data journaling: Log both metadata and data
* 2. Metadata journaling: Log only metadata (most common)
* 3. Ordered: Write data before metadata
*/
typedef struct JournalEntry {
uint64_t transaction_id;
uint32_t operation; // CREATE, DELETE, MODIFY
uint32_t inode_num;
time_t timestamp;
// ... operation-specific data
} JournalEntry;
// Write operation with journaling
void journaled_write(const char *path, const void *data, size_t size) {
// 1. Begin transaction - write to journal
JournalEntry entry = {
.transaction_id = get_next_txn_id(),
.operation = OP_WRITE,
.timestamp = time(NULL),
};
write_to_journal(&entry);
// 2. Write data to journal
write_data_to_journal(data, size);
// 3. Commit transaction in journal
commit_journal_transaction(entry.transaction_id);
// 4. Apply changes to filesystem (checkpoint)
apply_to_filesystem(path, data, size);
// 5. Mark transaction as complete in journal
complete_journal_transaction(entry.transaction_id);
printf("Journaled write completed\n");
}
/*
* Recovery after crash:
* 1. Scan journal for incomplete transactions
* 2. Replay committed transactions
* 3. Discard uncommitted transactions
*/
// Used in: ext4, XFS, NTFS, HFS+
12.12 File System Performance
/*
* Performance Optimizations:
*
* 1. Block Caching (Buffer Cache)
* 2. Read-ahead (Prefetching)
* 3. Write-behind (Delayed writes)
* 4. File System Check (fsck) minimization via journaling
*/
// Simple cache implementation
#define CACHE_SIZE 1024
typedef struct CacheEntry {
uint32_t block_num;
uint8_t data[BLOCK_SIZE];
bool dirty;
time_t last_access;
} CacheEntry;
CacheEntry cache[CACHE_SIZE];
uint8_t* read_block_cached(uint32_t block_num) {
// Check cache first
for (int i = 0; i < CACHE_SIZE; i++) {
if (cache[i].block_num == block_num) {
cache[i].last_access = time(NULL);
printf("Cache HIT: block %d\n", block_num);
return cache[i].data;
}
}
// Cache miss - read from disk
printf("Cache MISS: block %d\n", block_num);
// Find LRU entry to evict
int lru_idx = find_lru_cache_entry();
// Write back if dirty
if (cache[lru_idx].dirty) {
write_block_to_disk(cache[lru_idx].block_num, cache[lru_idx].data);
}
// Load new block
read_block_from_disk(block_num, cache[lru_idx].data);
cache[lru_idx].block_num = block_num;
cache[lru_idx].dirty = false;
cache[lru_idx].last_access = time(NULL);
return cache[lru_idx].data;
}Key Takeaways
File System Essentials:
- File systems organize data on persistent storage with hierarchical structure → Essential for data management
- Unix inode separates metadata from filename (allows hard links) → Enables flexible file organization
- Allocation methods: Contiguous (fast but fragmented), Linked (flexible but slow), Indexed (balanced) → Choose based on access patterns
- VFS provides uniform interface for different filesystem types → Mount ext4, FAT32, NFS seamlessly
- Free space management: Bitmap (fast), Linked list (space-efficient), Grouping (hybrid) → ext4 uses bitmaps
- Unix permissions: 9 bits (rwx for owner/group/others)** → Foundational security model
- Journaling ensures filesystem consistency after crashes → Metadata or full journaling
- Caching critical for performance (buffer cache, read-ahead) → Reduces disk I/O dramatically
13. I/O Management
13.1 I/O Subsystem Overview
The I/O subsystem manages communication between CPU and peripheral devices.
/*
* I/O Components:
* 1. CPU: Initiates I/O operations
* 2. Controller: Device-specific interface
* 3. Device: Physical peripheral
* 4. Bus/Channel: Communication pathway
*/
typedef struct {
uint8_t status; // Device status
uint16_t control; // Control signals
uint32_t data_register; // Data buffer
} IODevice;
/*
* Device Controller:
* - Handles protocol specifics
* - Manages data transfers
* - Signals completion to CPU
*/
typedef struct {
uint16_t status_register; // Device status
uint16_t control_register; // Commands
uint32_t data_port; // Data transfers
uint32_t address_register; // Memory address for DMA
} DeviceController;13.2 I/O Techniques
13.2.1 Programmed I/O (Polling)
/*
* Programmed I/O (Polling):
* CPU continuously checks device status
*
* Pros: Simple implementation
* Cons: CPU wastes cycles waiting (busy-waiting)
*/
#define DEVICE_STATUS 0x1000
#define DEVICE_DATA 0x1004
#define DEVICE_BUSY 0x01
#define DEVICE_READY 0x02
// Polling approach
void read_data_polling() {
// Wait for device to be ready
while ((inb(DEVICE_STATUS) & DEVICE_READY) == 0) {
// Busy wait - CPU does nothing useful
}
// Read data
uint8_t data = inb(DEVICE_DATA);
printf("Read: 0x%02X\n", data);
}
void write_data_polling(uint8_t data) {
// Wait for device to not be busy
while ((inb(DEVICE_STATUS) & DEVICE_BUSY) != 0) {
// Busy wait
}
// Write data
outb(DEVICE_DATA, data);
printf("Wrote: 0x%02X\n", data);
}
/*
* Polling pseudocode:
* while (device_busy) ; // Wait (wastes CPU cycles)
* read_data() // Get data from port
*/13.2.2 Interrupt-Driven I/O
/*
* Interrupt-Driven I/O:
* Device signals CPU when ready (via interrupt)
* CPU context switches to handler
*
* Pros: CPU not wasting cycles
* Cons: Higher overhead per interrupt
*/
volatile uint8_t data_received = 0;
// Interrupt handler (Interrupt Service Routine - ISR)
void device_interrupt_handler() {
printf("Interrupt received!\n");
// Read data from device
data_received = inb(DEVICE_DATA);
// Clear interrupt flag
outb(DEVICE_CONTROL, 0x00);
printf("Data: 0x%02X\n", data_received);
// Return to interrupted code
}
void read_data_interrupt() {
// Enable interrupts for this device
outb(DEVICE_CONTROL, 0x01);
// Wait for data (using sleep or event)
sleep(5); // Timeout after 5 seconds
// Data now available in data_received
printf("Data available: 0x%02X\n", data_received);
}
/*
* Interrupt Processing:
* 1. Device signals interrupt
* 2. CPU saves current state
* 3. CPU jumps to interrupt handler
* 4. Handler processes device
* 5. Handler clears interrupt
* 6. CPU restores state and continues
*/13.2.3 Direct Memory Access (DMA)
/*
* DMA: Device transfers data directly to memory
* CPU not involved in each byte transfer
*
* Pros: Minimal CPU overhead, fast transfers
* Cons: Complex implementation, requires DMA controller
*/
typedef struct {
uint32_t source_address; // Device address
uint32_t dest_address; // Memory address
uint32_t transfer_count; // Number of bytes
uint8_t direction; // Read/Write
uint8_t control; // Enable, interrupt on complete
} DMARequest;
// DMA Channel descriptor
typedef struct {
uint32_t memory_address;
uint32_t transfer_count;
uint8_t control; // Enable, interrupt flag
uint8_t status; // Complete flag
} DMAChannel;
// Initialize DMA transfer
void setup_dma_read(uint32_t device_addr, uint32_t mem_addr, uint32_t bytes) {
// Set up DMA channel
DMAChannel *dma = (DMAChannel *)0x8000; // DMA controller base address
dma->memory_address = mem_addr;
dma->transfer_count = bytes;
dma->control = 0x01; // Enable DMA
// Device starts transfer, DMA controller handles it
printf("DMA transfer initiated: %d bytes from 0x%X to 0x%X\n",
bytes, device_addr, mem_addr);
}
// DMA completion interrupt
void dma_completion_handler() {
DMAChannel *dma = (DMAChannel *)0x8000;
if (dma->status & 0x01) {
printf("DMA transfer complete!\n");
// Process transferred data...
}
}
/*
* DMA Advantages:
* - CPU free to do other work
* - Fast bulk transfers
* - Multiple DMA channels for concurrent transfers
*/13.3 Disk Scheduling Algorithms
When multiple I/O requests queued, choose order to minimize seek time.
13.3.1 FCFS (First-Come-First-Served)
/*
* FCFS: Service requests in order received
* Pros: Fair, simple
* Cons: High average seek time (disk may jump around)
*/
#define DISK_TRACKS 200
#define QUEUE_SIZE 32
typedef struct {
int track;
int id;
} DiskRequest;
void disk_schedule_fcfs(DiskRequest queue[], int queue_size) {
int current_track = 0;
int total_seek = 0;
printf("=== FCFS Disk Scheduling ===\n");
for (int i = 0; i < queue_size; i++) {
int seek = abs(queue[i].track - current_track);
total_seek += seek;
printf("Request %d: Track %d (seek: %d)\n",
queue[i].id, queue[i].track, seek);
current_track = queue[i].track;
}
printf("Total head movement: %d tracks\n", total_seek);
}
// Example: Queue = [98, 183, 37, 122, 14, 165, 30, 85]
// FCFS movement: 0->98 (98) ->183 (85) ->37 (146) ->122 (85) ->14 (108) ->165 (151) ->30 (135) ->85 (55) = 863
13.3.2 SSTF (Shortest Seek Time First)
/*
* SSTF: Serve closest request next
* Pros: Lower seek time than FCFS
* Cons: Starvation possible (outer tracks if inner always busy)
*/
void disk_schedule_sstf(DiskRequest queue[], int queue_size) {
bool served[QUEUE_SIZE] = {false};
int current_track = 0;
int total_seek = 0;
printf("=== SSTF Disk Scheduling ===\n");
for (int i = 0; i < queue_size; i++) {
// Find closest unserved request
int next_idx = -1;
int min_seek = INT_MAX;
for (int j = 0; j < queue_size; j++) {
if (!served[j]) {
int seek = abs(queue[j].track - current_track);
if (seek < min_seek) {
min_seek = seek;
next_idx = j;
}
}
}
served[next_idx] = true;
total_seek += min_seek;
printf("Request %d: Track %d (seek: %d)\n",
queue[next_idx].id, queue[next_idx].track, min_seek);
current_track = queue[next_idx].track;
}
printf("Total head movement: %d tracks\n", total_seek);
}
// Same queue: [98, 183, 37, 122, 14, 165, 30, 85]
// SSTF movement: 0->30 (30) ->37 (7) ->85 (48) ->98 (13) ->122 (24) ->165 (43) ->183 (18) ->14 (169) = 352
13.3.3 SCAN (Elevator Algorithm)
/*
* SCAN: Head moves in one direction, serves requests, then reverses
* Pros: Fair, prevents starvation, good for heavy load
* Cons: Slightly higher seek time than SSTF
*/
void disk_schedule_scan(DiskRequest queue[], int queue_size) {
bool served[QUEUE_SIZE] = {false};
int current_track = 0;
int total_seek = 0;
int direction = 1; // 1 = towards higher tracks, -1 = towards lower
printf("=== SCAN (Elevator) Disk Scheduling ===\n");
for (int i = 0; i < queue_size; i++) {
// Find closest request in current direction
int next_idx = -1;
int best_track = -1;
for (int j = 0; j < queue_size; j++) {
if (!served[j]) {
int track = queue[j].track;
// Check if in current direction
if ((direction > 0 && track >= current_track) ||
(direction < 0 && track <= current_track)) {
// Find closest in direction
if (best_track == -1 ||
(direction > 0 && track < best_track) ||
(direction < 0 && track > best_track)) {
best_track = track;
next_idx = j;
}
}
}
}
// If no request in current direction, reverse
if (next_idx == -1) {
direction *= -1; // Reverse direction
// Find closest in new direction
for (int j = 0; j < queue_size; j++) {
if (!served[j]) {
best_track = queue[j].track;
next_idx = j;
break;
}
}
}
served[next_idx] = true;
int seek = abs(queue[next_idx].track - current_track);
total_seek += seek;
printf("Request %d: Track %d (seek: %d, direction: %s)\n",
queue[next_idx].id, queue[next_idx].track, seek,
direction > 0 ? "up" : "down");
current_track = queue[next_idx].track;
}
printf("Total head movement: %d tracks\n", total_seek);
}13.3.4 C-SCAN (Circular SCAN)
/*
* C-SCAN: After reaching end, jump to start and scan again
* Pros: More uniform seek time distribution
* Cons: Higher seek time for first few tracks after reversal
*/
void disk_schedule_c_scan(DiskRequest queue[], int queue_size) {
bool served[QUEUE_SIZE] = {false};
int current_track = 0;
int total_seek = 0;
printf("=== C-SCAN Disk Scheduling ===\n");
for (int i = 0; i < queue_size; i++) {
// Find closest request >= current_track
int next_idx = -1;
int best_track = INT_MAX;
for (int j = 0; j < queue_size; j++) {
if (!served[j] && queue[j].track >= current_track) {
if (queue[j].track < best_track) {
best_track = queue[j].track;
next_idx = j;
}
}
}
// If none found, wrap to start
if (next_idx == -1) {
best_track = INT_MAX;
for (int j = 0; j < queue_size; j++) {
if (!served[j]) {
if (queue[j].track < best_track) {
best_track = queue[j].track;
next_idx = j;
}
}
}
}
served[next_idx] = true;
int seek = abs(queue[next_idx].track - current_track);
total_seek += seek;
printf("Request %d: Track %d (seek: %d)\n",
queue[next_idx].id, queue[next_idx].track, seek);
current_track = queue[next_idx].track;
}
printf("Total head movement: %d tracks\n", total_seek);
}13.4 Disk Scheduling Comparison
Disk Scheduling Trade-offs:
- FCFS: Fair but causes excessive head movement (thrashing) → Poor for workstations
- SSTF: Minimizes seeks but starves outer tracks → Risky for critical data
- SCAN/C-SCAN: Balanced fairness and performance → Best for most systems (recommended)
- LOOK: Practical SCAN variant → Similar performance to SCAN
| Algorithm | Avg Seek Time | Starvation | Implementation | Notes |
|---|---|---|---|---|
| FCFS | High | No | Simple | Fair but inefficient |
| SSTF | Low-Medium | Yes | Medium | Good but can starve outer tracks |
| SCAN | Medium | No | Complex | Fair and good under heavy load |
| C-SCAN | Medium | No | Complex | More uniform service |
| LOOK | Low-Medium | No | Complex | Like SCAN but doesn’t go to end |
13.5 Interrupt Handling
/*
* Interrupt Levels (Interrupt Request - IRQ)
* x86 PC: 16 IRQs (IRQ0-15)
* - IRQ0: System timer
* - IRQ1: Keyboard
* - IRQ8: Real-time clock
* - IRQ14-15: IDE disk controllers
*/
// Interrupt Descriptor Table (IDT) entry
typedef struct {
uint16_t offset_low; // Lower 16 bits of handler address
uint16_t selector; // Code segment selector
uint8_t reserved;
uint8_t type; // Gate type (trap, interrupt)
uint16_t offset_high; // Upper 16 bits of handler address
} IDTEntry;
#define IDT_SIZE 256
IDTEntry idt[IDT_SIZE];
// Register interrupt handler
void register_interrupt_handler(int irq, void (*handler)(void)) {
uint32_t handler_addr = (uint32_t)handler;
idt[irq].offset_low = handler_addr & 0xFFFF;
idt[irq].offset_high = (handler_addr >> 16) & 0xFFFF;
idt[irq].selector = 0x08; // Kernel code segment
idt[irq].type = 0x8E; // 32-bit interrupt gate
printf("Registered handler for IRQ%d at 0x%X\n", irq, handler_addr);
}
// Interrupt context (saved CPU state)
typedef struct {
uint32_t edi, esi, ebp, esp;
uint32_t ebx, edx, ecx, eax;
uint32_t ds, es, fs, gs;
uint32_t error_code;
uint32_t eip;
uint32_t cs;
uint32_t eflags;
} InterruptContext;
// Generic interrupt handler wrapper
void generic_interrupt_handler(InterruptContext *ctx) {
printf("Interrupt at 0x%X, Error: 0x%X\n", ctx->eip, ctx->error_code);
// Acknowledge interrupt to PIC (Programmable Interrupt Controller)
outb(0x20, 0x20); // Send EOI to master PIC
// Call appropriate handler based on interrupt number...
}Key Takeaways
I/O Management Principles:
- I/O Techniques: Polling (simple, wasteful), Interrupts (efficient), DMA (best for bulk transfers)** → Use DMA for high throughput
- Disk Scheduling: FCFS (fair, high seek), SSTF (low seek, starvation), SCAN (fair, medium seek)** → SCAN is production standard
- Interrupt Handling: Device signals CPU via interrupt, handler processes request** → Minimize handler time
- Performance depends on workload and device characteristics → Profile before optimizing
14. System Calls and Interrupts
14.1 System Calls Basics
System calls are the interface between user programs and the OS kernel, providing controlled access to hardware and kernel services.
/*
* System Call Execution Flow:
* 1. User program calls system call wrapper
* 2. Arguments loaded into CPU registers/stack
* 3. Trap instruction (int 0x80 on x86)
* 4. CPU switches to kernel mode
* 5. Kernel handles request
* 6. Return to user mode with result
*
* Context Switch Cost: Very expensive!
*/
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
// System calls frequently used in Unix/Linux
int fd = open("file.txt", O_RDONLY); // open() syscall
ssize_t n = read(fd, buf, 100); // read() syscall
ssize_t m = write(1, "hello", 5); // write() syscall
close(fd); // close() syscall
pid_t pid = fork(); // fork() syscall
execve("/bin/ls", argv, env); // execve() syscall
int status;
wait(&status); // wait() syscall
14.2 Mode Switching: User to Kernel
/*
* User Mode vs Kernel Mode
*
* User Mode:
* - Limited privileges
* - Can't access hardware directly
* - Can't modify memory protection
* - Must use syscalls for privileged operations
*
* Kernel Mode:
* - Full privileges
* - Direct hardware access
* - Can modify CPU registers
* - Can access all memory
*/
// x86 Privilege Levels (Rings):
// Ring 0: Kernel (highest privilege)
// Ring 1, 2: Rarely used
// Ring 3: User (lowest privilege)
typedef struct {
uint32_t eax, ebx, ecx, edx;
uint32_t esi, edi, ebp, esp;
uint32_t eip; // Instruction pointer
uint32_t cs; // Code segment (determines privilege)
uint32_t eflags; // Flags register
uint32_t ss; // Stack segment
} CPUState;
/*
* Switching from User to Kernel:
* 1. User executes "int 0x80" (software interrupt on x86)
* 2. CPU changes to kernel mode
* 3. Kernel trap handler takes over
* 4. Kernel executes requested syscall
* 5. "iret" instruction returns to user mode
*/14.3 Exception and Trap Handling
/*
* Exceptions: Internal CPU events (errors, traps)
* Examples: Division by zero, page fault, invalid opcode
*
* Traps: Intentional exceptions used for syscalls
*/
// x86 Exception Types
#define EXC_DIVIDE_BY_ZERO 0 // Division by zero
#define EXC_DEBUG 1 // Debugger breakpoint
#define EXC_NMI 2 // Non-maskable interrupt
#define EXC_BREAKPOINT 3 // Breakpoint trap
#define EXC_OVERFLOW 4 // Signed overflow
#define EXC_BOUNDS 5 // Bounds check
#define EXC_INVALID_OP 6 // Invalid opcode
#define EXC_NO_MATH_COPROC 7 // Math coprocessor not available
#define EXC_DOUBLE_FAULT 8 // Exception during exception
#define EXC_SEGMENT_OVERRUN 9 // Segment overrun
#define EXC_BAD_TSS 10 // Invalid Task State Segment
#define EXC_SEGMENT_NOT_PRES 11 // Segment not present
#define EXC_STACK_FAULT 12 // Stack segment fault
#define EXC_GEN_PROTECT_FAULT 13 // General protection fault
#define EXC_PAGE_FAULT 14 // Page fault
#define EXC_RESERVED 15 // Reserved
#define EXC_MATH_FAULT 16 // Floating point error
#define EXC_ALIGNMENT_CHECK 17 // Alignment check
// Exception handler
void exception_handler(int exc_number, InterruptContext *ctx) {
switch (exc_number) {
case EXC_DIVIDE_BY_ZERO:
printf("Division by zero at 0x%X\n", ctx->eip);
signal_process(ctx->process_id, SIGFPE); // Floating point exception
break;
case EXC_PAGE_FAULT:
printf("Page fault at 0x%X\n", ctx->eip);
// Try to handle page fault
if (handle_page_fault(ctx->cr2)) { // CR2 contains faulting address
return; // Handled successfully
}
signal_process(ctx->process_id, SIGSEGV); // Segmentation violation
break;
case EXC_GEN_PROTECT_FAULT:
printf("General protection fault at 0x%X\n", ctx->eip);
signal_process(ctx->process_id, SIGSEGV);
break;
default:
printf("Unhandled exception %d at 0x%X\n", exc_number, ctx->eip);
signal_process(ctx->process_id, SIGABRT); // Abort
}
}14.4 System Call Implementation
/*
* System Call Dispatch
* Kernel maintains table of system call handlers
*/
#define MAX_SYSCALLS 512
typedef long (*syscall_handler_t)(long arg1, long arg2, long arg3,
long arg4, long arg5, long arg6);
syscall_handler_t syscall_table[MAX_SYSCALLS] = {
[0] = sys_read,
[1] = sys_write,
[2] = sys_open,
[3] = sys_close,
[4] = sys_stat,
// ... many more syscalls
[11] = sys_execve,
[20] = sys_getpid,
[39] = sys_mkdir,
// ... up to 512 syscalls on modern Linux
};
// Syscall entry point (assembly calls this)
long syscall_dispatcher(long syscall_number, long arg1, long arg2,
long arg3, long arg4, long arg5, long arg6) {
if (syscall_number >= MAX_SYSCALLS) {
return -ENOSYS; // Function not implemented
}
syscall_handler_t handler = syscall_table[syscall_number];
if (!handler) {
return -ENOSYS;
}
// Call the actual syscall handler
return handler(arg1, arg2, arg3, arg4, arg5, arg6);
}
// Example: sys_write implementation
long sys_write(long fd, long buffer, long count, long arg4, long arg5, long arg6) {
// Validate file descriptor
if (fd < 0 || fd >= MAX_FDS) {
return -EBADF; // Bad file descriptor
}
// Validate buffer is in user space
if (!is_user_memory((void *)buffer, count)) {
return -EFAULT; // Bad address
}
OpenFile *file = current_process->file_descriptors[fd];
if (!file) {
return -EBADF;
}
// Check write permissions
if (!file->writable) {
return -EACCES; // Permission denied
}
// Perform the write
ssize_t written = file->write(file, (void *)buffer, count);
return written;
}
// Example: sys_read implementation
long sys_read(long fd, long buffer, long count, long arg4, long arg5, long arg6) {
if (fd < 0 || fd >= MAX_FDS) {
return -EBADF;
}
if (!is_user_memory((void *)buffer, count)) {
return -EFAULT;
}
OpenFile *file = current_process->file_descriptors[fd];
if (!file) {
return -EBADF;
}
if (!file->readable) {
return -EACCES;
}
ssize_t bytes_read = file->read(file, (void *)buffer, count);
return bytes_read;
}
// Example: sys_fork implementation
long sys_fork(long arg1, long arg2, long arg3, long arg4, long arg5, long arg6) {
Process *current = get_current_process();
// Allocate new process structure
Process *child = allocate_process();
if (!child) {
return -ENOMEM; // No memory
}
// Copy process image (or use COW)
copy_process_image(current, child);
// Set parent-child relationship
child->parent_pid = current->pid;
child->ppid = current->pid;
// Add to process list
add_to_process_list(child);
// In parent: return child PID
// In child: this is handled by returning 0 to child
return child->pid;
}
// Example: sys_exit implementation
long sys_exit(long exit_code, long arg2, long arg3, long arg4, long arg5, long arg6) {
Process *current = get_current_process();
// Store exit code
current->exit_code = exit_code;
current->state = PROCESS_ZOMBIE;
// Close all file descriptors
for (int i = 0; i < MAX_FDS; i++) {
if (current->file_descriptors[i]) {
sys_close(i, 0, 0, 0, 0, 0);
}
}
// Free memory pages
free_process_memory(current);
// Wake up parent if waiting
if (current->parent_pid != 0) {
Process *parent = get_process_by_pid(current->parent_pid);
if (parent && parent->state == PROCESS_WAITING) {
parent->state = PROCESS_READY;
}
}
// Schedule next process
schedule_next();
return 0; // Never returns
}14.5 Virtual System Call (vsyscall)
/*
* vsyscall: Virtual system call (fast path for common syscalls)
* Avoids context switch overhead for frequently-used syscalls
* Mapped to user space (read-only)
* Used for: gettimeofday, clock_gettime, getcpu
*/
// vsyscall page mapped at fixed address (typically 0xFFFFE000)
#define VSYSCALL_ADDR 0xFFFFE000
typedef struct {
int (*gettimeofday)(struct timeval *tv, struct timezone *tz);
long (*clock_gettime)(clockid_t clock_id, struct timespec *tp);
int (*getcpu)(unsigned *cpu, unsigned *node);
} vsyscall_functions_t;
// User program can call without context switch
time_t fast_gettimeofday() {
vsyscall_functions_t *vsyscall = (vsyscall_functions_t *)VSYSCALL_ADDR;
struct timeval tv;
vsyscall->gettimeofday(&tv, NULL);
return tv.tv_sec;
}
/*
* Replaced by vDSO (Virtual Dynamic Shared Object) in modern Linux
* vDSO: Kernel-provided shared library
* Functions: clock_gettime, gettimeofday, clock_nanosleep
* Advantages:
* - Faster than vsyscall
* - More secure (randomized)
* - Easy to upgrade
*/14.6 Comparison: User vs Kernel Mode Operations
| Operation | User Mode | Kernel Mode |
|---|---|---|
| Direct memory access | Limited (own pages only) | Unrestricted (all pages) |
| I/O operations | Via syscalls | Direct |
| CPU register access | Limited | Full |
| Mode switching | No (need syscall) | Can switch to user |
| Performance | Slower (syscall overhead) | Faster (direct) |
| Safety | Protected (isolated) | Privileged (risky) |
Key Takeaways - System Calls
System Calls Bridge User and Kernel Worlds:
- System calls provide controlled interface to kernel services → Sandboxed access to hardware
- Mode switch (user to kernel) involves context save/restore → Expensive! (100s of cycles)
- Syscall dispatch uses lookup table indexed by syscall number → Fast lookup via syscall table
- vDSO/vsyscall optimize frequent low-overhead syscalls → gettimeofday(), clock_gettime() avoid mode switch
- Exceptions handle errors and traps within kernel → Division by zero, page faults, etc.
15. Inter-Process Communication (IPC)
15.1 IPC Overview
Processes need to communicate and synchronize. IPC mechanisms provide this.
/*
* IPC Types:
* 1. Pipes & FIFOs
* 2. Message Queues
* 3. Shared Memory
* 4. Sockets
* 5. Signals
* 6. Semaphores
*/15.2 Pipes and Named Pipes (FIFOs)
/*
* Pipe: Unidirectional communication channel
* - Created by pipe() syscall
* - Buffered (4096 bytes typically)
* - Used for parent-child communication
*/
#include <unistd.h>
void pipe_example() {
int pipefd[2]; // pipefd[0] = read end, pipefd[1] = write end
if (pipe(pipefd) == -1) {
perror("pipe");
return;
}
pid_t pid = fork();
if (pid == 0) {
// Child process
close(pipefd[1]); // Close write end
char buffer[100];
ssize_t n = read(pipefd[0], buffer, sizeof(buffer));
printf("Child received: %.*s\n", (int)n, buffer);
close(pipefd[0]);
exit(0);
} else {
// Parent process
close(pipefd[0]); // Close read end
const char *msg = "Hello from parent";
write(pipefd[1], msg, strlen(msg));
close(pipefd[1]);
wait(NULL);
}
}
/*
* Named Pipe (FIFO):
* - Persistent named pipe
* - Created with mkfifo()
* - Can be opened by unrelated processes
*/
#include <sys/stat.h>
#include <fcntl.h>
void fifo_example() {
// Create FIFO
mkfifo("/tmp/myfifo", 0666);
// Writer process
if (fork() == 0) {
int fd = open("/tmp/myfifo", O_WRONLY);
write(fd, "Data", 4);
close(fd);
exit(0);
}
// Reader process
int fd = open("/tmp/myfifo", O_RDONLY);
char buffer[10];
read(fd, buffer, 4);
printf("Received: %.4s\n", buffer);
close(fd);
unlink("/tmp/myfifo");
}15.3 Message Queues
/*
* Message Queue: POSIX IPC mechanism
* - Persistent (survives process termination)
* - Multiple senders/receivers
* - Messages have types
*/
#include <mqueue.h>
#include <string.h>
typedef struct {
long mtype;
char mtext[256];
} Message;
void message_queue_example() {
struct mq_attr attr = {
.mq_flags = 0,
.mq_maxmsg = 10,
.mq_msgsize = sizeof(Message),
};
// Create message queue
mqd_t mq = mq_open("/myqueue", O_CREAT | O_RDWR, 0666, &attr);
if (mq == (mqd_t)-1) {
perror("mq_open");
return;
}
// Producer: Send message
if (fork() == 0) {
Message msg = {
.mtype = 1,
};
strcpy(msg.mtext, "Hello from producer");
if (mq_send(mq, (const char *)&msg, sizeof(msg), 0) == -1) {
perror("mq_send");
}
mq_close(mq);
exit(0);
}
// Consumer: Receive message
Message msg;
if (mq_receive(mq, (char *)&msg, sizeof(msg), NULL) == -1) {
perror("mq_receive");
}
printf("Received: type=%ld, text=%s\n", msg.mtype, msg.mtext);
mq_close(mq);
mq_unlink("/myqueue");
}15.4 Shared Memory
/*
* Shared Memory: Fast IPC (no copying)
* - Multiple processes access same memory region
* - Requires synchronization (mutex/semaphore)
* - Linux: System V IPC or POSIX shm
*/
#include <sys/ipc.h>
#include <sys/shm.h>
#include <string.h>
typedef struct {
int counter;
char data[256];
pthread_mutex_t lock;
} SharedData;
void shared_memory_example() {
key_t key = ftok("/tmp", 'S'); // Create unique key
// Create or get shared memory segment
int shmid = shmget(key, sizeof(SharedData), IPC_CREAT | 0666);
if (shmid == -1) {
perror("shmget");
return;
}
// Attach to process address space
SharedData *shared = (SharedData *)shmat(shmid, NULL, 0);
if (shared == (void *)-1) {
perror("shmat");
return;
}
// Initialize on first use
static int initialized = 0;
if (!initialized) {
memset(shared, 0, sizeof(SharedData));
pthread_mutex_init(&shared->lock, NULL);
initialized = 1;
}
// Multiple processes can access
pthread_mutex_lock(&shared->lock);
shared->counter++;
strcpy(shared->data, "Shared data");
pthread_mutex_unlock(&shared->lock);
printf("Counter: %d, Data: %s\n", shared->counter, shared->data);
// Detach from memory
shmdt(shared);
// Only last process to detach should delete
// shmctl(shmid, IPC_RMID, NULL);
}15.5 Sockets
/*
* Sockets: Network IPC (local and remote)
* - Unix domain sockets: Local machine only
* - Network sockets: TCP/IP over network
*/
#include <sys/socket.h>
#include <sys/un.h>
#include <netinet/in.h>
#include <string.h>
// Unix domain socket server
void unix_socket_server() {
int sockfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("socket");
return;
}
struct sockaddr_un addr = {
.sun_family = AF_UNIX,
};
strcpy(addr.sun_path, "/tmp/server.sock");
// Remove old socket file if exists
unlink(addr.sun_path);
if (bind(sockfd, (struct sockaddr *)&addr, sizeof(addr)) == -1) {
perror("bind");
return;
}
if (listen(sockfd, 1) == -1) {
perror("listen");
return;
}
printf("Server listening on /tmp/server.sock\n");
struct sockaddr_un peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int connfd = accept(sockfd, (struct sockaddr *)&peer_addr, &peer_addr_len);
if (connfd == -1) {
perror("accept");
return;
}
char buffer[256];
ssize_t n = recv(connfd, buffer, sizeof(buffer), 0);
printf("Received: %.*s\n", (int)n, buffer);
close(connfd);
close(sockfd);
}
// Unix domain socket client
void unix_socket_client() {
int sockfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("socket");
return;
}
struct sockaddr_un addr = {
.sun_family = AF_UNIX,
};
strcpy(addr.sun_path, "/tmp/server.sock");
if (connect(sockfd, (struct sockaddr *)&addr, sizeof(addr)) == -1) {
perror("connect");
return;
}
const char *msg = "Hello from client";
send(sockfd, msg, strlen(msg), 0);
close(sockfd);
}
// TCP socket (network)
void tcp_socket_server(int port) {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_port = htons(port),
.sin_addr.s_addr = htonl(INADDR_ANY),
};
int opt = 1;
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
bind(sockfd, (struct sockaddr *)&addr, sizeof(addr));
listen(sockfd, 5);
printf("Server listening on port %d\n", port);
struct sockaddr_in client_addr;
socklen_t client_addr_len = sizeof(client_addr);
int connfd = accept(sockfd, (struct sockaddr *)&client_addr, &client_addr_len);
char buffer[256];
recv(connfd, buffer, sizeof(buffer), 0);
printf("Received: %s\n", buffer);
close(connfd);
close(sockfd);
}15.6 Signals
/*
* Signals: Asynchronous notifications
* - Limited information (only signal number)
* - Can interrupt process execution
* - Common signals: SIGTERM, SIGKILL, SIGCHLD
*/
#include <signal.h>
void signal_handler(int sig) {
switch (sig) {
case SIGTERM:
printf("Received SIGTERM (terminate)\n");
exit(0);
case SIGINT:
printf("Received SIGINT (interrupt, Ctrl+C)\n");
exit(0);
case SIGCHLD:
printf("Child process terminated\n");
break;
case SIGUSR1:
printf("Received SIGUSR1 (user-defined)\n");
break;
}
}
void signal_example() {
// Register signal handler
signal(SIGTERM, signal_handler);
signal(SIGINT, signal_handler);
signal(SIGCHLD, signal_handler);
signal(SIGUSR1, signal_handler);
printf("Process %d waiting for signals...\n", getpid());
// Infinite loop, waiting for signals
while (1) {
pause(); // Wait for signal
}
}
// Send signal to process
void send_signal_example() {
pid_t target_pid = 1234;
// Send SIGUSR1
if (kill(target_pid, SIGUSR1) == -1) {
perror("kill");
}
}
// Signal mask (block/unblock signals)
void signal_mask_example() {
sigset_t set;
// Create set with SIGTERM
sigemptyset(&set);
sigaddset(&set, SIGTERM);
// Block SIGTERM
if (sigprocmask(SIG_BLOCK, &set, NULL) == -1) {
perror("sigprocmask");
}
printf("SIGTERM is now blocked\n");
// Unblock SIGTERM
if (sigprocmask(SIG_UNBLOCK, &set, NULL) == -1) {
perror("sigprocmask");
}
printf("SIGTERM is now unblocked\n");
}15.7 IPC Comparison
| Mechanism | Speed | Persistence | Relationship | Use Case |
|---|---|---|---|---|
| Pipe | Very Fast | No | Parent-child | Simple stream |
| FIFO | Fast | Yes | Unrelated | Named pipe |
| Message Queue | Medium | Yes | Any | Asynchronous messages |
| Shared Memory | Fastest | Yes | Any | High-speed data sharing |
| Socket | Medium | No | Any (network) | Network communication |
| Signal | Very Fast | No | Any | Event notification |
Key Takeaways - IPC
Choosing the Right IPC Mechanism:
- Pipes: Simple, unidirectional, parent-child only → Use for process pipelines (ls | grep)
- Message Queues: Asynchronous, persistent, typed messages → Use for decoupled communication
- Shared Memory: Fastest but needs synchronization → Use for high-throughput data sharing
- Sockets: Flexible, supports local and network communication → Use for network services
- Signals: Lightweight but limited information → Use for event notifications
- Choose based on performance, persistence, and relationship needs → Profile your use case!
16. Security and Protection
16.1 Security Fundamentals
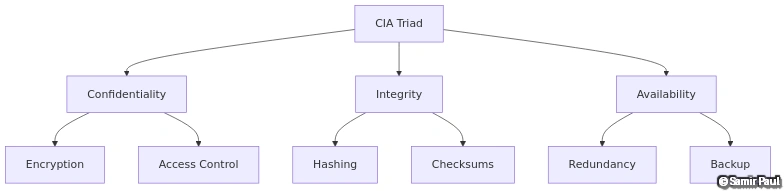
Figure 6: CIA Triad security model illustrating the three pillars of information security: Confidentiality (encryption, access control), Integrity (checksums, digital signatures), and Availability (redundancy, load balancing).
/*
* CIA Triad:
* - Confidentiality: Prevent unauthorized access
* - Integrity: Prevent unauthorized modification
* - Availability: Ensure authorized access
*/
// Security levels in operating systems
typedef enum {
SECURITY_NONE = 0,
SECURITY_LOW = 1,
SECURITY_MEDIUM = 2,
SECURITY_HIGH = 3,
SECURITY_TOP_SECRET = 4
} SecurityLevel;16.2 Authentication and Authorization
Figure 7: Authentication and authorization sequence diagram demonstrating user login, credential verification, session token generation, and resource access control.
/*
* Authentication: Verify identity (who are you?)
* Authorization: Check permissions (what can you do?)
*/
#include <string.h>
#include <crypt.h>
typedef struct {
char username[32];
char password_hash[128];
uid_t uid;
gid_t gid;
time_t last_login;
} UserAccount;
// Password authentication
bool authenticate_user(const char *username, const char *password) {
// Read user from /etc/shadow (simplified)
UserAccount user;
if (!get_user_account(username, &user)) {
return false;
}
// Hash the provided password
char *hash = crypt(password, user.password_hash);
// Compare with stored hash
if (strcmp(hash, user.password_hash) == 0) {
user.last_login = time(NULL);
update_user_account(&user);
return true;
}
return false;
}
// Multi-factor authentication
bool mfa_authenticate(const char *username, const char *password, const char *token) {
// First factor: password
if (!authenticate_user(username, password)) {
return false;
}
// Second factor: OTP token
if (!verify_otp_token(username, token)) {
return false;
}
return true;
}16.3 Access Control Models
16.3.1 Discretionary Access Control (DAC)
Figure 8: Discretionary Access Control (DAC) model where resource owners set permissions (rwx) for users, groups, and others, as implemented in Unix/Linux file systems.
/*
* DAC: Owner controls access to their resources
* Used in Unix/Linux file permissions
*/
// Unix permission structure
typedef struct {
uid_t owner_uid;
gid_t owner_gid;
mode_t permissions; // rwxrwxrwx
} DACPermissions;
bool check_dac_access(DACPermissions *perm, uid_t uid, gid_t gid, int access_mode) {
mode_t mode = perm->permissions;
// Root has all permissions
if (uid == 0) {
return true;
}
// Owner permissions
if (uid == perm->owner_uid) {
mode >>= 6; // Get owner bits
return (mode & access_mode) == access_mode;
}
// Group permissions
if (gid == perm->owner_gid) {
mode >>= 3; // Get group bits
mode &= 0x7;
return (mode & access_mode) == access_mode;
}
// Others permissions
mode &= 0x7;
return (mode & access_mode) == access_mode;
}
// Example: chmod command implementation
void change_permissions(const char *path, mode_t new_mode) {
// Verify caller is owner or root
struct stat st;
stat(path, &st);
if (getuid() != 0 && getuid() != st.st_uid) {
printf("Permission denied: not owner\n");
return;
}
// Change permissions
chmod(path, new_mode);
printf("Changed permissions to %o\n", new_mode);
}16.3.2 Mandatory Access Control (MAC)
Figure 9: Mandatory Access Control (MAC) system with hierarchical security labels (Top Secret, Secret, Confidential, Unclassified) and Bell-LaPadula model enforcing “No Read Up, No Write Down” rules.
/*
* MAC: System enforces security policy
* User cannot override (unlike DAC)
* Used in: SELinux, AppArmor
*/
typedef struct {
SecurityLevel classification;
char category[32];
bool need_to_know;
} MACLabel;
typedef struct {
SecurityLevel clearance;
char categories[10][32];
int num_categories;
} UserClearance;
// Bell-LaPadula Model: No read up, no write down
bool mac_can_read(UserClearance *user, MACLabel *object) {
// Can read if clearance >= classification
return user->clearance >= object->classification;
}
bool mac_can_write(UserClearance *user, MACLabel *object) {
// Can write if clearance <= classification
return user->clearance <= object->classification;
}
// SELinux-style context
typedef struct {
char user[32]; // SELinux user
char role[32]; // Role
char type[32]; // Type/Domain
char level[32]; // MLS level
} SELinuxContext;
bool selinux_check_access(SELinuxContext *subject,
SELinuxContext *object,
const char *permission) {
// Check against SELinux policy
// Simplified: check type enforcement
return selinux_policy_allows(subject->type, object->type, permission);
}16.3.3 Role-Based Access Control (RBAC)
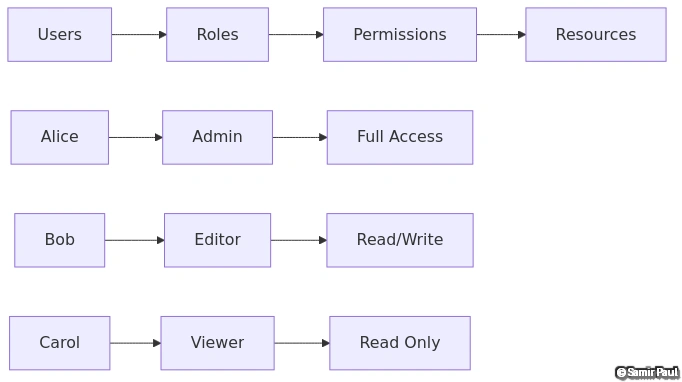
Figure 10: Role-Based Access Control (RBAC) architecture where users are assigned roles (Admin, Developer, Viewer) that determine their permissions to access organizational resources.
/*
* RBAC: Access based on user's role
* Simplifies management for large organizations
*/
typedef enum {
PERM_READ = 0x01,
PERM_WRITE = 0x02,
PERM_EXECUTE = 0x04,
PERM_DELETE = 0x08,
PERM_ADMIN = 0x10
} Permission;
typedef struct {
char role_name[32];
Permission permissions;
char resources[10][64];
int num_resources;
} Role;
typedef struct {
char username[32];
Role *roles[5];
int num_roles;
} User;
bool rbac_check_access(User *user, const char *resource, Permission required) {
// Check if any of user's roles grant the permission
for (int i = 0; i < user->num_roles; i++) {
Role *role = user->roles[i];
// Check if role has permission
if ((role->permissions & required) != required) {
continue;
}
// Check if role applies to this resource
for (int j = 0; j < role->num_resources; j++) {
if (strcmp(role->resources[j], resource) == 0) {
return true;
}
}
}
return false;
}
// Example: Database RBAC
void create_role_example() {
Role admin_role = {
.role_name = "Administrator",
.permissions = PERM_READ | PERM_WRITE | PERM_EXECUTE | PERM_DELETE | PERM_ADMIN,
.num_resources = 1
};
strcpy(admin_role.resources[0], "*"); // All resources
Role dev_role = {
.role_name = "Developer",
.permissions = PERM_READ | PERM_WRITE | PERM_EXECUTE,
.num_resources = 2
};
strcpy(dev_role.resources[0], "/code/*");
strcpy(dev_role.resources[1], "/docs/*");
}16.4 Encryption Basics
Figure 11: Encryption fundamentals comparing symmetric encryption (same key for encrypt/decrypt) and asymmetric encryption (public key for encryption, private key for decryption).
/*
* Encryption: Transform data to unreadable form
* Symmetric: Same key for encrypt/decrypt (AES, DES)
* Asymmetric: Public/Private key pair (RSA, ECC)
*/
#include <openssl/aes.h>
#include <openssl/rsa.h>
// Symmetric encryption (AES example)
void aes_encrypt(const unsigned char *plaintext, size_t len,
const unsigned char *key,
unsigned char *ciphertext) {
AES_KEY aes_key;
AES_set_encrypt_key(key, 256, &aes_key);
// Encrypt in ECB mode (simplified - use CBC/GCM in production)
for (size_t i = 0; i < len; i += 16) {
AES_encrypt(plaintext + i, ciphertext + i, &aes_key);
}
}
void aes_decrypt(const unsigned char *ciphertext, size_t len,
const unsigned char *key,
unsigned char *plaintext) {
AES_KEY aes_key;
AES_set_decrypt_key(key, 256, &aes_key);
for (size_t i = 0; i < len; i += 16) {
AES_decrypt(ciphertext + i, plaintext + i, &aes_key);
}
}
// Hash functions (one-way)
#include <openssl/sha.h>
void hash_password(const char *password, unsigned char *hash) {
SHA256_CTX ctx;
SHA256_Init(&ctx);
SHA256_Update(&ctx, password, strlen(password));
SHA256_Final(hash, &ctx);
}
// Example: Secure file storage
void secure_file_write(const char *filename, const unsigned char *data,
size_t len, const unsigned char *key) {
// Encrypt data
unsigned char *encrypted = malloc(len);
aes_encrypt(data, len, key, encrypted);
// Write to file
FILE *f = fopen(filename, "wb");
fwrite(encrypted, 1, len, f);
fclose(f);
free(encrypted);
}16.5 Common Security Vulnerabilities
Figure 12: Taxonomy of common security vulnerabilities in operating systems including buffer overflows, SQL injection, race conditions (TOCTOU), and privilege escalation exploits.
Common Security Vulnerabilities - Critical Patterns to Avoid
/*
* Common vulnerabilities and mitigations
*/
// 1. Buffer Overflow
void vulnerable_function(char *input) {
char buffer[100];
strcpy(buffer, input); // VULNERABLE! No bounds check
}
void safe_function(char *input) {
char buffer[100];
strncpy(buffer, input, sizeof(buffer) - 1); // Safe
buffer[sizeof(buffer) - 1] = '\0';
}
// 2. Race Condition (TOCTOU - Time of Check, Time of Use)
TOCTOU Race Condition: Between checking file permissions (TIME OF CHECK) and opening the file (TIME OF USE), an attacker can replace the file with a malicious symlink! This is a classic security vulnerability exploited in privilege escalation attacks.
void vulnerable_file_access(const char *filename) {
// Check if file is accessible
if (access(filename, R_OK) == 0) { // TIME OF CHECK
// Race condition window here!
FILE *f = fopen(filename, "r"); // TIME OF USE
// Attacker could replace file with symlink
}
}
void safe_file_access(const char *filename) {
// Open file and then check
int fd = open(filename, O_RDONLY | O_NOFOLLOW); // No symlinks
if (fd == -1) {
return;
}
struct stat st;
if (fstat(fd, &st) == 0) {
// Use file descriptor directly
}
close(fd);
}
// 3. Privilege Escalation Prevention
void drop_privileges() {
// Drop root privileges after initialization
uid_t real_uid = getuid();
gid_t real_gid = getgid();
// Drop supplementary groups
setgroups(0, NULL);
// Set GID first (must be done before UID)
setgid(real_gid);
setuid(real_uid);
// Verify privileges dropped
if (geteuid() == 0 || getegid() == 0) {
fprintf(stderr, "Failed to drop privileges!\n");
exit(1);
}
}16.6 Security in Modern OS
/*
* Modern OS Security Features
*/
// ASLR (Address Space Layout Randomization)
// Randomizes memory addresses to prevent exploits
void demonstrate_aslr() {
int stack_var;
int *heap_var = malloc(sizeof(int));
printf("Stack: %p\n", &stack_var);
printf("Heap: %p\n", heap_var);
// Addresses will be different each run with ASLR
}
// NX/DEP (No Execute / Data Execution Prevention)
// Marks memory pages as non-executable
// Prevents code injection attacks
// Seccomp (Secure Computing Mode)
// Restricts syscalls available to process
#include <sys/prctl.h>
#include <linux/seccomp.h>
void enable_seccomp_strict() {
// Allow only read, write, exit, sigreturn
prctl(PR_SET_SECCOMP, SECCOMP_MODE_STRICT);
// After this, any other syscall terminates process
}
// Namespaces (Isolation)
// Isolate process resources (used in containers)
void create_namespace() {
// Create new PID namespace
if (unshare(CLONE_NEWPID) == -1) {
perror("unshare");
return;
}
// Process now in isolated PID namespace
// PID 1 in this namespace
}Key Takeaways - Security
OS Security Fundamentals:
- CIA Triad: Confidentiality, Integrity, Availability → Three pillars of security
- Authentication: Verify identity (who you are) → Passwords, biometrics, MFA
- Authorization: Check permissions (what you can do) → Access control models
- DAC: Owner controls access (Unix permissions) → User-controlled, flexible
- MAC: System enforces policy (SELinux) → Centralized, stronger security
- RBAC: Role-based permissions (enterprise systems) → Scalable management
- Encryption: Symmetric (fast), Asymmetric (secure key exchange) → AES-256, RSA-2048
- Common vulnerabilities: Buffer overflow, race conditions, privilege escalation → Audit code regularly!
17. Unix/Linux Deep Dive
17.1 Unix/Linux Architecture
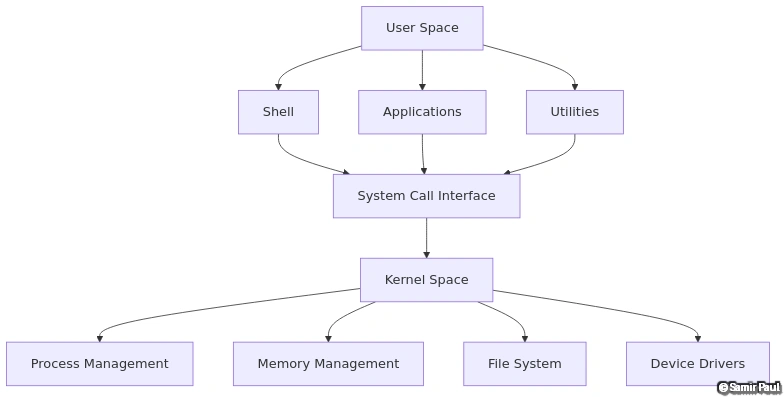
Figure 13: Unix/Linux operating system architecture illustrating user space (applications, shell, libraries) and kernel space (process management, memory management, file systems, device drivers, network stack) with system call interface as the boundary.
# Unix/Linux File System Hierarchy
/ # Root directory
├── bin/ # Essential user binaries
├── boot/ # Boot loader files
├── dev/ # Device files
├── etc/ # System configuration
├── home/ # User home directories
├── lib/ # System libraries
├── media/ # Removable media mount points
├── mnt/ # Temporary mount points
├── opt/ # Optional software
├── proc/ # Process information (virtual)
├── root/ # Root user home
├── run/ # Runtime data
├── sbin/ # System binaries
├── srv/ # Service data
├── sys/ # Kernel and system info (virtual)
├── tmp/ # Temporary files
├── usr/ # User programs
│ ├── bin/ # User binaries
│ ├── lib/ # User libraries
│ ├── local/ # Locally compiled software
│ └── share/ # Shared data
└── var/ # Variable data
├── log/ # Log files
├── mail/ # Mail
├── spool/ # Spool files
└── tmp/ # Temporary files (persists across reboots)17.2 Boot Process
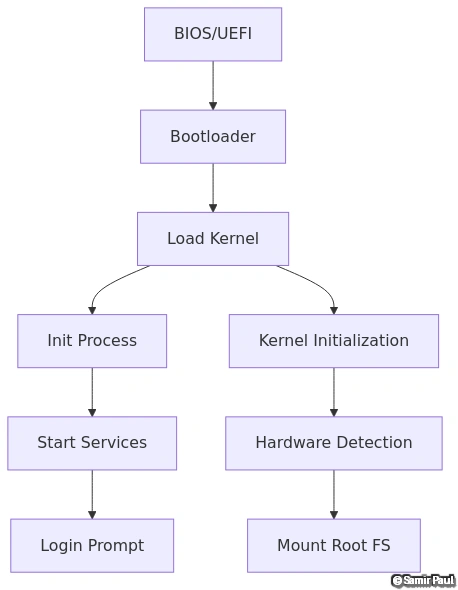
Figure 14: Unix/Linux boot process sequence diagram showing the complete boot chain from BIOS/UEFI → Bootloader (GRUB) → Kernel → Init (PID 1) → System Services startup.
# Boot process stages
# 1. BIOS/UEFI
# - Power-On Self Test (POST)
# - Initialize hardware
# - Load bootloader
# 2. Bootloader (GRUB)
# - Present menu
# - Load kernel and initramfs
# - Pass kernel parameters
# 3. Kernel initialization
# - Decompress kernel
# - Setup memory management
# - Mount root filesystem
# - Start init process
# 4. Init system (systemd/SysV)
# - Run startup scripts
# - Mount filesystems
# - Start services
# View boot messages
dmesg | less
# Check boot time
systemd-analyze
# See boot sequence
systemd-analyze critical-chain17.3 Shell and Command Line
#!/bin/bash
# ===================
# File Operations
# ===================
# List files
ls -la # Long format, all files
ls -lh # Human-readable sizes
ls -lt # Sort by modification time
ls -lS # Sort by size
# Navigate directories
cd /path/to/dir # Change directory
cd ~ # Go to home
cd - # Go to previous directory
pwd # Print working directory
# Copy, move, remove
cp file1 file2 # Copy file
cp -r dir1 dir2 # Copy directory recursively
mv old new # Move/rename
rm file # Remove file
rm -rf dir # Remove directory recursively (DANGEROUS!)
# Create directories
mkdir mydir # Create directory
mkdir -p a/b/c # Create nested directories
# File viewing
cat file # Display entire file
less file # Page through file
head -n 20 file # First 20 lines
tail -n 20 file # Last 20 lines
tail -f file # Follow file (for logs)
# ===================
# File Permissions
# ===================
# Permission format: rwxrwxrwx (owner group others)
# r=4, w=2, x=1
# Change permissions
chmod 755 script.sh # rwxr-xr-x
chmod u+x script.sh # Add execute for owner
chmod go-w file # Remove write for group/others
# Change ownership
chown user:group file # Change owner and group
chown -R user dir # Recursive
# View permissions
ls -l file
stat file # Detailed info
# Special permissions
chmod +t dir # Sticky bit (only owner can delete files)
chmod u+s program # Setuid (run as file owner)
chmod g+s program # Setgid (run as file group)
# ===================
# Process Management
# ===================
# View processes
ps aux # All processes
ps -ef # All processes (different format)
ps -u username # User's processes
top # Interactive process viewer
htop # Better top (if installed)
# Process tree
pstree # Show process hierarchy
pstree -p # Show PIDs
# Find process
pgrep firefox # Find PID by name
pidof firefox # Same as pgrep
# Kill process
kill PID # Send SIGTERM
kill -9 PID # Send SIGKILL (force)
killall firefox # Kill all firefox processes
pkill firefox # Kill by name
# Background jobs
command & # Run in background
jobs # List background jobs
fg %1 # Bring job 1 to foreground
bg %1 # Resume job 1 in background
disown %1 # Detach job from shell
# Process priority
nice -n 10 command # Start with lower priority
renice -n 5 -p PID # Change priority of running process
# ===================
# Finding Files
# ===================
# Find command
find /path -name "*.txt" # Find by name
find /path -type f # Find files
find /path -type d # Find directories
find /path -size +100M # Find large files
find /path -mtime -7 # Modified in last 7 days
find /path -user username # Find by owner
find /path -perm 755 # Find by permissions
# Execute command on found files
find /path -name "*.log" -exec rm {} \;
# Locate (faster, uses database)
locate filename
updatedb # Update locate database
# Which (find command in PATH)
which python
type python # Show command type17.4 Text Processing
#!/bin/bash
# ===================
# grep - Search text
# ===================
# Basic usage
grep "pattern" file # Search for pattern
grep -i "pattern" file # Case insensitive
grep -v "pattern" file # Invert match (show non-matching)
grep -r "pattern" dir # Recursive search
grep -n "pattern" file # Show line numbers
grep -c "pattern" file # Count matches
grep -l "pattern" files* # Show only filenames
grep -A 3 "pattern" file # Show 3 lines after match
grep -B 3 "pattern" file # Show 3 lines before match
grep -C 3 "pattern" file # Show 3 lines context
# Regular expressions
grep "^start" file # Lines starting with "start"
grep "end$" file # Lines ending with "end"
grep "[0-9]+" file # Lines with numbers
grep -E "word1|word2" file # Extended regex (OR)
# Practical examples
ps aux | grep firefox # Find firefox processes
grep -r "TODO" *.c # Find TODOs in C files
grep -v "^#" config.conf # Show non-comment lines
# ===================
# awk - Text processing
# ===================
# Print columns
awk '{print $1}' file # Print first column
awk '{print $1, $3}' file # Print columns 1 and 3
awk '{print $NF}' file # Print last column
# Field separator
awk -F: '{print $1}' /etc/passwd # Use : as separator
# Conditions
awk '$3 > 100' file # Print lines where column 3 > 100
awk '$1 == "root"' file # Print lines where column 1 is "root"
# Built-in variables
awk '{print NR, $0}' file # NR = line number
awk 'NF > 5' file # NF = number of fields
# Calculations
awk '{sum += $1} END {print sum}' file # Sum column 1
awk '{print $1 * 2}' file # Multiply column 1 by 2
# Practical examples
ps aux | awk '$3 > 50' # Processes using >50% CPU
df -h | awk '$5 > 80' # Partitions >80% full
awk -F: '{print $1}' /etc/passwd # List usernames
# ===================
# sed - Stream editor
# ===================
# Substitution
sed 's/old/new/' file # Replace first occurrence
sed 's/old/new/g' file # Replace all occurrences
sed 's/old/new/gi' file # Case insensitive
sed '5s/old/new/' file # Replace in line 5
sed -i 's/old/new/g' file # Edit file in-place
# Delete lines
sed '5d' file # Delete line 5
sed '5,10d' file # Delete lines 5-10
sed '/pattern/d' file # Delete lines matching pattern
# Insert/Append
sed '5i\New Line' file # Insert before line 5
sed '5a\New Line' file # Append after line 5
# Print lines
sed -n '5p' file # Print line 5
sed -n '5,10p' file # Print lines 5-10
sed -n '/pattern/p' file # Print matching lines
# Practical examples
sed 's/#.*$//' config.conf # Remove comments
sed '/^$/d' file # Remove empty lines
sed 's/\s\+$//' file # Remove trailing whitespace
# ===================
# sort, uniq, cut
# ===================
# Sort
sort file # Sort alphabetically
sort -n file # Sort numerically
sort -r file # Reverse sort
sort -k 2 file # Sort by column 2
sort -u file # Sort and remove duplicates
# Unique
uniq file # Remove adjacent duplicates
uniq -c file # Count occurrences
uniq -d file # Show only duplicates
sort file | uniq # Remove all duplicates
# Cut
cut -d: -f1 /etc/passwd # Extract field 1 (delimiter :)
cut -c1-10 file # Extract characters 1-10
# ===================
# Combining commands
# ===================
# Count lines in all .c files
find . -name "*.c" | xargs wc -l
# Find most common words in file
cat file | tr '[:upper:]' '[:lower:]' | tr -s ' ' '\n' | sort | uniq -c | sort -rn | head -10
# Find largest files
find / -type f -exec du -h {} + | sort -rh | head -10
# Monitor log file for errors
tail -f /var/log/syslog | grep --line-buffered ERROR
# Count unique IP addresses in log
awk '{print $1}' access.log | sort | uniq -c | sort -rnKey Takeaways - Unix/Linux
Unix/Linux Command Line Mastery:
- File System Hierarchy: Standard directory structure (FHS) → /bin, /etc, /home, /var, etc.
- Boot Process: BIOS/UEFI → Bootloader → Kernel → Init → Systemd → Services
- File Permissions: Read (4), Write (2), Execute (1) → chmod 755 = rwxr-xr-x
- Process Management: ps, top, kill, nice for process control → Monitor and control processes
- Text Processing: grep (search), awk (columns), sed (edit), sort/uniq → Powerful text manipulation
- Command Piping: Chain commands with | for powerful workflows → ls | grep pattern | sort | uniq
Conclusion
This comprehensive operating systems tutorial covers the essential concepts needed for:
- Placement interviews at top tech companies
- Competitive programming understanding of system-level concepts
- Kernel development basics
- Systems programming foundation
- Performance optimization insights
Key Areas Covered:
- Process and thread management with scheduling
- Memory management (physical and virtual)
- File systems and I/O operations
- Synchronization and deadlock handling
- System calls and interrupts
- Inter-process communication
- Security and protection mechanisms
- Real-world Unix/Linux concepts
Study Tips:
- Understand concepts deeply, not just memorize
- Practice implementing algorithms (scheduling, page replacement, etc.)
- Run code examples and modify them
- Trace through syscall execution mentally
- Review code snippets regularly
- Connect theory to real systems (Linux, Windows)
- Practice interview questions about tradeoffs and design decisions
Interview Focus:
- Be ready to discuss tradeoffs (performance vs correctness)
- Know when to use which algorithm (FCFS vs LRU vs SCAN)
- Understand context switches and overhead
- Explain concepts with examples
- Connect multiple topics (e.g., how paging affects scheduling)
Good luck with your OS learning journey!
References and Further Reading
Books
- “Operating Systems: Three Easy Pieces” by Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
- “Modern Operating Systems” by Andrew S. Tanenbaum and Herbert Bos
- “Operating System Concepts” by Abraham Silberschatz, Peter Baer Galvin, and Greg Gagne
- “Linux Kernel Development” by Robert Love
- “The Design of the UNIX Operating System” by Maurice J. Bach
- “Advanced Programming in the UNIX Environment” by Stevens & Rago
Online Resources
- OSDev Wiki - Comprehensive OS development resource
- Linux Kernel Documentation
- ARM Architecture Reference Manual
- Intel Software Developer Manuals
- Rust Embedded Book
Tutorial Series
- cfenollosa’s OS Tutorial (x86 bare metal)
- Raspberry Pi OS Learning Repository
- Rust Raspberry Pi OS Tutorials
- MIT 6.828: Operating System Engineering
Online Courses
- UC Berkeley CS162: Operating Systems
- MIT OpenCourseWare: Operating Systems
- Linux Foundation Training
- CS162 (Berkeley): Operating Systems
- MIT 6.S081: Operating System Engineering
- CS140 (Stanford): Operating Systems
Note: This tutorial is designed for educational purposes, drawing from multiple sources and synthesizing concepts in an original manner. All code examples are simplified for instructional clarity and may require additional error handling and optimization for production use.
This comprehensive tutorial provides theoretical foundations, practical implementation details, code examples, and real-world applications to ensure deep understanding of operating system concepts.