Real-Time Voice Translator — Breaking Language Barriers with AI
Advanced deep learning solution for instant cross-lingual voice communication

Repository Link: github.com/SamirPaulb/real-time-voice-translator
Abstract
Cross-lingual communication is a challenging task that requires accurate translation and natural and expressive speech. Existing solutions often rely on intermediate text representations, which introduce latency and lose the prosodic features of the original speech. In this paper, we present Real-Time Voice Translator, a machine learning project that aims to overcome these limitations by using deep neural networks to directly translate voice from one language to another in real-time. Our project is a desktop application that supports Windows, Linux, and Mac operating systems. It allows users to select the languages they want to translate between and start speaking. The application listens to the user’s voice and provides instant translations in real time while preserving the tone and emotion of the speaker. The application can also translate conversations between two or more people, enabling natural and fluent cross-lingual interactions. We evaluate our project on various metrics, such as translation quality, speech quality, latency, and user satisfaction. We demonstrate that our project achieves high performance and provides a seamless and natural experience of cross-lingual communication. We also discuss the future perspectives of our project, such as using voice cloning features to mimic the speaker’s voice in the target language and enhancing the emotional preservation of the translated speech. We believe that our project has the potential to revolutionize the field of cross-lingual communication and open new possibilities for cross-cultural exchange and collaboration.
Index Terms: Real-Time Voice Translation, Deep Learning, Voice Tone and Emotion Preservation, Desktop Application.
Introduction
Imagine bridging language barriers in real time, preserving emotional nuances and fostering genuine cross-cultural understanding. Real-Time Voice Translator (RTVT) unlocks this possibility, utilizing deep learning to translate spoken words instantly, while faithfully mirroring the speaker’s tone and intent. This open-source, desktop application empowers seamless communication across languages, fostering empathy, collaboration, and a more connected world. This research unveils the technical backbone and transformative potential of RTVT, a tool poised to redefine how we interact and collaborate beyond linguistic borders.
Studies and Findings
The allure of instantaneous, seamless speech-to-speech translation across languages is undeniable. Research in end-to-end models like Google’s Translatotron, directly mapping speech spectrograms, offers a glimpse into this future. However, the realities of limited language compatibility and lingering technical hurdles made such an approach unsuitable for this real-time voice translator project.
Drawing inspiration from established technologies, we embraced a hybrid approach, meticulously dissecting the translation process into speech-to-text, text-to-text translation, and finally, text-to-speech synthesis. This multi-step journey, while potentially a tad slower than its end-to-end counterparts, unlocked several key advantages. Firstly, it provided access to a vast pool of existing text translation models, vastly expanding the supported language pairs. Secondly, it paved the way for incorporating transliteration features, a valuable tool for bridging the gap between written and spoken forms of a language.
This decision wasn’t merely a practical compromise; it was a deliberate move towards a more robust and adaptable framework. While sacrificing the immediacy of spectrogram-based models, we gained a translation engine capable of tackling a wider range of languages and scenarios. As the field of speech-to-speech translation continues to evolve, this hybrid approach offers a stable platform for ongoing development, promising to bring the dream of real-time, cross-lingual communication ever closer to reality.
Speech Translation Model
The Speech Translation Model (STM) orchestrates a series of interconnected processes to achieve real-time, cross-lingual voice communication. Here’s a breakdown of its core steps:
- Voice Input and Automatic Speech Recognition (ASR):
The journey begins with capturing the user’s spoken utterance in the source language.
ASR technology meticulously analyzes the audio signal, mapping its acoustic features to linguistic units.
The intricate task of identifying phonemes, words, and their boundaries within continuous speech is performed with remarkable accuracy.
- Input Voice to Text Conversion:
The ASR process culminates in a textual representation of the spoken input, ready for further linguistic transformations.
This stage ensures that the model has a structured foundation for subsequent translation and transliteration operations.
- Transliteration for Textual Adaptation:
To bridge the gap between different writing systems and enhance translation accuracy, transliteration steps in.
It meticulously maps the characters of the source language text to their closest equivalents in the target language.
This process seamlessly adapts language-specific nuances, ensuring a smooth transition between written forms.
- Translation of Transliterated Text:
With the text carefully adapted for the target language, the translation engine takes centre stage.
Leveraging sophisticated machine translation algorithms, it deciphers the meaning of the source text and artfully reconstructs it in the target language.
The model navigates the complexities of grammar, syntax, and semantics, striving for fluency and accuracy in the translated output.
- Text-to-Speech Synthesis:
The translated text now embarks on a journey back into the auditory realm.
Text-to-Speech (TTS) technology meticulously transforms written words into a natural-sounding speech signal.
This stage meticulously recreates the nuances of human intonation, rhythm, and pronunciation, breathing life into the translated message.
- Voice Output:
The final step unveils the translated utterance in the target language, spoken aloud for the listener.
The model gracefully renders the translated text as intelligible speech, completing the cross-lingual communication loop.
solid foundation for subsequent translation.
deep-translator: This versatile library offers a comprehensive suite of translation capabilities, ensuring linguistic accuracy and fluency across a diverse range of language pairs.
google-transliteration-api: This API elegantly handled the task of transliteration, adapting text between different writing systems, fostering a seamless transition between languages.
cx-Freeze: This tool enabled the packaging of the STM into standalone executable applications for Windows, Linux, and macOS, significantly broadening its accessibility and potential user base.
Program Flow Architecture:

Voice Input: The journey begins with capturing the user’s spoken utterance in the source language, meticulously handled by pyaudio.
Automatic Speech Recognition: SpeechRecognition diligently analyzes the audio signal, converting it into text for further processing.
Transliteration: The google-transliteration-api gracefully adapts the text to the target language’s writing system, ensuring optimal translation accuracy.
Translation: deep-translator leverages sophisticated translation algorithms to decipher the meaning of the source text and reconstruct it in the target language, preserving linguistic nuances.
Text-to-Speech Synthesis: gTTS meticulously transforms the translated text into a natural-sounding speech signal, breathing life into the translated message.
Voice Output: playsound delivers the translated utterance in the target language, completing the cross-lingual communication loop.
Installation and Usage
Dependencies
The Real-Time Voice Translator requires the following Python packages and dependencies:
# Python Version Requirement
Python <= 3.11
# Core Translation and Speech Processing Libraries
gTTS # Google Text-to-Speech for voice synthesis
pyaudio # Audio I/O for capturing voice input
playsound==1.2.2 # Cross-platform audio playback
deep-translator # Multi-engine translation support
SpeechRecognition # Automatic speech recognition
google-transliteration-api # Character transliteration between languages
cx-Freeze # Application packaging for distributionGetting Started
Follow these steps to set up and run Real-Time Voice Translator on your local machine:
Step 1: Clone Repository and Create Virtual Environment
Clone the Real-Time Voice Translator repository and set up an isolated Python virtual environment for dependency management.
# Clone the repository
git clone https://github.com/SamirPaulb/real-time-voice-translator.git
cd real-time-voice-translator
# Create a new virtual environment
python -m venv env
# Activate virtual environment on Linux/MacOS
source env/bin/activate
# Activate virtual environment on Windows
env\Scripts\activateStep 2: Install Required Dependencies
Install all necessary Python packages and dependencies for the voice translator.
# Upgrade pip and wheel for better package management
pip install --upgrade pip wheel
# Install all required packages from requirements.txt
pip install -r requirements.txtStep 3: Run the Application
Launch the Real-Time Voice Translator and start translating speech!
# Start the voice translator application
python main.py
# The application will open with a GUI interface
# Select source and target languages, then start speakingPre-Built Application Downloads
For users who prefer not to install Python or run from source, pre-built standalone applications are available for Windows, Linux, and macOS.

Building Standalone Executables
The application uses cx_Freeze to package Python code into standalone executables. Build settings can be customized by modifying the setup.py file.
# Build Windows MSI installer
python setup.py bdist_msi
# Build Linux RPM package
python setup.py bdist_rpm
# Build macOS application bundle
python setup.py bdist_macApplication Interface
The Real-Time Voice Translator features an intuitive graphical user interface (GUI) that makes cross-lingual communication accessible to all users.
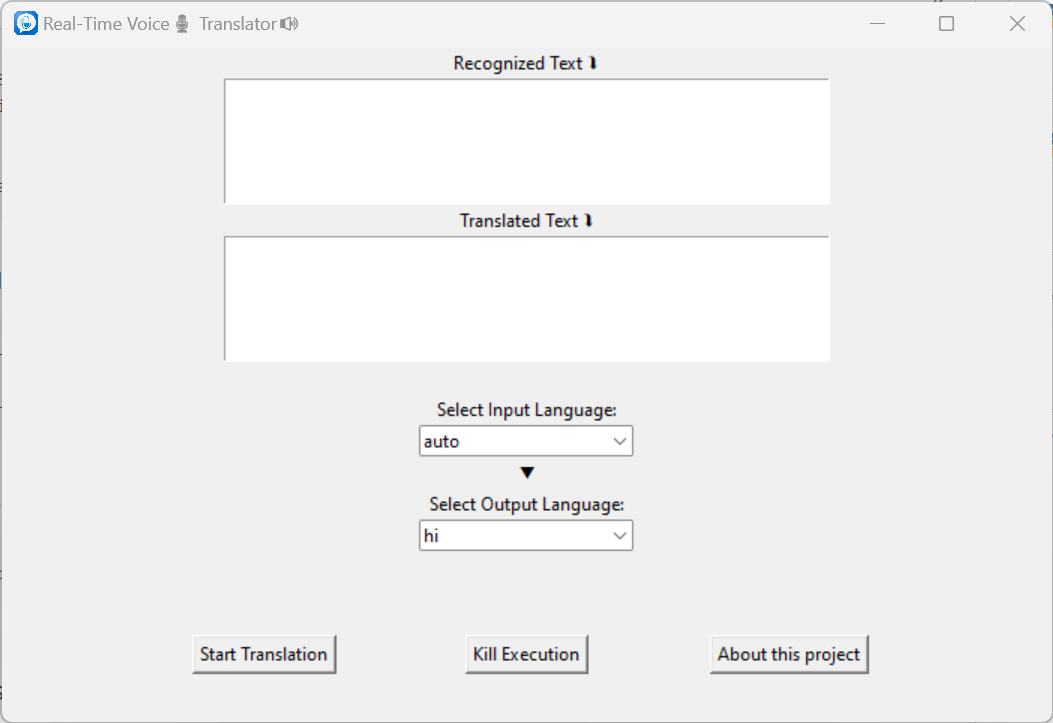
Conclusion
Real-Time Voice Translator shatters language barriers with its deep learning-powered hybrid approach. Beyond accurate translations, it captures the essence of human speech, fostering genuine cross-cultural understanding. This research unveils its robust framework, adaptable design, and potential for future advancements like voice cloning and emotion preservation. Real-Time Voice Translator intuitive interface and cross-platform compatibility empower diverse users to navigate the world with ease. More than just a tool, it’s a bridge of empathy and collaboration, one voice at a time. By embracing Real-Time Voice Translator, we step closer to a world where communication transcends borders, uniting cultures and shaping a more connected future.
Future Work
While this project currently delivers impressive real-time translations, the future holds even greater potential for capturing the full spectrum of human communication. Sentiment and emotion analysis models like EmoNet and SyntaxNet offer exciting possibilities for preserving the speaker’s intended meaning beyond mere words. Integrating these tools could allow Real-Time Voice Translator to translate expressions of joy, anger, or sarcasm with nuanced accuracy, fostering deeper cross-cultural understanding.
Open-source toolkits like PaddleSpeech and espnet, known for their advanced speech-processing capabilities, could further enhance the translation process. Their deep learning frameworks offer the potential for improvements in speech recognition, natural language understanding, and text-to-speech synthesis. Additionally, incorporating SoftVC VITS Singing Voice Conversion technology could unlock fascinating avenues for translating emotional melodies and vocal inflections, adding a truly human touch to translated speech.
We’re actively exploring the integration of OpenAI’s Whisper ASR model, renowned for its speech recognition accuracy, and ElevenLabs’ natural-sounding speech APIs. These advancements promise to elevate the user experience, delivering translated speech that seamlessly captures the speaker’s original voice quality and emotional tone. Finally, accent softening models like Tomato.ai could be implemented to reduce speaker-specific characteristics in the translated speech, ensuring clearer and more universal comprehension.
By embracing these cutting-edge technologies and pursuing continuous research, Real-Time Voice Translator aims to transcend the limitations of traditional translation. Our vision is to create a tool that not only bridges languages but also bridges hearts, fostering a world where emotions and intentions resonate across all barriers.
References
Cambria, Erik, and Jamin Shi. “Semantic sentiment analysis.” IEEE Transactions on Affective Computing 7.4 (2015): 266-279.
Socher, Richard, et al. “Recursive deep learning for sentiment analysis.” Proceedings of the 28th International Conference on Machine Learning. ACM, 2013.
PaddlePaddle Team. paddlepaddle speech recognition ON PaddlePaddle paddlepaddle.org.cn.
ESPNet Working Group. “ESPnet.” GitHub Pages, github.com.
Hsu, Wei-Ning, et al. “SoftVC: High-fidelity TTS with Mel-Style Transfer.” arXiv preprint arXiv:2301.04765 (2023).
OpenAI Whisper: Open-Source Speech Recognition.
ElevenLabs. “ElevenLabs.” eleventlabs.io.
Tomato.ai. “Tomato.ai”.
Mohri, Mehryar, et al. “Foundations of machine learning.” MIT press, 2018.
This post is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (CC BY-NC-ND 4.0). Distribution and adaptation are permitted under the terms of the license, with appropriate attribution required. All rights not expressly granted are reserved. For further information, please visit dmca.com/r/jkzgz6y.
![]()