System Design Notes
A comprehensive guide to designing large-scale distributed systems

1. Introduction to System Design
System design is the process of defining the architecture, components, modules, interfaces, and data for a system to satisfy specified requirements. In the context of software engineering, it involves making high-level decisions about how to build scalable, reliable, and maintainable systems.
Why System Design Matters
Modern applications serve millions or even billions of users simultaneously. These systems must be:
- Scalable: Handle growing amounts of work
- Reliable: Continue functioning under failures
- Available: Accessible when users need them
- Maintainable: Easy to update and modify
- Performant: Respond quickly to user requests
- Cost-effective: Operate within reasonable budgets
The Journey Ahead
This guide takes you through a comprehensive exploration of system design, from fundamental concepts to complex real-world implementations. Each section builds upon previous knowledge, creating a complete understanding of how modern distributed systems work.
Learning Approach
Throughout this guide, we’ll use:
- Visual diagrams (in Mermaid format) to illustrate architectures
- Real-world examples from companies like Netflix, Uber, and Twitter
- Code examples in Python to demonstrate concepts
- Trade-off analyses to understand decision-making
- Practical exercises to reinforce learning
2. System Design Fundamentals
2.1 Scalability
Scalability is the ability of a system to handle increased load by adding resources. There are two primary approaches:
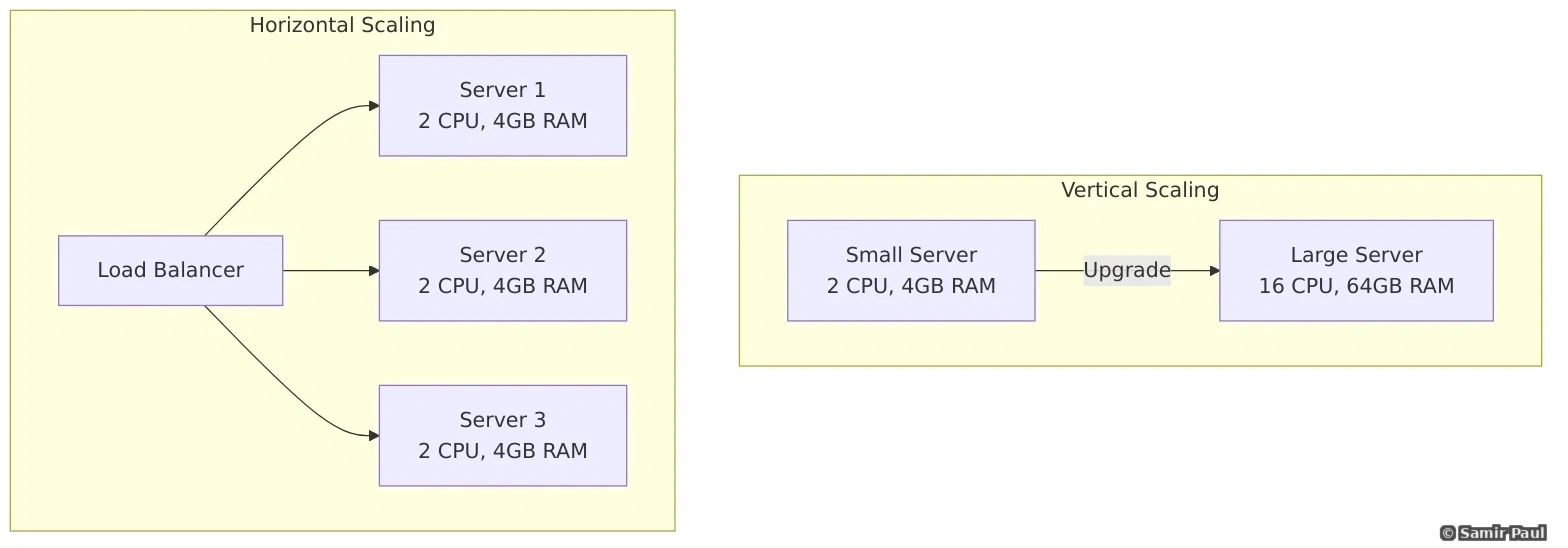
Vertical Scaling (Scale Up)
Adding more power to existing machines (CPU, RAM, disk).
Advantages:
- Simple implementation
- No code changes required
- Maintains data consistency easily
Disadvantages:
- Hardware limits (you can’t add infinite resources)
- Single point of failure
- Expensive at high end
- Requires downtime for upgrades
Horizontal Scaling (Scale Out)
Adding more machines to distribute the load.
Advantages:
- No theoretical limit to scaling
- Better fault tolerance
- More cost-effective
- Can use commodity hardware
Disadvantages:
- Application complexity increases
- Data consistency challenges
- Network overhead
- Requires load balancing
2.2 Performance vs Scalability
These concepts are often confused but are distinctly different:
Performance Problem: System is slow for a single user
- Solution: Optimize algorithms, add indexes, use caching
Scalability Problem: System performs well for one user but degrades under load
- Solution: Add servers, implement load balancing, distribute data
2.3 Latency vs Throughput
Latency: Time to perform a single operation
- Measured in milliseconds (ms)
- Example: Database query takes 50ms
Throughput: Number of operations per time unit
- Measured in requests per second (RPS) or queries per second (QPS)
- Example: System handles 10,000 requests/second
Important Insight: Low latency doesn’t always mean high throughput!
2.4 Key Latency Numbers Every Engineer Should Know
Understanding these numbers helps make informed design decisions:
| Operation | Latency | Relative Scale |
|---|---|---|
| L1 cache reference | 0.5 ns | 1x |
| Branch mispredict | 5 ns | 10x |
| L2 cache reference | 7 ns | 14x |
| Mutex lock/unlock | 100 ns | 200x |
| Main memory reference | 100 ns | 200x |
| Compress 1KB with Snappy | 10,000 ns (10 µs) | 20,000x |
| Send 1KB over 1 Gbps network | 10,000 ns (10 µs) | 20,000x |
| Read 1 MB sequentially from memory | 250,000 ns (250 µs) | 500,000x |
| Round trip within same datacenter | 500,000 ns (500 µs) | 1,000,000x |
| Read 1 MB sequentially from SSD | 1,000,000 ns (1 ms) | 2,000,000x |
| Disk seek | 10,000,000 ns (10 ms) | 20,000,000x |
| Read 1 MB sequentially from disk | 30,000,000 ns (30 ms) | 60,000,000x |
| Send packet CA→Netherlands→CA | 150,000,000 ns (150 ms) | 300,000,000x |
- Memory is fast, disk is slow
- SSD is 20x faster than traditional disk
- Network calls within datacenter are relatively fast
- Cross-continent network calls are expensive
- Always prefer sequential reads over random seeks
2.5 Availability
Availability is the percentage of time a system is operational and accessible.
Availability Calculation:
Availability = (Total Time - Downtime) / Total Time × 100%Standard Availability Tiers (The Nines):
| Availability | Downtime per Year | Downtime per Month | Downtime per Week |
|---|---|---|---|
| 99% (two nines) | 3.65 days | 7.31 hours | 1.68 hours |
| 99.9% (three nines) | 8.77 hours | 43.83 minutes | 10.08 minutes |
| 99.99% (four nines) | 52.60 minutes | 4.38 minutes | 1.01 minutes |
| 99.999% (five nines) | 5.26 minutes | 26.30 seconds | 6.05 seconds |
| 99.9999% (six nines) | 31.56 seconds | 2.63 seconds | 0.61 seconds |
Achieving High Availability:
Eliminate Single Points of Failure (SPOF)
- Redundant components
- Failover mechanisms
- Multi-region deployment
Implement Health Checks
- Monitor service health
- Automatic failure detection
- Quick recovery mechanisms
Use Load Balancers
- Distribute traffic
- Route around failures
- Prevent server overload
3. Back-of-the-Envelope Estimation
Being able to quickly estimate system requirements is crucial for system design. This section covers the estimation techniques used in interviews and real-world planning.
3.1 Power of Two
Understand data volume units:
| Power | Exact Value | Approximate Value | Short Name |
|---|---|---|---|
| 10 | 1,024 | 1 thousand | 1 KB |
| 20 | 1,048,576 | 1 million | 1 MB |
| 30 | 1,073,741,824 | 1 billion | 1 GB |
| 40 | 1,099,511,627,776 | 1 trillion | 1 TB |
| 50 | 1,125,899,906,842,624 | 1 quadrillion | 1 PB |
3.2 Common Performance Numbers
- QPS (Queries Per Second) for web server: 1000 - 5000
- Database connections pool size: 50 - 100 per instance
- Average web page size: 1-2 MB
- Video streaming bitrate: 1-5 Mbps for 1080p
- Mobile app API call: 5-10 calls per user session
3.3 Example Estimation: Twitter-Like System
Given Requirements:
- 300 million monthly active users (MAU)
- 50% use Twitter daily
- Average user posts 2 tweets per day
- 10% of tweets contain media
- Data retained for 5 years
Calculations:
Daily Active Users (DAU):
DAU = 300M × 50% = 150MTweet Traffic:
Tweets per day = 150M × 2 = 300M
Tweets per second (average) = 300M / 86400 ≈ 3,500 tweets/second
Peak QPS = 3,500 × 2 = 7,000 tweets/second (assuming 2x peak factor)Storage Estimation:
Average tweet size:
- Tweet text: 280 chars × 2 bytes = 560 bytes
- Metadata (ID, timestamp, user_id, etc.): 200 bytes
- Total per tweet: ~800 bytes ≈ 1 KB
Media tweets (10%):
- Image average: 500 KB
- Total per media tweet: 500 KB + 1 KB ≈ 500 KB
Daily storage:
- Text tweets: 270M × 1 KB = 270 GB
- Media tweets: 30M × 500 KB = 15 TB
- Total per day = 15.27 TB
5-year storage:
15.27 TB/day × 365 days × 5 years ≈ 27.9 PBBandwidth Estimation:
Ingress (upload):
15.27 TB/day ÷ 86,400 seconds ≈ 177 MB/second
Egress (assume each tweet viewed 10 times):
177 MB/s × 10 = 1.77 GB/secondMemory for Cache (80-20 rule):
20% of tweets generate 80% of traffic
Daily cache: 15.27 TB × 0.2 = 3 TB4. The System Design Interview Framework
A systematic approach to solving any system design problem.
4.1 The 4-Step Framework
Step 1: Understand the Problem and Establish Design Scope (3-10 minutes)
Ask clarifying questions:
- Who are the users?
- How many users?
- What features are essential?
- What is the scale we’re designing for?
- What is the expected traffic pattern?
- What technologies does the company use?
Step 2: Propose High-Level Design and Get Buy-In (10-15 minutes)
Key actions:
- Draw initial architecture diagram
- Identify major components
- Explain data flow
- Get feedback from interviewer
Step 3: Design Deep Dive (10-25 minutes)
Focus areas:
- Dig into 2-3 components based on interviewer interest
- Discuss trade-offs
- Address bottlenecks
- Consider edge cases
Step 4: Wrap Up (3-5 minutes)
Final touches:
- Identify system bottlenecks
- Discuss potential improvements
- Recap design decisions
- Mention monitoring and operations
4.2 Key Principles
Start Simple, Then Iterate
- Begin with a basic design
- Add complexity incrementally
- Justify each addition
Focus on What Matters
- Prioritize based on requirements
- Don’t over-engineer
- Keep the user experience in mind
Think About Trade-offs
- No perfect solution exists
- Discuss pros and cons
- Choose based on requirements
Use Real Numbers
- Apply back-of-the-envelope calculations
- Validate your assumptions
- Show quantitative reasoning
5. Networking and Communication
5.1 The OSI Model and TCP/IP

5.2 HTTP and HTTPS
HTTP (Hypertext Transfer Protocol) is the foundation of data communication on the web.
Common HTTP Methods:
| Method | Purpose | Idempotent | Safe |
|---|---|---|---|
| GET | Retrieve data | Yes | Yes |
| POST | Create resource | No | No |
| PUT | Update/Replace resource | Yes | No |
| PATCH | Partial update | No | No |
| DELETE | Remove resource | Yes | No |
| HEAD | Get headers only | Yes | Yes |
| OPTIONS | Query methods | Yes | Yes |
HTTP Status Codes:
1xx: Informational
100 Continue
101 Switching Protocols
2xx: Success
200 OK
201 Created
202 Accepted
204 No Content
3xx: Redirection
301 Moved Permanently
302 Found (Temporary Redirect)
304 Not Modified
307 Temporary Redirect
308 Permanent Redirect
4xx: Client Errors
400 Bad Request
401 Unauthorized
403 Forbidden
404 Not Found
409 Conflict
429 Too Many Requests
5xx: Server Errors
500 Internal Server Error
502 Bad Gateway
503 Service Unavailable
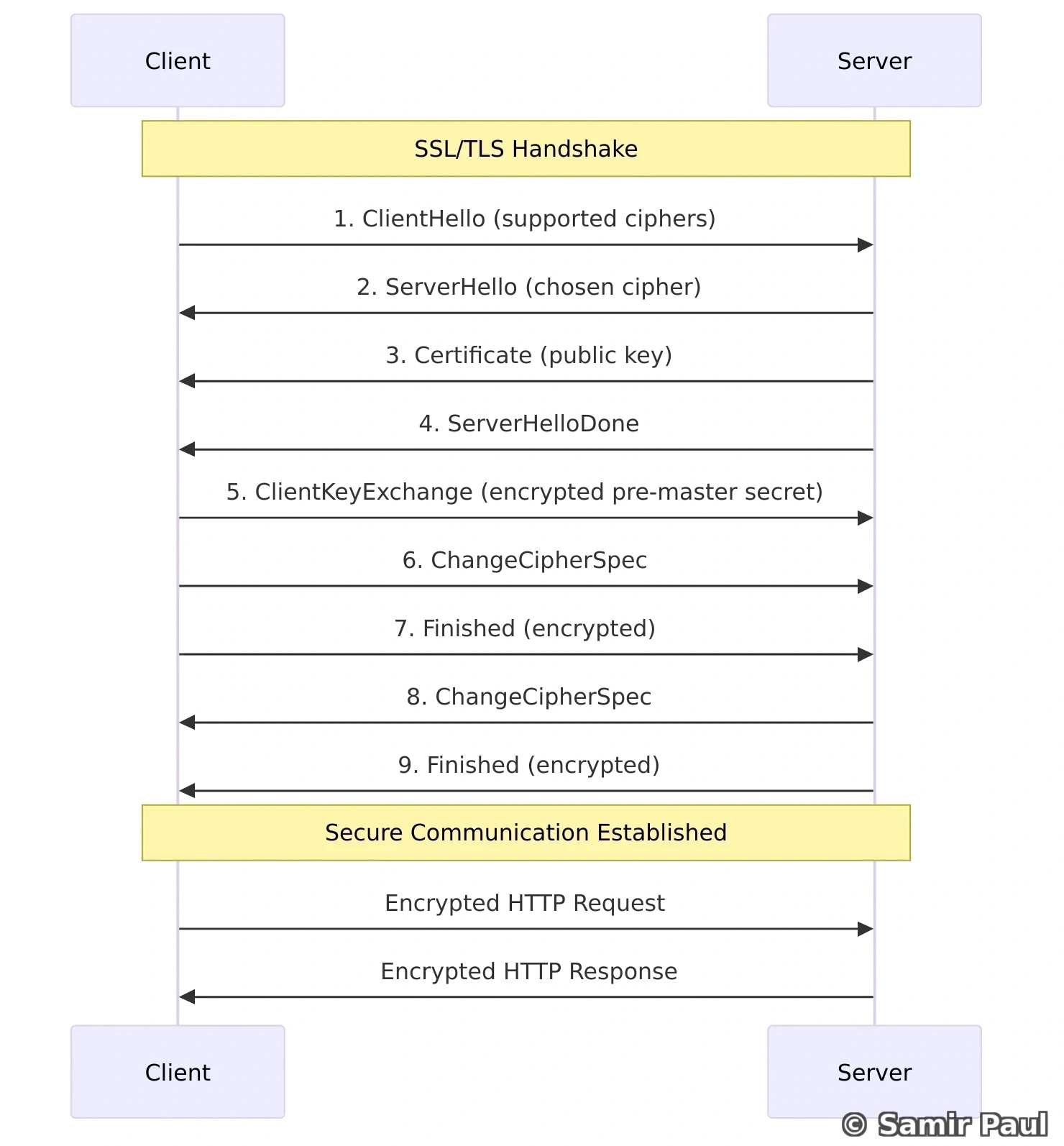
504 Gateway TimeoutHTTPS = HTTP + SSL/TLS
HTTPS adds encryption and authentication through SSL/TLS:
5.3 REST vs GraphQL vs gRPC vs WebSockets
REST (Representational State Transfer)
Characteristics:
- Resource-based (nouns in URLs)
- Stateless
- Uses standard HTTP methods
- Returns JSON or XML
Example:
GET /api/users/123
GET /api/users/123/posts
POST /api/users/123/posts
PUT /api/users/123
DELETE /api/users/123Pros:
- Simple and widely understood
- Cacheable
- Good tooling support
Cons:
- Over-fetching or under-fetching data
- Multiple round trips for related data
- Versioning can be challenging
GraphQL
Characteristics:
- Client specifies exactly what data it needs
- Single endpoint
- Strongly typed schema
- Real-time updates via subscriptions
Example:
query {
user(id: "123") {
name
email
posts(limit: 10) {
title
createdAt
}
}
}Pros:
- No over-fetching/under-fetching
- Single request for complex data
- Self-documenting API
Cons:
- More complex backend
- Caching is harder
- Potential for expensive queries
gRPC (Google Remote Procedure Call)
Characteristics:
- Uses Protocol Buffers (binary format)
- HTTP/2 based
- Strongly typed
- Bi-directional streaming
Example (protobuf):
service UserService {
rpc GetUser (UserRequest) returns (UserResponse);
rpc ListUsers (ListUsersRequest) returns (stream UserResponse);
}
message UserRequest {
string user_id = 1;
}
message UserResponse {
string user_id = 1;
string name = 2;
string email = 3;
}Pros:
- Very fast (binary protocol)
- Streaming support
- Strong typing
Cons:
- Not browser-friendly
- Less human-readable
- Steeper learning curve
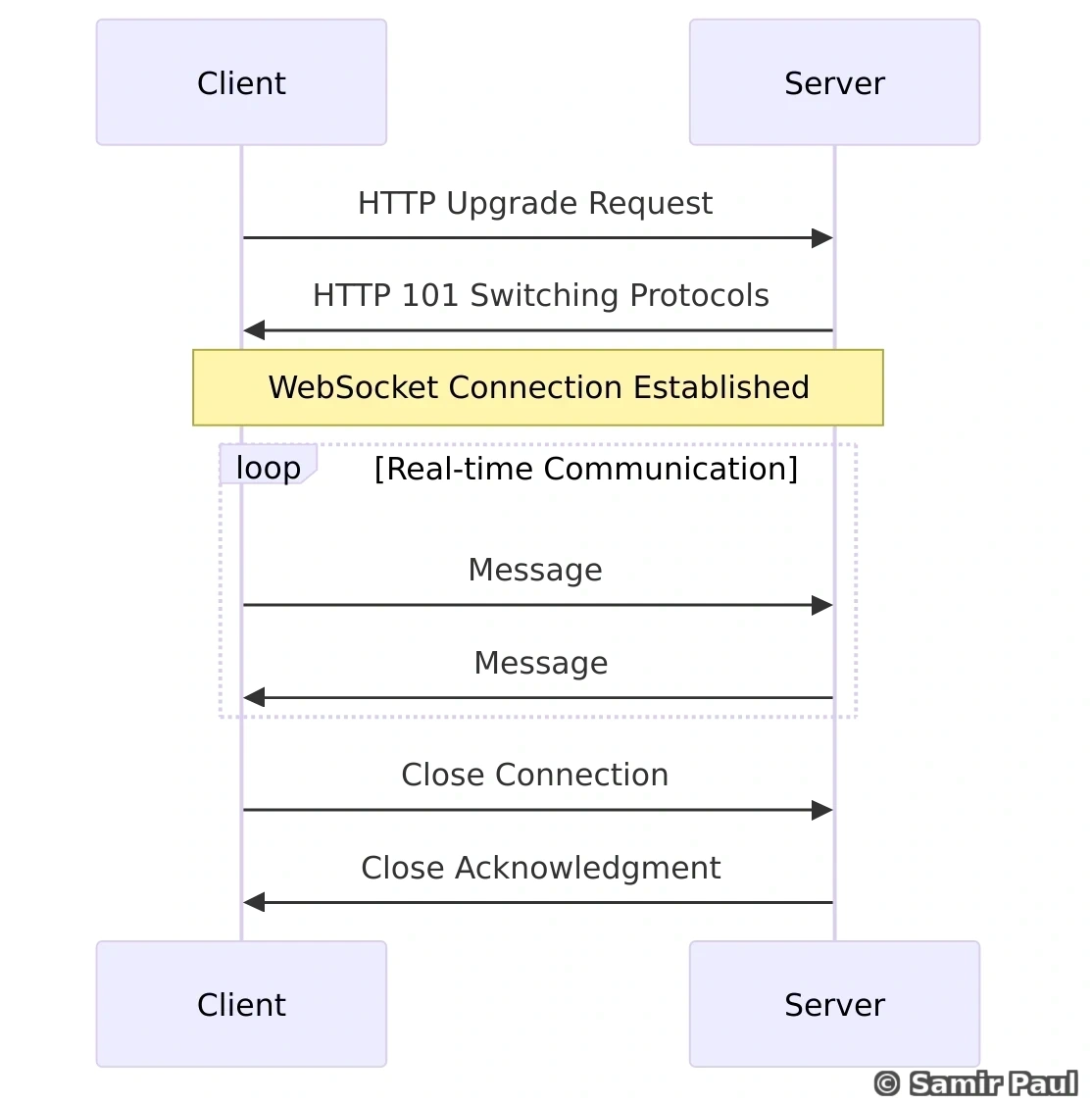
WebSockets
Characteristics:
- Full-duplex communication
- Persistent connection
- Real-time bidirectional data flow
Use cases:
- Chat applications
- Live feeds
- Real-time gaming
- Collaborative editing
5.4 API Authentication
1. Basic Authentication
Authorization: Basic base64(username:password)- Simple but insecure (credentials in every request)
- Use only over HTTPS
2. API Keys
X-API-Key: your-api-key-here- Simple to implement
- Good for server-to-server
- Hard to revoke individual keys
3. OAuth 2.0
Most common flows:
Authorization Code Flow (for web apps):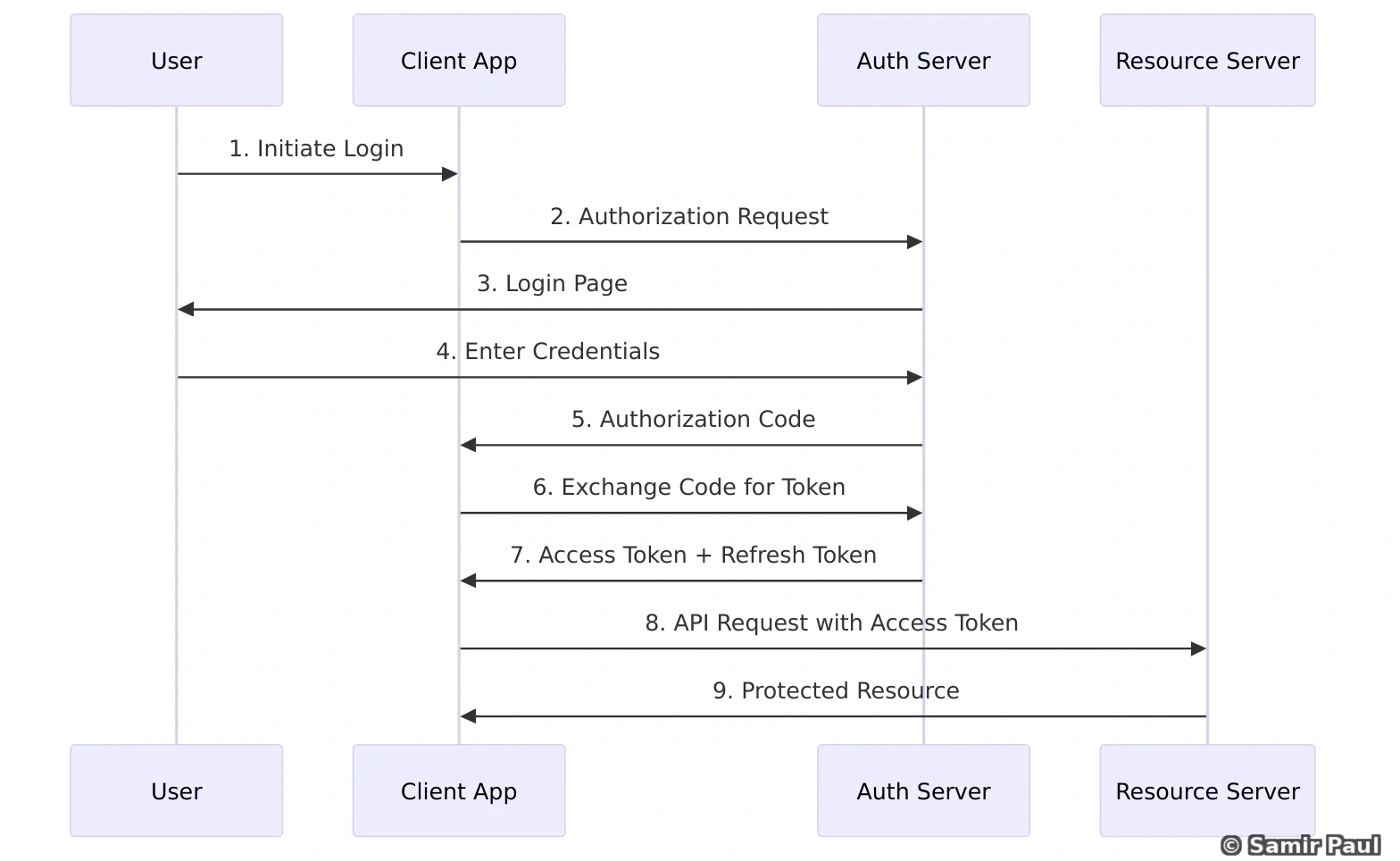
4. JWT (JSON Web Tokens)
Structure: header.payload.signature
// Header
{
"alg": "HS256",
"typ": "JWT"
}
// Payload
{
"sub": "user123",
"name": "John Doe",
"iat": 1516239022,
"exp": 1516242622
}
// Signature
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret
)Pros:
- Stateless (no server-side session storage)
- Portable across domains
- Contains user information
Cons:
- Can’t revoke before expiration
- Token size can be large
- Vulnerable if secret is exposed
6. Load Balancing
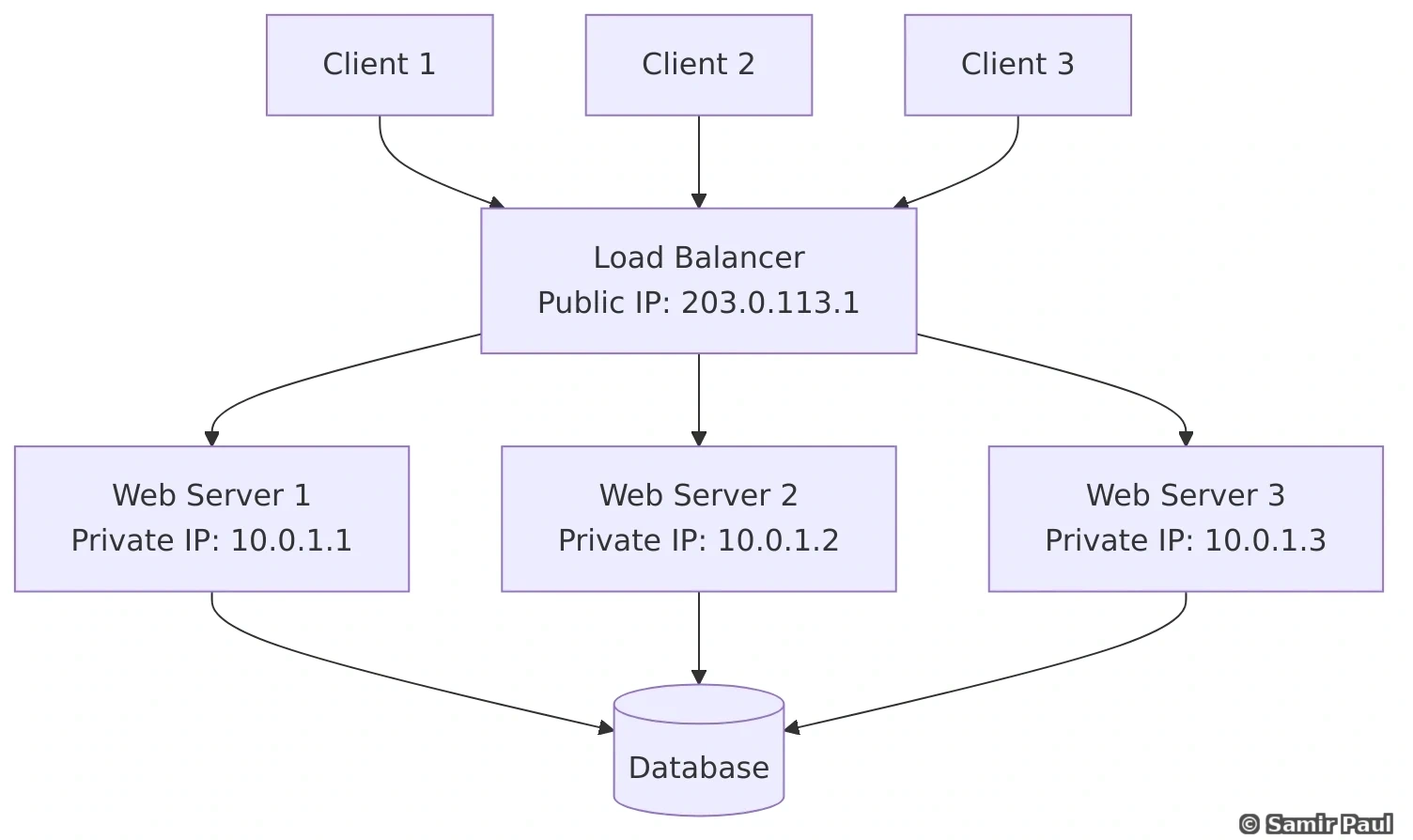
Load balancers distribute incoming traffic across multiple servers, improving availability and preventing any single server from becoming a bottleneck.
6.1 Why Load Balancers?
Benefits:
- High Availability: If one server fails, traffic routes to healthy servers
- Scalability: Add more servers to handle increased load
- Performance: Distribute load evenly
- Flexibility: Perform maintenance without downtime
6.2 Load Balancer Architecture
6.3 Load Balancing Algorithms
Choosing the Right Algorithm: The best load balancing algorithm depends on your specific use case. For stateless applications with similar request complexity, Round Robin works well. For long-lived connections (like WebSockets), use Least Connections. For session affinity, use IP Hash or Consistent Hashing.
1. Round Robin
- Distributes requests sequentially
- Simple and fair distribution
- Doesn’t account for server load or capacity
class RoundRobinLoadBalancer:
def __init__(self, servers):
self.servers = servers
self.current = 0
def get_server(self):
server = self.servers[self.current]
self.current = (self.current + 1) % len(self.servers)
return server2. Weighted Round Robin
- Assigns weight to each server based on capacity
- Servers with higher capacity get more requests
class WeightedRoundRobinLoadBalancer:
def __init__(self, servers_with_weights):
# servers_with_weights = [('server1', 5), ('server2', 3), ('server3', 2)]
self.servers = []
for server, weight in servers_with_weights:
self.servers.extend([server] * weight)
self.current = 0
def get_server(self):
server = self.servers[self.current]
self.current = (self.current + 1) % len(self.servers)
return server3. Least Connections
- Routes to server with fewest active connections
- Good for long-lived connections
class LeastConnectionsLoadBalancer:
def __init__(self, servers):
self.connections = {server: 0 for server in servers}
def get_server(self):
return min(self.connections, key=self.connections.get)
def on_connection_established(self, server):
self.connections[server] += 1
def on_connection_closed(self, server):
self.connections[server] -= 14. Least Response Time
- Routes to server with lowest average response time
- Dynamically adapts to server performance
5. IP Hash
- Uses client IP to determine server
- Ensures same client always routes to same server
- Good for session persistence
import hashlib
class IPHashLoadBalancer:
def __init__(self, servers):
self.servers = servers
def get_server(self, client_ip):
hash_value = int(hashlib.md5(client_ip.encode()).hexdigest(), 16)
server_index = hash_value % len(self.servers)
return self.servers[server_index]6. Random
- Randomly selects server
- Simple and works well with many servers
6.4 Load Balancer Layers
Layer 4 vs Layer 7 Trade-off: Layer 4 load balancing is faster (10-100 microseconds latency) but less intelligent. Layer 7 adds 1-10 milliseconds latency but enables content-based routing, URL rewriting, and application-aware decisions. Use Layer 4 for raw throughput, Layer 7 for microservices architectures.
Layer 4 (Transport Layer) Load Balancing
- Operates at TCP/UDP level
- Routes based on IP and port
- Fast (no packet inspection)
- Cannot make routing decisions based on content
Layer 7 (Application Layer) Load Balancing
- Operates at HTTP level
- Can route based on URL, headers, cookies
- More intelligent routing
- Slower (needs to inspect packets)
- Can do SSL termination

6.5 Health Checks
Load balancers need to know which servers are healthy:
import time
import requests
class HealthChecker:
def __init__(self, servers, check_interval=10):
self.servers = servers
self.healthy_servers = set(servers)
self.check_interval = check_interval
def check_health(self, server):
try:
response = requests.get(f"{server}/health", timeout=2)
return response.status_code == 200
except:
return False
def monitor(self):
while True:
for server in self.servers:
if self.check_health(server):
self.healthy_servers.add(server)
else:
self.healthy_servers.discard(server)
time.sleep(self.check_interval)
def get_healthy_servers(self):
return list(self.healthy_servers)6.6 Session Persistence (Sticky Sessions)
Challenge: With load balancing, subsequent requests from the same user might go to different servers.
Solutions:
1. Sticky Sessions at Load Balancer
- Load balancer remembers which server served a client
- Routes all requests from that client to same server
- Problem: If server dies, session is lost
2. Shared Session Storage
- Store sessions in Redis/Memcached
- Any server can serve any request
- More scalable and fault-tolerant
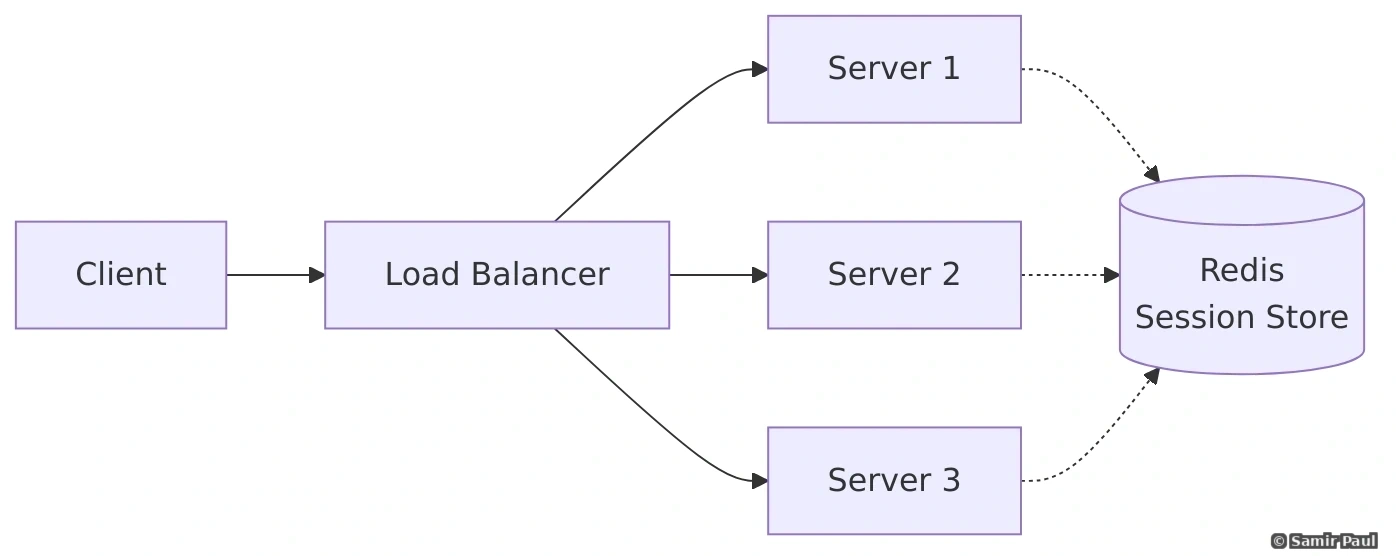
3. Client-Side Sessions (JWT)
- Session data stored in token on client
- Stateless servers
- Token passed with each request
7. Caching Strategies
7.1 What to Cache?
Good candidates for caching:
- Read-heavy data: Data that is read frequently but updated infrequently
- Expensive computations: Results that take significant CPU time to calculate
- Database query results: Frequently-run queries with stable results
- API responses: Third-party API calls with consistent data
- Rendered HTML pages: Static or semi-static page content
- Session data: User authentication and session information
- Static assets: Images, CSS, JavaScript files
Avoid caching:
- Highly dynamic data that changes frequently
- User-specific sensitive data without proper isolation
- Data requiring strong consistency guarantees
- Data with low hit rates (rarely accessed)
7.2 Cache Levels
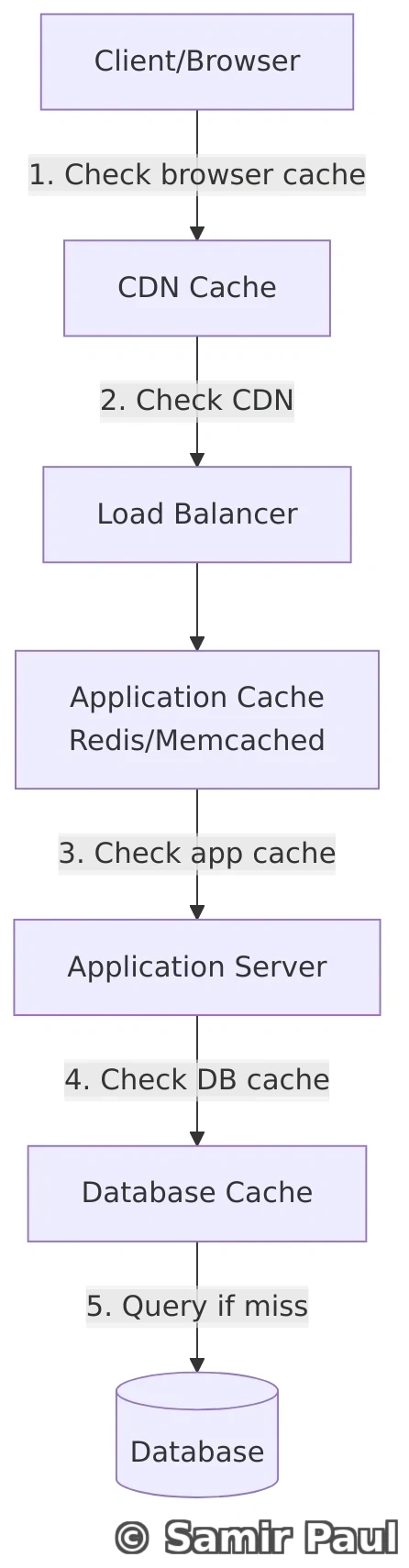
1. Client-Side Caching
- Browser cache
- LocalStorage / SessionStorage
- Service Workers
2. CDN Caching
- Caches static assets close to users
- Reduces origin server load
3. Application-Level Caching
- In-memory caches (Redis, Memcached)
- Application server cache
4. Database Caching
- Query result cache
- Buffer pool cache
7.3 Caching Patterns
Caching Pattern Selection: Choose your caching pattern based on read/write ratios and consistency requirements:
- Cache-Aside: Best for read-heavy workloads with eventual consistency tolerance (90% of use cases)
- Write-Through: When strong consistency is required between cache and database
- Write-Behind: For write-heavy workloads where eventual consistency is acceptable
- Refresh-Ahead: For predictable access patterns with hot data
1. Cache-Aside (Lazy Loading)
Most common pattern:
def get_user(user_id):
# Try cache first
user = cache.get(f"user:{user_id}")
if user is None:
# Cache miss - load from database
user = database.query(f"SELECT * FROM users WHERE id = {user_id}")
# Store in cache for next time
cache.set(f"user:{user_id}", user, ttl=3600)
return userFlow:
- Application checks cache
- If data exists (cache hit), return it
- If data doesn’t exist (cache miss):
- Load from database
- Write to cache
- Return data
Pros:
- Only requested data is cached
- Cache failure doesn’t break application
Cons:
- Initial request is slow (cache miss)
- Stale data possible if cache doesn’t expire
2. Read-Through Cache
Cache sits between application and database:
class ReadThroughCache:
def __init__(self, cache, database):
self.cache = cache
self.database = database
def get(self, key):
# Cache handles database lookup automatically
return self.cache.get(key, loader=lambda: self.database.get(key))Flow:
- Application requests data from cache
- Cache checks if data exists
- If not, cache loads from database automatically
- Cache returns data
Pros:
- Cleaner application code
- Consistent caching logic
Cons:
- Cache becomes critical dependency
- Potential bottleneck
3. Write-Through Cache
Data written to cache and database simultaneously:
def update_user(user_id, data):
# Write to both cache and database
cache.set(f"user:{user_id}", data)
database.update(f"UPDATE users SET ... WHERE id = {user_id}")Pros:
- Cache always consistent with database
- No stale data
Cons:
- Slower writes (two operations)
- Cache may contain rarely-read data
4. Write-Behind (Write-Back) Cache
Data written to cache immediately, database updated asynchronously:
def update_user(user_id, data):
# Write to cache immediately
cache.set(f"user:{user_id}", data)
# Queue database write for later
write_queue.push({
'operation': 'update',
'table': 'users',
'id': user_id,
'data': data
})Pros:
- Very fast writes
- Can batch database writes
Cons:
- Risk of data loss if cache fails
- More complex to implement
- Eventual consistency
5. Refresh-Ahead
Proactively refresh cache before expiration:
import time
import threading
def refresh_ahead_cache(key, ttl, refresh_threshold=0.8):
data = cache.get(key)
if data is None:
# Cache miss - load and cache
data = load_from_database(key)
cache.set(key, data, ttl=ttl)
else:
# Check if approaching expiration
remaining_ttl = cache.ttl(key)
if remaining_ttl < (ttl * refresh_threshold):
# Asynchronously refresh
threading.Thread(
target=lambda: cache.set(key, load_from_database(key), ttl=ttl)
).start()
return data7.4 Cache Eviction Policies
When cache is full, which data should be removed?
1. LRU (Least Recently Used)
- Evicts least recently accessed items
- Most commonly used
- Good for general-purpose caching
2. LFU (Least Frequently Used)
- Evicts items accessed least often
- Good for data with varying access patterns
3. FIFO (First In First Out)
- Evicts oldest items first
- Simple but not always optimal
4. TTL (Time To Live)
- Items expire after fixed time
- Good for time-sensitive data
Implementation of LRU Cache:
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key):
if key not in self.cache:
return None
# Move to end (most recently used)
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key, value):
if key in self.cache:
# Update and move to end
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
# Remove least recently used (first item)
self.cache.popitem(last=False)
# Usage
cache = LRUCache(capacity=3)
cache.put("user:1", {"name": "Alice"})
cache.put("user:2", {"name": "Bob"})
cache.put("user:3", {"name": "Charlie"})
cache.put("user:4", {"name": "David"}) # Evicts user:17.5 Cache Considerations
1. Cache Expiration (TTL)
TTL Strategy Pitfalls: Setting TTL too short causes cache misses and unnecessary database hits. Setting it too long risks serving stale data. Monitor cache hit ratios and adjust TTL dynamically based on actual data update frequency. For critical data, implement cache invalidation events rather than relying solely on TTL.
Set appropriate TTL based on data characteristics:
# Fast-changing data
cache.set("stock_price:AAPL", price, ttl=60) # 1 minute
# Slow-changing data
cache.set("user_profile:123", profile, ttl=3600) # 1 hour
# Rarely changing data
cache.set("product_category", categories, ttl=86400) # 24 hours2. Cache Stampede Prevention
Cache Thundering Herd: When a popular cached item expires, hundreds or thousands of requests can simultaneously hit the database, causing a spike in load. This can bring down the database. Implement one of: (1) Locking (only first request loads), (2) Probabilistic early refresh (reload before expiration), or (3) Refresh-Ahead pattern.
Problem: When cached item expires, multiple requests simultaneously hit database.
Solution: Use locks or probabilistic early expiration:
import threading
import random
lock_dict = {}
def get_with_stampede_protection(key, ttl, load_function):
data = cache.get(key)
if data is None:
# Get or create lock for this key
if key not in lock_dict:
lock_dict[key] = threading.Lock()
lock = lock_dict[key]
# Only one thread loads data
with lock:
# Double-check cache (another thread may have loaded it)
data = cache.get(key)
if data is None:
data = load_function()
cache.set(key, data, ttl=ttl)
# Probabilistic early refresh
remaining_ttl = cache.ttl(key)
if remaining_ttl < ttl * 0.2: # Last 20% of TTL
if random.random() < 0.1: # 10% chance
threading.Thread(
target=lambda: cache.set(key, load_function(), ttl=ttl)
).start()
return data3. Cache Warming
Pre-populate cache with frequently accessed data:
def warm_cache():
"""Run during application startup"""
# Load popular users
popular_users = database.query("SELECT * FROM users ORDER BY popularity DESC LIMIT 1000")
for user in popular_users:
cache.set(f"user:{user.id}", user, ttl=3600)
# Load popular products
popular_products = database.query("SELECT * FROM products ORDER BY sales DESC LIMIT 5000")
for product in popular_products:
cache.set(f"product:{product.id}", product, ttl=7200)4. Distributed Caching
For high availability and scalability:
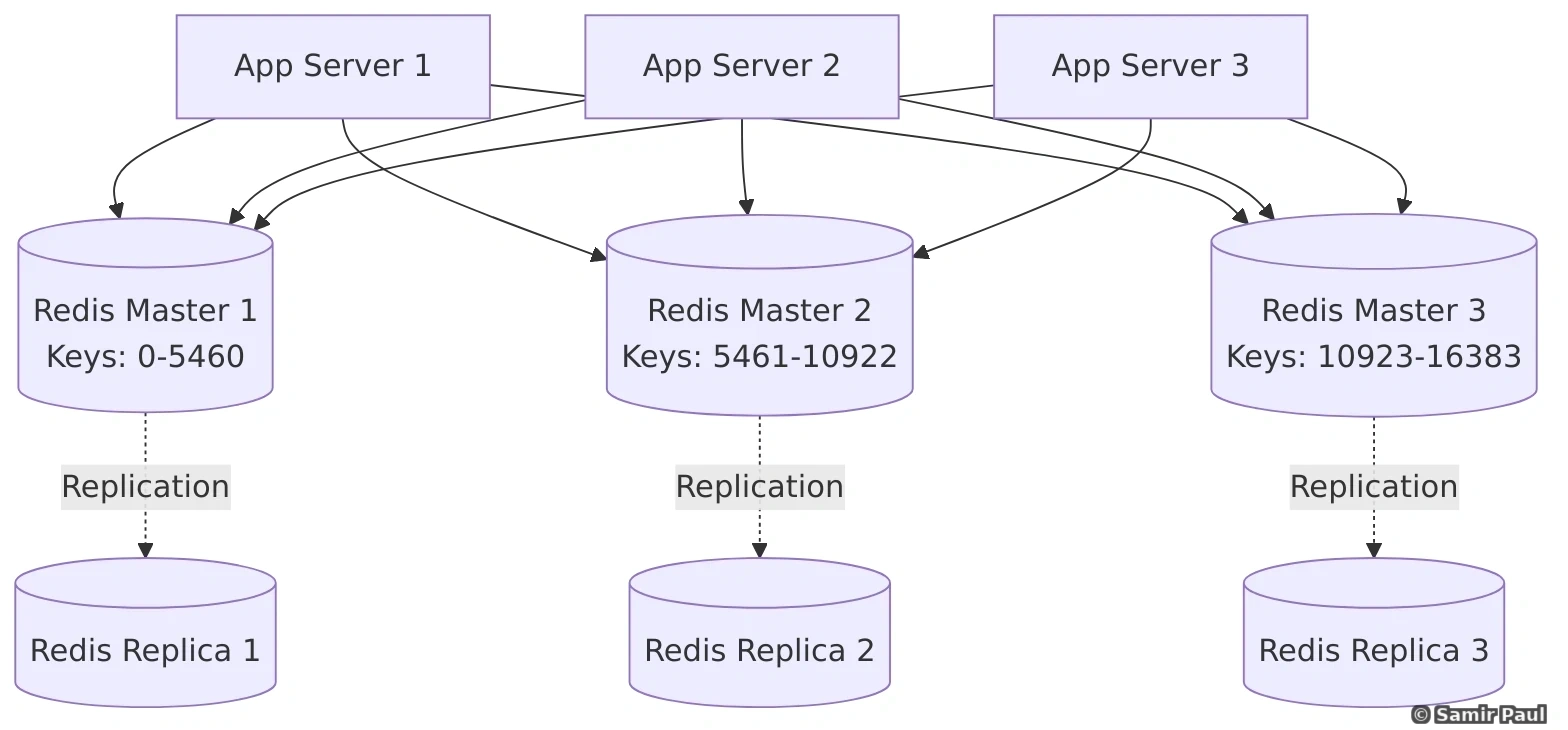
7.6 Redis vs Memcached
| Feature | Redis | Memcached |
|---|---|---|
| Data Structures | Strings, Lists, Sets, Sorted Sets, Hashes, Bitmaps | Only strings |
| Persistence | Yes (RDB, AOF) | No |
| Replication | Yes | No (requires external tools) |
| Transactions | Yes | No |
| Pub/Sub | Yes | No |
| Lua Scripting | Yes | No |
| Multi-threading | Single-threaded (6.0+ has I/O threads) | Multi-threaded |
| Memory Efficiency | Good | Slightly better |
| Use Case | Complex caching, session store, queues | Simple key-value caching |
8. Content Delivery Networks (CDN)
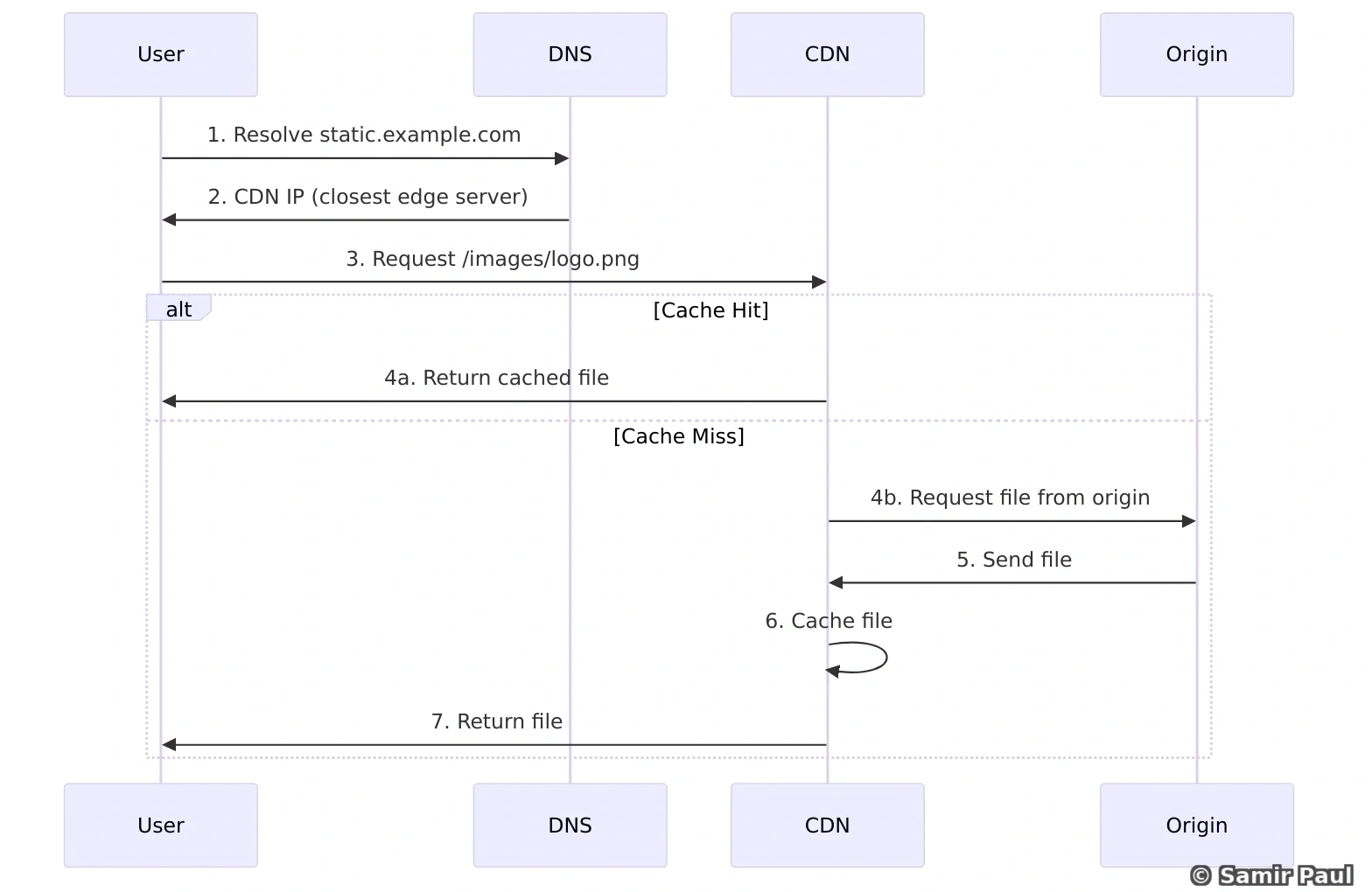
CDNs are geographically distributed networks of servers that deliver content to users based on their location.
8.1 How CDN Works
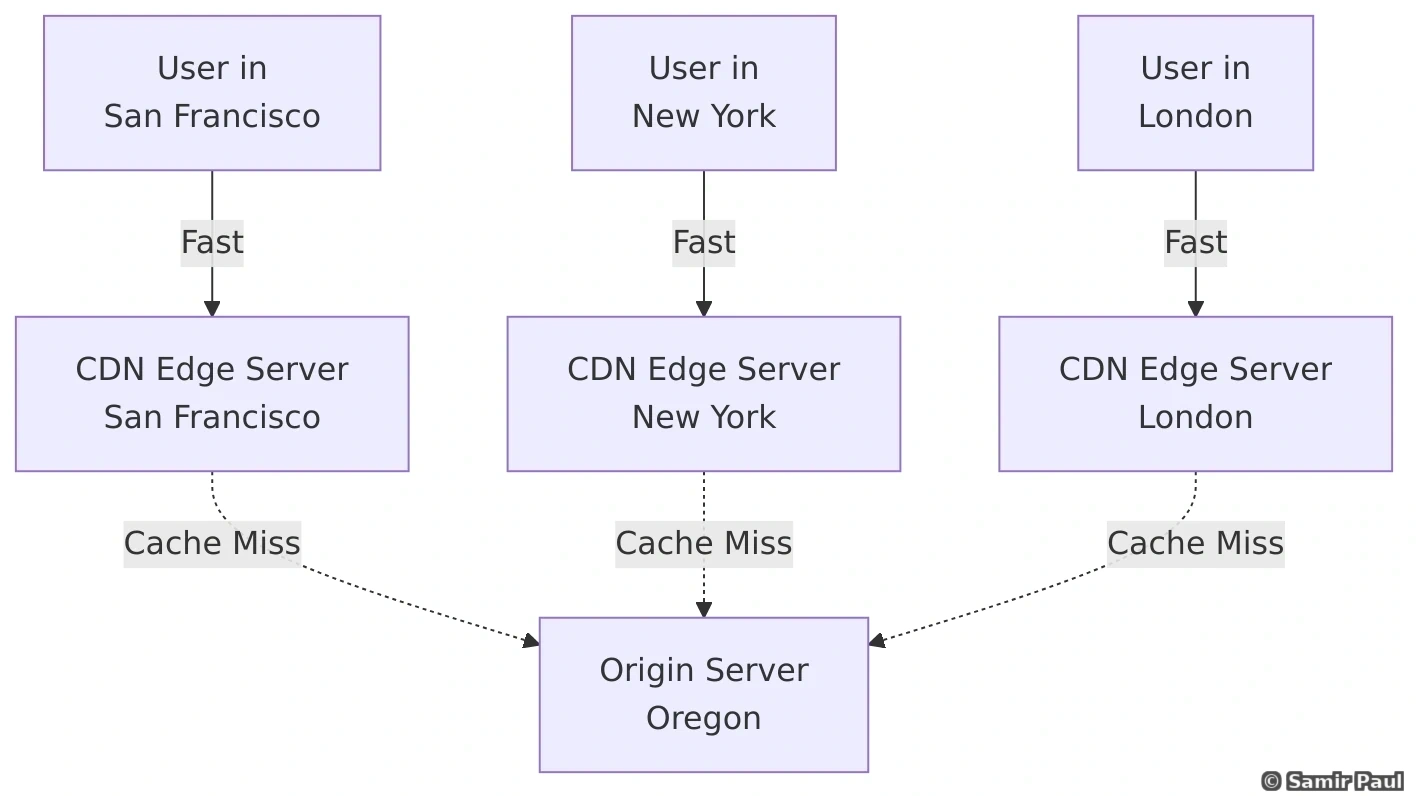
CDN Request Flow:
8.2 Benefits of CDN
Reduced Latency
- Content served from nearest location
- Fewer network hops
Reduced Origin Load
- CDN handles most traffic
- Origin serves only cache misses
Better Availability
- Multiple edge servers provide redundancy
- Can serve stale content if origin is down
DDoS Protection
- Distributed architecture absorbs attacks
- Traffic filtered at edge
Cost Savings
- Reduced bandwidth from origin
- Lower infrastructure costs
8.3 What to Put on CDN?
Static Assets (Best for CDN):
- Images
- CSS files
- JavaScript files
- Fonts
- Videos
- PDFs and downloadable files
Dynamic Content (Possible with advanced CDNs):
- API responses with caching headers
- Personalized content (with edge computing)
- HTML pages
8.4 CDN Considerations
1. Cache Invalidation
Challenge: How to update cached content?
Solutions:
a. Time-Based (TTL)
Cache-Control: max-age=86400 # Cache for 24 hoursb. Versioned URLs
/static/app.js?v=1.2.3
/static/app.1.2.3.js
/static/app.abc123hash.jsc. Cache Purge API
import requests
def purge_cdn_cache(url):
# Cloudflare example
response = requests.post(
'https://api.cloudflare.com/client/v4/zones/{zone_id}/purge_cache',
headers={'Authorization': 'Bearer {api_token}'},
json={'files': [url]}
)
return response.json()2. Cache-Control Headers
# Don't cache
Cache-Control: no-store
# Cache but revalidate
Cache-Control: no-cache
# Cache for 1 hour
Cache-Control: max-age=3600
# Cache for 1 hour, revalidate after expiry
Cache-Control: max-age=3600, must-revalidate
# Private (browser only, not CDN)
Cache-Control: private, max-age=3600
# Public (can be cached by CDN)
Cache-Control: public, max-age=86400
# Immutable (never changes)
Cache-Control: public, max-age=31536000, immutable3. CDN Push vs Pull
Pull CDN (Most Common):
- CDN fetches content from origin on first request
- Origin remains source of truth
- Lazy loading
Push CDN:
- You upload content directly to CDN
- No origin server needed
- Manual or automated uploads
9. Database Systems
9.1 SQL vs NoSQL
9.2 When to Use SQL?
ACID Guarantees: SQL databases provide ACID properties (Atomicity, Consistency, Isolation, Durability) which are critical for financial transactions, inventory management, and any scenario where data integrity cannot be compromised. If a transaction fails midway, all changes are rolled back - ensuring your data never ends up in an inconsistent state.
Use SQL (Relational Databases) When:
Data is structured and relationships are important
- E-commerce (orders, customers, products)
- Financial systems (accounts, transactions)
- CRM systems
ACID compliance is required
- Banking and financial applications
- Inventory management
- Any system where data consistency is critical
Complex queries needed
- Reporting and analytics
- Joins across multiple tables
- Aggregations and complex filtering
Data integrity constraints
- Foreign keys
- Unique constraints
- Check constraints
Example Schema (E-commerce):
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(255) UNIQUE NOT NULL,
name VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE products (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
price DECIMAL(10, 2) NOT NULL,
stock INT NOT NULL,
category_id BIGINT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (category_id) REFERENCES categories(id)
);
CREATE TABLE orders (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL,
status ENUM('pending', 'paid', 'shipped', 'delivered') DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id)
);
CREATE TABLE order_items (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
order_id BIGINT NOT NULL,
product_id BIGINT NOT NULL,
quantity INT NOT NULL,
price DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (order_id) REFERENCES orders(id),
FOREIGN KEY (product_id) REFERENCES products(id)
);9.3 When to Use NoSQL?
Use NoSQL When:
Massive scale required
- Billions of rows
- Petabytes of data
- Millions of operations per second
Schema flexibility needed
- Rapidly evolving data models
- Each record has different fields
- Semi-structured or unstructured data
High availability over consistency
- Social media feeds
- Real-time analytics
- IoT data
Denormalized data is acceptable
- Data duplication is okay
- Joins are rare
NoSQL Types:
1. Key-Value Stores (Redis, DynamoDB)
Simplest NoSQL model:
# Redis example
cache.set("user:123", json.dumps({
"name": "John Doe",
"email": "john@example.com"
}))
user = json.loads(cache.get("user:123"))Use cases:
- Session storage
- Caching
- Real-time analytics
- Shopping carts
2. Document Databases (MongoDB, CouchDB)
Store JSON-like documents:
// MongoDB example
{
"_id": ObjectId("507f1f77bcf86cd799439011"),
"name": "John Doe",
"email": "john@example.com",
"addresses": [
{
"type": "home",
"street": "123 Main St",
"city": "San Francisco",
"zip": "94102"
},
{
"type": "work",
"street": "456 Market St",
"city": "San Francisco",
"zip": "94103"
}
],
"orders": [
{"order_id": "ORD001", "total": 99.99},
{"order_id": "ORD002", "total": 149.99}
]
}Use cases:
- Content management
- User profiles
- Product catalogs
- Real-time analytics
3. Column-Family Stores (Cassandra, HBase)
Optimized for write-heavy workloads:
Row Key: user_123
Column Family: profile
name: "John Doe"
email: "john@example.com"
Column Family: activity
2024-01-15:10:30:00: "login"
2024-01-15:10:31:22: "viewed_product_456"
2024-01-15:10:35:45: "added_to_cart_456"Use cases:
- Time-series data
- Event logging
- IoT sensor data
- Message systems
4. Graph Databases (Neo4j, Amazon Neptune)
Optimized for relationships:
// Neo4j example
(John:Person {name: "John Doe"})
-[:FRIENDS_WITH]->(Jane:Person {name: "Jane Smith"})
-[:WORKS_AT]->(Company:Company {name: "Acme Corp"})
<-[:WORKS_AT]-(Bob:Person {name: "Bob Johnson"})
-[:LIKES]->(Product:Product {name: "Widget"})Use cases:
- Social networks
- Recommendation engines
- Fraud detection
- Knowledge graphs
9.4 Database Performance Optimization
Performance Optimization Hierarchy: Follow this order for maximum impact:
- Add indexes on frequently queried columns (10-100x speedup)
- Optimize slow queries using EXPLAIN (5-50x speedup)
- Add caching layer for hot data (10-100x speedup)
- Scale reads with replicas when CPU-bound (linear scaling)
- Shard database only when vertical scaling exhausted (adds complexity)
1. Indexing
Index Trade-offs: Every index speeds up reads but slows down writes. An insert/update/delete must update all indexes on that table. A table with 10 indexes will have 10x slower writes. Only index columns that are frequently used in WHERE, JOIN, or ORDER BY clauses. Monitor index usage with EXPLAIN and remove unused indexes.
Indexes speed up queries but slow down writes:
-- Create index
CREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_products_category ON products(category_id);
-- Composite index
CREATE INDEX idx_orders_user_status ON orders(user_id, status);
-- Full-text index
CREATE FULLTEXT INDEX idx_products_search ON products(name, description);Types of Indexes:
- B-Tree Index (default): Good for equality and range queries
- Hash Index: Only for equality comparisons
- Full-Text Index: For text search
- Spatial Index: For geographic data
Index Best Practices:
- Index columns used in WHERE, JOIN, ORDER BY
- Don’t over-index (slows writes)
- Use composite indexes for multi-column queries
- Monitor index usage and remove unused indexes
2. Query Optimization
-- Bad: SELECT *
SELECT * FROM users WHERE email = 'john@example.com';
-- Good: Select only needed columns
SELECT id, name, email FROM users WHERE email = 'john@example.com';
-- Use EXPLAIN to analyze queries
EXPLAIN SELECT * FROM orders
WHERE user_id = 123 AND status = 'pending';
-- Avoid N+1 queries
-- Bad: Query in loop
for user_id in user_ids:
orders = db.query(f"SELECT * FROM orders WHERE user_id = {user_id}")
-- Good: Single query
orders = db.query(f"SELECT * FROM orders WHERE user_id IN ({','.join(user_ids)})")3. Connection Pooling
import psycopg2
from psycopg2 import pool
# Create connection pool
connection_pool = pool.SimpleConnectionPool(
minconn=5,
maxconn=20,
host="localhost",
database="mydb",
user="user",
password="password"
)
def execute_query(query):
conn = connection_pool.getconn()
try:
cursor = conn.cursor()
cursor.execute(query)
result = cursor.fetchall()
return result
finally:
connection_pool.putconn(conn)10. Database Sharding and Partitioning
Sharding: Last Resort Scaling: Sharding adds significant complexity - cross-shard joins become application-level operations, distributed transactions are complex, and rebalancing data is challenging. Exhaust these options first: (1) Optimize queries and add indexes, (2) Add read replicas, (3) Vertical scaling (bigger machine), (4) Caching layer. Only shard when you absolutely must handle massive scale (billions of rows, millions of QPS).
When a single database can’t handle the load, we need to split data across multiple databases.
10.1 Vertical vs Horizontal Partitioning
Vertical Partitioning (Splitting by columns)
Original Table:
users: id, name, email, address, bio, profile_pic
Split into:
users_basic: id, name, email
users_extended: id, address, bio, profile_picUse when:
- Different columns accessed with different frequencies
- Some columns are rarely used
- Reduce I/O for common queries
Horizontal Partitioning/Sharding (Splitting by rows)
users table split by region:
users_us: All US users
users_eu: All EU users
users_asia: All ASIA users10.2 Sharding Strategies
Choosing a Sharding Strategy:
- Range-Based: Use for time-series data or when range queries are common (e.g., “get all orders from last month”)
- Hash-Based: Best for even distribution and single-key lookups (e.g., user profiles, sessions)
- Geographic: Essential for data residency compliance (GDPR, data sovereignty laws)
- Directory-Based: Most flexible but adds latency and single point of failure (shard directory)
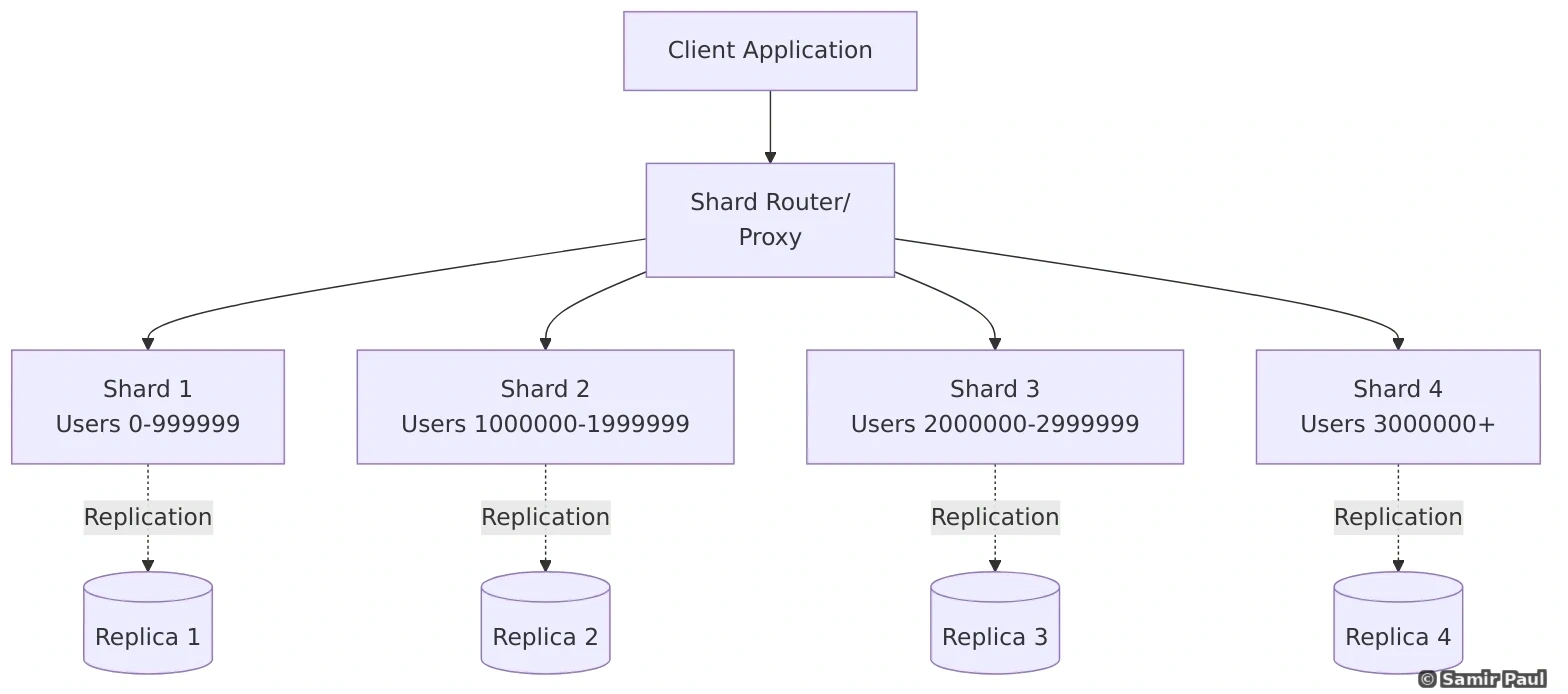
1. Range-Based Sharding
Split data based on ranges:
def get_shard_by_range(user_id):
if user_id < 1000000:
return "shard_1"
elif user_id < 2000000:
return "shard_2"
elif user_id < 3000000:
return "shard_3"
else:
return "shard_4"Pros:
- Simple to implement
- Easy to add new ranges
Cons:
- Uneven distribution (hot shards)
- Difficult to rebalance
2. Hash-Based Sharding
Use hash function to determine shard:
import hashlib
def get_shard_by_hash(user_id, num_shards):
hash_value = int(hashlib.md5(str(user_id).encode()).hexdigest(), 16)
shard_id = hash_value % num_shards
return f"shard_{shard_id}"Pros:
- Even distribution
- Automatic balancing
Cons:
- Adding shards requires rehashing
- Range queries difficult
3. Geographic Sharding
Split by location:
def get_shard_by_geo(user_location):
if user_location in ['US', 'CA', 'MX']:
return "shard_americas"
elif user_location in ['GB', 'FR', 'DE']:
return "shard_europe"
elif user_location in ['CN', 'JP', 'IN']:
return "shard_asia"
else:
return "shard_global"Pros:
- Low latency (data close to users)
- Regulatory compliance (data residency)
Cons:
- Uneven distribution
- Cross-shard queries complex
4. Directory-Based Sharding
Maintain lookup table:
# Shard directory
shard_directory = {
"user:1": "shard_1",
"user:2": "shard_1",
"user:3": "shard_2",
"user:4": "shard_3",
}
def get_shard_by_directory(user_id):
return shard_directory.get(f"user:{user_id}", "shard_default")Pros:
- Maximum flexibility
- Easy to migrate data between shards
Cons:
- Directory is single point of failure
- Additional lookup required
10.3 Challenges with Sharding
Sharding Operational Complexity: Sharding introduces these hard problems:
- Cross-shard joins: Must fetch from multiple shards and join in application (slow)
- Distributed transactions: 2PC is slow and error-prone (avoid if possible)
- Data rebalancing: Adding shards requires massive data migration (hours/days downtime)
- Hotspots: Uneven sharding key distribution causes some shards to be overloaded
- Query routing: Routing layer becomes complex and critical
1. Cross-Shard Joins
Denormalization is Necessary: With sharding, you cannot do efficient cross-shard joins. Denormalize data by storing redundant copies across shards. Accept the write overhead and potential staleness. Example: Store user_name and user_email in orders table even though they’re in users table.
Problem: Can’t join tables across different databases.
Solution: Denormalize data or handle joins at application level:
def get_user_with_orders(user_id):
# Get shard for user
user_shard = get_shard(user_id)
user = user_shard.query(f"SELECT * FROM users WHERE id = {user_id}")
# Orders might be on different shard
order_shard = get_shard_for_orders(user_id)
orders = order_shard.query(f"SELECT * FROM orders WHERE user_id = {user_id}")
# Combine in application
user['orders'] = orders
return user2. Distributed Transactions
2PC Performance Penalty: Two-Phase Commit (2PC) requires locking all shards and coordinating across them. In MySQL, 2PC adds 20-50% latency overhead and can deadlock if timing is wrong. Better approach: Use Saga pattern - break transaction into compensating transactions, or ensure shard key is included in all transactions so data stays on one shard.
Problem: Transaction spanning multiple shards.
Solution: Two-Phase Commit (2PC) or avoid distributed transactions:
def transfer_money(from_user_id, to_user_id, amount):
from_shard = get_shard(from_user_id)
to_shard = get_shard(to_user_id)
if from_shard == to_shard:
# Same shard - normal transaction
with from_shard.transaction():
from_shard.execute(f"UPDATE accounts SET balance = balance - {amount} WHERE user_id = {from_user_id}")
to_shard.execute(f"UPDATE accounts SET balance = balance + {amount} WHERE user_id = {to_user_id}")
else:
# Different shards - use 2PC or saga pattern
# (More complex - see distributed transactions section)
pass3. Rebalancing
Problem: Adding/removing shards requires data migration.
Solution: Consistent hashing or careful planning:
def rebalance_shards(old_shards, new_shards):
# Calculate which data needs to move
for key in get_all_keys():
old_shard = hash(key) % old_shards
new_shard = hash(key) % new_shards
if old_shard != new_shard:
# Migrate data
data = get_data_from_shard(old_shard, key)
write_data_to_shard(new_shard, key, data)
delete_data_from_shard(old_shard, key)10.4 Sharding Architecture
This is Part 1 of the comprehensive guide. The document will continue with remaining sections covering Database Replication, Distributed Systems, Design Patterns, Real-World System Designs (Twitter, Google Maps, Key-Value Store, etc.), Case Studies, and extensive references.
Would you like me to continue with the next sections?
11. Database Replication
Replication Benefits: Database replication is the easiest way to scale read traffic. With 3 read replicas, you can handle 3x the read load. Replication also provides data redundancy (if master fails, promote a replica) and enables running analytics/backups on replicas without impacting production.
Database replication is the process of copying data from one database to another to ensure redundancy, improve availability, and enhance read performance.
11.1 Master-Slave Replication
The most common replication pattern:
How it works:
- All write operations go to the master database
- Master propagates changes to slave databases
- Read operations are distributed across slave databases
- Improves read performance through load distribution
Advantages:
- Better read performance (distribute reads across multiple servers)
- Data backup (slaves serve as backups)
- Analytics without impacting production (run reports on slaves)
- High availability (promote slave if master fails)
Disadvantages:
- Replication lag (slaves might be slightly behind master)
- Single point of failure for writes (only one master)
- Complexity in failover scenarios
Replication Lag Problem: Replication is usually asynchronous - slaves can be seconds or even minutes behind the master. If a user writes data and immediately reads from a replica, they might not see their own write! Solutions: (1) Read-after-write consistency (read from master for short time after write), (2) Sticky sessions (always read from same replica), or (3) Use timestamps/version numbers to detect stale reads.
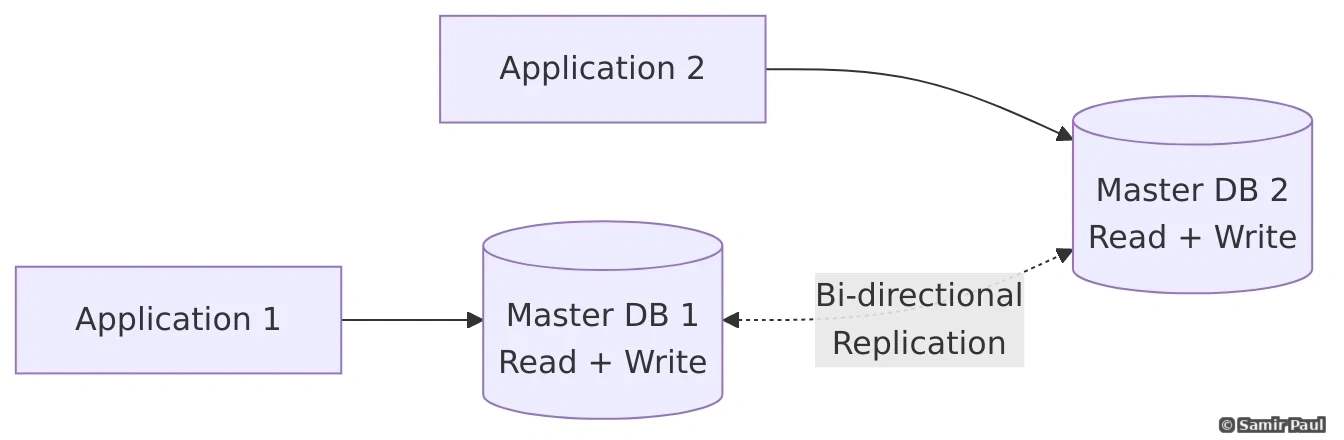
11.2 Master-Master Replication
Both databases accept writes and sync with each other:
Advantages:
- No single point of failure for writes
- Better write performance (distribute writes)
- Lower latency for geographically distributed systems
Disadvantages:
- Complex conflict resolution
- Potential for inconsistency
- More difficult to manage
Multi-Master Conflicts: With master-master replication, two masters can accept conflicting writes. Example: User A updates email to “a@example.com” on Master 1, User B updates same user’s email to “b@example.com” on Master 2. Which wins? Last-Write-Wins (LWW) is simple but can lose data. Version vectors detect conflicts but require application-level resolution. Avoid multi-master if possible.
Conflict Resolution Strategies:
# Last Write Wins (LWW)
def resolve_conflict_lww(value1, value2):
"""
Choose the value with the latest timestamp
"""
if value1.timestamp > value2.timestamp:
return value1
return value2
# Version Vector
class VersionVector:
def __init__(self):
self.vector = {}
def increment(self, node_id):
self.vector[node_id] = self.vector.get(node_id, 0) + 1
def merge(self, other):
"""Merge two version vectors"""
for node_id, version in other.vector.items():
self.vector[node_id] = max(
self.vector.get(node_id, 0),
version
)
def compare(self, other):
"""
Returns:
- 'before' if self < other
- 'after' if self > other
- 'concurrent' if conflicting
"""
self_greater = False
other_greater = False
all_nodes = set(self.vector.keys()) | set(other.vector.keys())
for node in all_nodes:
self_ver = self.vector.get(node, 0)
other_ver = other.vector.get(node, 0)
if self_ver > other_ver:
self_greater = True
elif other_ver > self_ver:
other_greater = True
if self_greater and not other_greater:
return 'after'
elif other_greater and not self_greater:
return 'before'
else:
return 'concurrent'11.3 Replication Methods
Synchronous Replication:
- Master waits for slave acknowledgment before confirming write
- Strong consistency
- Higher latency
- Used when data consistency is critical
def synchronous_write(data):
# Write to master
master.write(data)
# Wait for all slaves to acknowledge
for slave in slaves:
slave.write(data)
slave.acknowledge()
return "Write successful"Asynchronous Replication:
- Master confirms write immediately
- Slaves updated eventually
- Lower latency
- Risk of data loss if master fails
def asynchronous_write(data):
# Write to master
master.write(data)
# Queue replication (don't wait)
for slave in slaves:
replication_queue.enqueue({
'slave': slave,
'data': data
})
return "Write successful"Semi-Synchronous Replication:
- Master waits for at least one slave
- Balance between consistency and performance
12. Distributed Systems Concepts
12.1 What is a Distributed System?
Characteristics:
- Multiple autonomous computers: Independent nodes with their own CPU, memory, and storage
- Connected through a network: Communication via TCP/IP, message queues, or RPC
- Coordinate actions through message passing: No shared memory between nodes
- No shared memory: Each node has isolated memory space
- Failures are partial: Some components can fail while others continue working
Benefits:
- Scalability: Handle more load by adding machines (horizontal scaling)
- Reliability: System continues working even if components fail
- Performance: Process data closer to users (reduced latency)
- Availability: No single point of failure with proper design
Challenges:
- Network is unreliable: Messages can be lost or delayed
- Partial failures: Some components fail while others work
- Synchronization: Coordinating actions is difficult without shared memory
- Consistency: Keeping data consistent across nodes is complex
12.2 Fallacies of Distributed Computing
Eight assumptions developers wrongly make about distributed systems:
The network is reliable
- Reality: Networks fail, packets are lost, connections drop
Latency is zero
- Reality: Network calls are slow (milliseconds to seconds)
Bandwidth is infinite
- Reality: Network capacity is limited and shared
The network is secure
- Reality: Networks can be compromised, data can be intercepted
Topology doesn’t change
- Reality: Network topology changes frequently (servers added/removed, DNS changes)
There is one administrator
- Reality: Multiple teams manage different parts of the system
Transport cost is zero
- Reality: Serialization and network transfer have CPU and bandwidth costs
The network is homogeneous
- Reality: Different protocols, formats, and vendors across the network
13. CAP Theorem and Consistency Models
13.1 CAP Theorem
The CAP theorem states that a distributed system can provide at most TWO of the following three guarantees simultaneously:
- C (Consistency): All nodes see the same data at the same time
- A (Availability): Every request receives a response (success or failure)
- P (Partition Tolerance): System continues operating despite network partitions
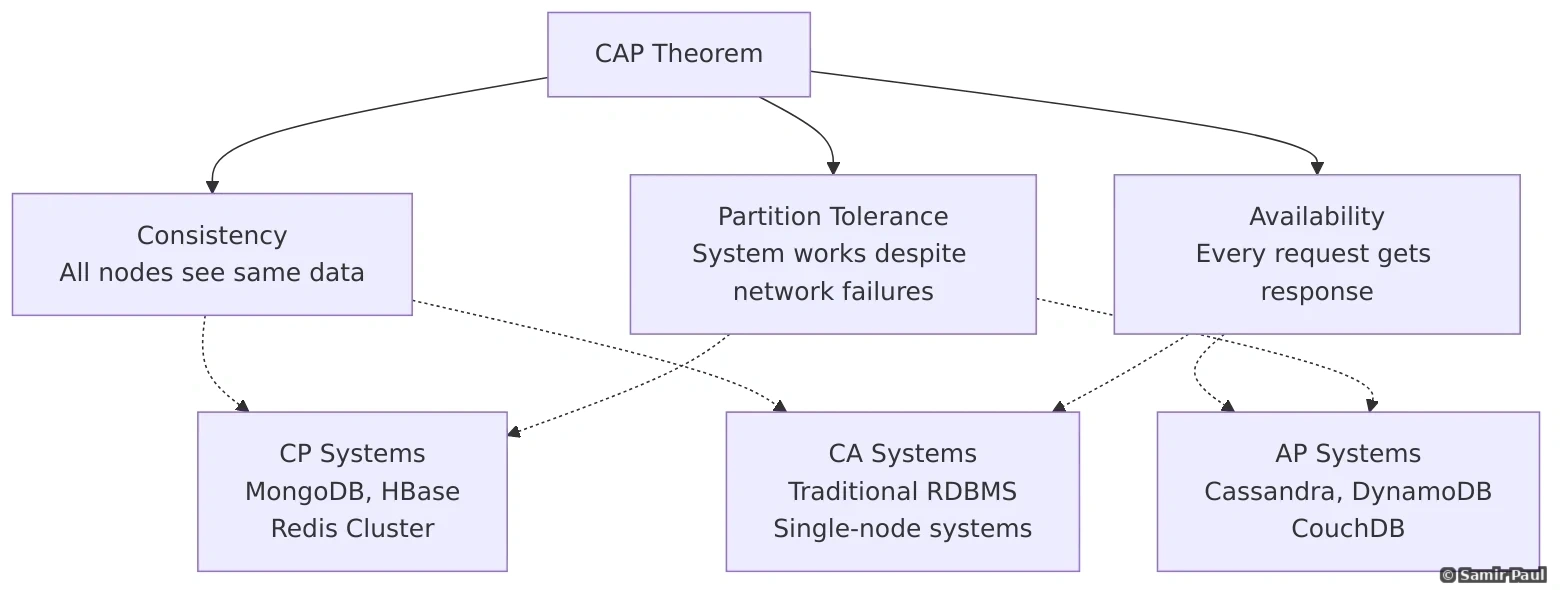
In Reality:
- Network partitions will happen (P is mandatory)
- Must choose between C and A during partition
- When partition heals, system needs reconciliation strategy
Partition Tolerance is Mandatory: In the real world, network partitions WILL happen - switches fail, network cables get cut, data centers lose connectivity. You cannot choose “CA” because you cannot avoid network partitions. The real choice is: During a partition, do you want Consistency (CP) or Availability (AP)?
CP Systems (Consistency + Partition Tolerance):
- Wait for partition to heal
- Return errors during partition
- Example: Banking systems, MongoDB (with majority write concern)
CP System Trade-off: CP systems (like banking systems) choose to be unavailable during network partitions rather than show inconsistent data. If you can’t reach a quorum of nodes, writes fail. This prevents showing incorrect account balances but means some operations fail during network issues.
AP Systems (Availability + Partition Tolerance):
- Always accept reads/writes
- Resolve conflicts later
- Example: Social media feeds, DNS, Cassandra
AP System Trade-off: AP systems (like social media feeds) stay available during network partitions but accept eventual consistency. You might temporarily see old data or conflicting updates, but the system never returns errors. Facebook chooses AP - it’s better to show a slightly stale news feed than to be completely unavailable.
13.2 Consistency Models
Consistency Model Selection: Choose based on your use case:
- Strong Consistency: Financial transactions, inventory systems (can’t sell same item twice)
- Eventual Consistency: Social media feeds, analytics, caching (temporary staleness is acceptable)
- Read-Your-Writes: User profiles, settings (users must see their own changes immediately)
- Causal Consistency: Comment threads, chat (replies must appear after original message)
Strong Consistency:
- After a write, all reads see that value
- Highest consistency guarantee
- Higher latency
def strong_consistency_read():
# Read from master or wait for replication
return master.read()Eventual Consistency:
- If no new updates, eventually all reads return same value
- Lower latency
- Used in AP systems
def eventual_consistency_read():
# Read from any replica
# Might return stale data
return random.choice(replicas).read()Read-Your-Writes Consistency:
- Users see their own writes immediately
- Others might see stale data
session_writes = {}
def write(user_id, data):
master.write(data)
session_writes[user_id] = time.now()
def read(user_id):
if user_id in session_writes:
# Read from master for this user
return master.read()
else:
# Can read from replica for others
return replica.read()Monotonic Reads:
- If user reads value A, subsequent reads won’t return older values
user_last_read_time = {}
def monotonic_read(user_id):
last_time = user_last_read_time.get(user_id, 0)
# Only read from replicas caught up to last_time
valid_replicas = [
r for r in replicas
if r.last_sync_time >= last_time
]
result = random.choice(valid_replicas).read()
user_last_read_time[user_id] = time.now()
return resultCausal Consistency:
- Related operations are seen in correct order
- Independent operations can be seen in any order
13.3 BASE Properties
Alternative to ACID for distributed systems:
- Basically Available: System appears to work most of the time
- Soft state: State may change without input (due to eventual consistency)
- Eventual consistency: System becomes consistent over time
14. Message Queues and Event-Driven Architecture
14.1 Why Message Queues?
Message queues enable asynchronous communication between services with these benefits:
1. Decoupling: Services don’t need to know about each other directly
- Producers and consumers are independent
- Can evolve separately without coordination
2. Reliability: Messages persisted until successfully processed
- Messages won’t be lost if consumer is down
- Retry mechanisms for failed processing
3. Scalability: Add more consumers to handle increased load
- Horizontal scaling of message processing
- Load distribution across multiple consumers
4. Buffering: Handle traffic spikes gracefully
- Queue absorbs burst traffic
- Consumers process at sustainable rate
14.2 Message Queue Patterns
1. Point-to-Point (Queue)
Each message consumed by exactly one consumer:
class MessageQueue:
def __init__(self):
self.queue = []
self.lock = threading.Lock()
def send(self, message):
with self.lock:
self.queue.append(message)
def receive(self):
with self.lock:
if self.queue:
return self.queue.pop(0)
return None
# Usage
queue = MessageQueue()
# Producer
queue.send({"order_id": 123, "action": "process"})
# Consumer
message = queue.receive()
if message:
process_order(message)2. Publish-Subscribe (Topic)
Each message consumed by all subscribers:
class PubSubTopic:
def __init__(self):
self.subscribers = []
self.messages = []
def subscribe(self, subscriber):
self.subscribers.append(subscriber)
def publish(self, message):
for subscriber in self.subscribers:
subscriber.receive(message)
# Usage
topic = PubSubTopic()
# Subscribers
email_service = EmailService()
sms_service = SMSService()
push_service = PushService()
topic.subscribe(email_service)
topic.subscribe(sms_service)
topic.subscribe(push_service)
# Publisher
topic.publish({"event": "order_placed", "user_id": 123})
# All three services receive the message14.3 Popular Message Queue Systems
RabbitMQ:
- Feature-rich
- Complex routing
- Good for traditional message queueing
Apache Kafka:
- High throughput
- Log-based
- Great for event streaming
- Stores messages for replay
Amazon SQS:
- Fully managed
- Simple to use
- Good for AWS ecosystem
Redis Pub/Sub:
- Very fast (in-memory)
- Simple pub/sub
- No message persistence
14.4 Event-Driven Architecture Example
# Event Bus
class EventBus:
def __init__(self):
self.handlers = {}
def subscribe(self, event_type, handler):
if event_type not in self.handlers:
self.handlers[event_type] = []
self.handlers[event_type].append(handler)
def publish(self, event):
event_type = event.get('type')
if event_type in self.handlers:
for handler in self.handlers[event_type]:
try:
handler(event)
except Exception as e:
print(f"Handler error: {e}")
# Services
def send_confirmation_email(event):
user_id = event['user_id']
order_id = event['order_id']
print(f"Sending email to user {user_id} for order {order_id}")
def update_inventory(event):
items = event['items']
print(f"Updating inventory for {items}")
def send_notification(event):
user_id = event['user_id']
print(f"Sending push notification to user {user_id}")
# Setup
event_bus = EventBus()
event_bus.subscribe('order_placed', send_confirmation_email)
event_bus.subscribe('order_placed', update_inventory)
event_bus.subscribe('order_placed', send_notification)
# Trigger event
event_bus.publish({
'type': 'order_placed',
'order_id': 12345,
'user_id': 789,
'items': ['item1', 'item2']
})15. Microservices Architecture
15.1 Monolith vs Microservices
Monolith Advantages:
- Simple to develop and test
- Easy deployment
- Good for small teams
- Lower latency (no network calls)
Monolith Disadvantages:
- Difficult to scale
- Long deployment times
- One bug can bring down entire system
- Hard to adopt new technologies
Microservices Advantages:
- Independent scaling
- Technology diversity
- Fault isolation
- Faster deployment
- Team autonomy
Microservices Disadvantages:
- Increased complexity
- Network latency
- Data consistency challenges
- Testing is harder
- Operational overhead
15.2 Microservices Best Practices
1. Single Responsibility
Each service should do one thing well:
Good:
- UserService: Manages users
- OrderService: Manages orders
- EmailService: Sends emails
Bad:
- UserOrderEmailService: Does everything2. Database per Service
Each service has its own database:
# User Service
class UserService:
def __init__(self):
self.db = UserDatabase()
def create_user(self, data):
return self.db.insert(data)
def get_user(self, user_id):
return self.db.query(user_id)
# Order Service
class OrderService:
def __init__(self):
self.db = OrderDatabase() # Different database
self.user_service = UserServiceClient()
def create_order(self, user_id, items):
# Get user info via API (not direct DB access)
user = self.user_service.get_user(user_id)
order = {
'user_id': user_id,
'items': items,
'total': self.calculate_total(items)
}
return self.db.insert(order)3. API Gateway Pattern
Single entry point for all clients:
class APIGateway:
def __init__(self):
self.user_service = UserServiceClient()
self.order_service = OrderServiceClient()
self.product_service = ProductServiceClient()
def get_user_dashboard(self, user_id):
# Aggregate data from multiple services
user = self.user_service.get_user(user_id)
orders = self.order_service.get_user_orders(user_id)
recommendations = self.product_service.get_recommendations(user_id)
return {
'user': user,
'recent_orders': orders[:5],
'recommended_products': recommendations
}4. Circuit Breaker Pattern
Prevent cascading failures:
from enum import Enum
import time
class CircuitState(Enum):
CLOSED = "closed" # Normal operation
OPEN = "open" # Failing, reject requests
HALF_OPEN = "half_open" # Testing if recovered
class CircuitBreaker:
def __init__(self, failure_threshold=5, timeout=60):
self.failure_count = 0
self.failure_threshold = failure_threshold
self.timeout = timeout
self.state = CircuitState.CLOSED
self.last_failure_time = None
def call(self, func, *args, **kwargs):
if self.state == CircuitState.OPEN:
if time.time() - self.last_failure_time > self.timeout:
self.state = CircuitState.HALF_OPEN
else:
raise Exception("Circuit breaker is OPEN")
try:
result = func(*args, **kwargs)
self.on_success()
return result
except Exception as e:
self.on_failure()
raise e
def on_success(self):
self.failure_count = 0
self.state = CircuitState.CLOSED
def on_failure(self):
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.failure_threshold:
self.state = CircuitState.OPEN
# Usage
payment_circuit = CircuitBreaker(failure_threshold=5, timeout=60)
def process_payment(amount):
return payment_circuit.call(payment_service.charge, amount)This completes Part II. The document continues with Part III covering Design Patterns, Real-World System Designs, and Case Studies.
25. Scaling from Zero to Million Users
25.1 Stage 1: Single Server
Architecture:
- All code in one place
- Single database
- Simple deployment
- No external services
Configuration:
- 1 web server
- 1 database
- ~1,000-5,000 concurrent users
Issues emerge when:
- Single point of failure
- Can’t scale beyond server capacity
- Database bottleneck
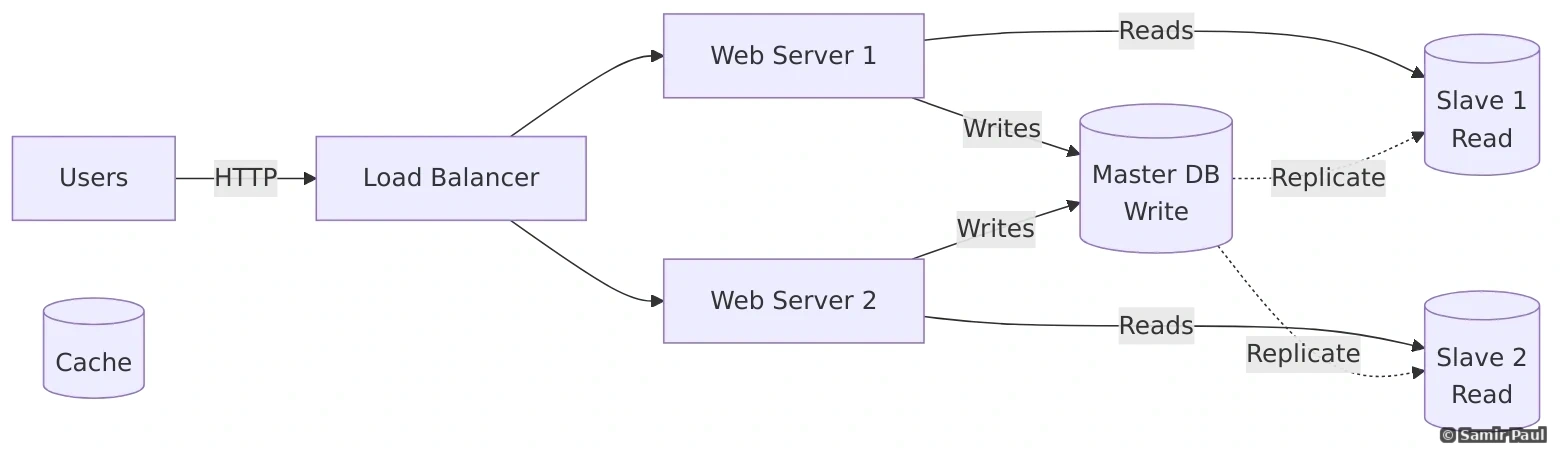
25.2 Stage 2: Separate Web and Database Tiers
Changes:
- Add load balancer (distribute traffic)
- Multiple web servers (can scale horizontally)
- Separate database (can upgrade independently)
Capacity:
- ~100,000 concurrent users
- Load balancer: 1-2 Gbps throughput
- Web servers: 5-10 servers
- Database: Single instance (might be beefy)
Implementation Example:
# Load Balancer (Round Robin)
class LoadBalancer:
def __init__(self, servers):
self.servers = servers
self.current = 0
def route_request(self, request):
server = self.servers[self.current]
self.current = (self.current + 1) % len(self.servers)
return server.handle(request)
# Web Servers (Stateless)
class WebServer:
def __init__(self, db_connection):
self.db = db_connection
def handle(self, request):
if request.path == '/users/123':
user = self.db.query(f"SELECT * FROM users WHERE id = 123")
return json.dumps(user)
# Setup
servers = [WebServer(db_connection), WebServer(db_connection)]
lb = LoadBalancer(servers)25.3 Stage 3: Add Caching Layer
Benefits:
- Reduce database load
- Faster response times
- Better user experience
Implementation:
from functools import wraps
import time
class CachingWebServer:
def __init__(self, db, cache):
self.db = db
self.cache = cache
def get_user(self, user_id):
# Check cache first
cache_key = f"user:{user_id}"
cached_user = self.cache.get(cache_key)
if cached_user:
return cached_user
# Cache miss - query database
user = self.db.query(f"SELECT * FROM users WHERE id = {user_id}")
# Store in cache for 1 hour
self.cache.set(cache_key, user, ttl=3600)
return user25.4 Stage 4: Add CDN for Static Content
CDN Benefits:
- Serve content from location closest to user
- Reduce origin server load
- Faster page loads globally
- Lower bandwidth costs
25.5 Stage 5: Database Replication
Benefits:
- Master for writes
- Slaves for reads
- Better read performance
- High availability
25.6 Stage 6: Database Sharding
When to shard:
- Database size > 1TB
- Single master at capacity
- Need to scale beyond vertical limits
Sharding key considerations:
- Even distribution
- Immutable after shard creation
- Avoid hot keys
25.7 Stage 7: Message Queue for Async Processing
Benefits:
- Non-blocking operations
- Decouple producers and consumers
- Scale workers independently
- Handle traffic spikes
19. Unique ID Generation in Distributed Systems
Generating globally unique IDs is critical for distributed systems.
19.1 Requirements
Unique IDs must be:
- Unique across all servers
- Sortable (roughly ordered by time)
- Decentralized (no single point of failure)
- Fast generation
- Fit in 64 bits (for efficiency)
19.2 Snowflake ID Algorithm
Twitter’s Snowflake algorithm is industry standard:
| 1 | 41 | 10 | 12 |
|Unused |Timestamp |Machine ID |Sequence|
|1 bit |ms since |Data center|Counter |
| |epoch |+ Worker | |Structure (64 bits):
- Bit 0: Unused (ensures positive numbers)
- Bits 1-41: Timestamp (42 bits, milliseconds since epoch)
- Bits 42-51: Machine ID (10 bits, 1024 machines)
- Bits 52-63: Sequence number (12 bits, 4096 IDs per ms per machine)
Capacity:
- 2^41 timestamps ≈ 69 years
- 2^10 machines = 1,024 machines
- 2^12 sequences = 4,096 IDs per millisecond per machine
- Total: ~4 million IDs per second per machine
Implementation:
import time
import threading
class SnowflakeIDGenerator:
EPOCH = 1288834974657 # Twitter Epoch
WORKER_ID_BITS = 10
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12
MAX_WORKER_ID = (1 << WORKER_ID_BITS) - 1
MAX_DATACENTER_ID = (1 << DATACENTER_ID_BITS) - 1
MAX_SEQUENCE = (1 << SEQUENCE_BITS) - 1
WORKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
def __init__(self, worker_id, datacenter_id):
if worker_id > self.MAX_WORKER_ID or worker_id < 0:
raise ValueError(f"Worker ID must be <= {self.MAX_WORKER_ID}")
if datacenter_id > self.MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError(f"Datacenter ID must be <= {self.MAX_DATACENTER_ID}")
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = 0
self.last_timestamp = -1
self.lock = threading.Lock()
def _current_timestamp(self):
return int(time.time() * 1000)
def generate_id(self):
with self.lock:
timestamp = self._current_timestamp()
if timestamp < self.last_timestamp:
raise Exception("Clock moved backwards")
if timestamp == self.last_timestamp:
self.sequence += 1
if self.sequence > self.MAX_SEQUENCE:
# Wait for next millisecond
timestamp = self._current_timestamp()
self.sequence = 0
else:
self.sequence = 0
self.last_timestamp = timestamp
id = (
(timestamp - self.EPOCH) << self.TIMESTAMP_SHIFT |
self.datacenter_id << self.DATACENTER_ID_SHIFT |
self.worker_id << self.WORKER_ID_SHIFT |
self.sequence
)
return id
# Usage
id_gen = SnowflakeIDGenerator(worker_id=1, datacenter_id=1)
for _ in range(5):
print(id_gen.generate_id())19.3 Other ID Generation Methods
UUID:
- 128 bits
- Guaranteed unique
- Not sortable
- Larger ID size
Database Auto-Increment:
- Simple
- Requires network call
- Single point of failure potential
- Exposes data volume
Timestamp + Random:
- Simple
- Sortable
- Risk of collision with multiple generators
26. Design a Key-Value Store
26.1 Requirements
Functional:
- GET(key): retrieve value
- PUT(key, value): store value
- DELETE(key): remove value
Non-Functional:
- Single node (vertical scalability only)
- O(1) time complexity for all operations
- Persistent storage
- Efficient memory usage
- Hardware-aware optimization
26.2 Architecture
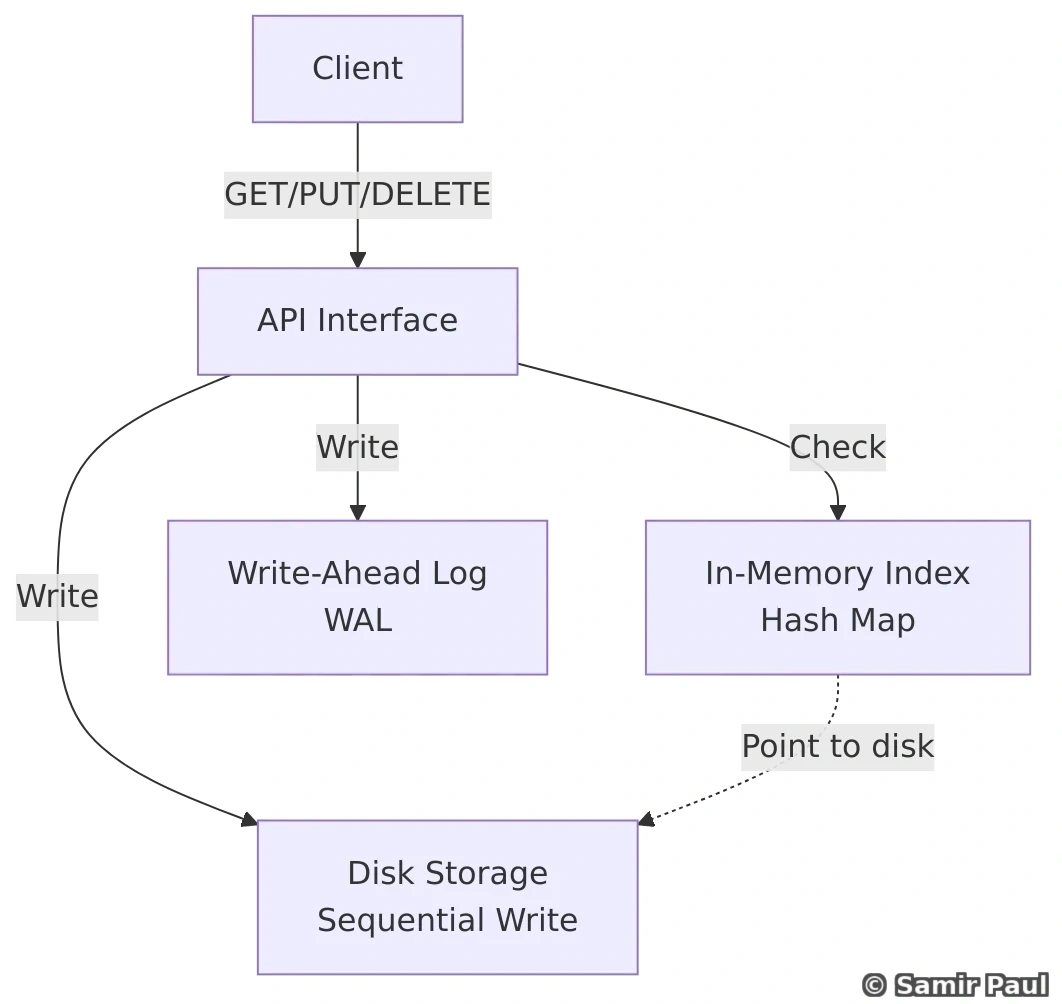
26.3 Implementation
import os
import json
import time
from threading import Lock
class SimpleKVStore:
def __init__(self, data_dir="./data"):
self.data_dir = data_dir
self.memory_index = {} # In-memory hash map
self.wal_file = os.path.join(data_dir, "wal.log") # Write-ahead log
self.data_file = os.path.join(data_dir, "data.db") # Actual data
self.lock = Lock()
os.makedirs(data_dir, exist_ok=True)
self._load_from_disk()
def _load_from_disk(self):
"""Load index from disk on startup"""
if os.path.exists(self.wal_file):
with open(self.wal_file, 'r') as f:
for line in f:
entry = json.loads(line.strip())
if entry['op'] == 'PUT':
self.memory_index[entry['key']] = entry['value']
elif entry['op'] == 'DELETE':
self.memory_index.pop(entry['key'], None)
def get(self, key):
with self.lock:
if key not in self.memory_index:
return None
return self.memory_index[key]
def put(self, key, value):
with self.lock:
# Write-ahead log (WAL)
entry = {'op': 'PUT', 'key': key, 'value': value, 'timestamp': time.time()}
with open(self.wal_file, 'a') as f:
f.write(json.dumps(entry) + '\n')
# Update in-memory index
self.memory_index[key] = value
# Periodic flush to disk (simplified)
if len(self.memory_index) % 1000 == 0:
self._flush_to_disk()
def delete(self, key):
with self.lock:
if key not in self.memory_index:
return False
# Write deletion to WAL
entry = {'op': 'DELETE', 'key': key, 'timestamp': time.time()}
with open(self.wal_file, 'a') as f:
f.write(json.dumps(entry) + '\n')
# Remove from memory
del self.memory_index[key]
return True
def _flush_to_disk(self):
"""Periodically flush in-memory index to disk"""
with open(self.data_file, 'w') as f:
for key, value in self.memory_index.items():
f.write(f"{key}={json.dumps(value)}\n")
# Usage
store = SimpleKVStore()
store.put("user:1", {"name": "Alice", "age": 30})
store.put("user:2", {"name": "Bob", "age": 25})
print(store.get("user:1")) # {"name": "Alice", "age": 30}
store.delete("user:2")
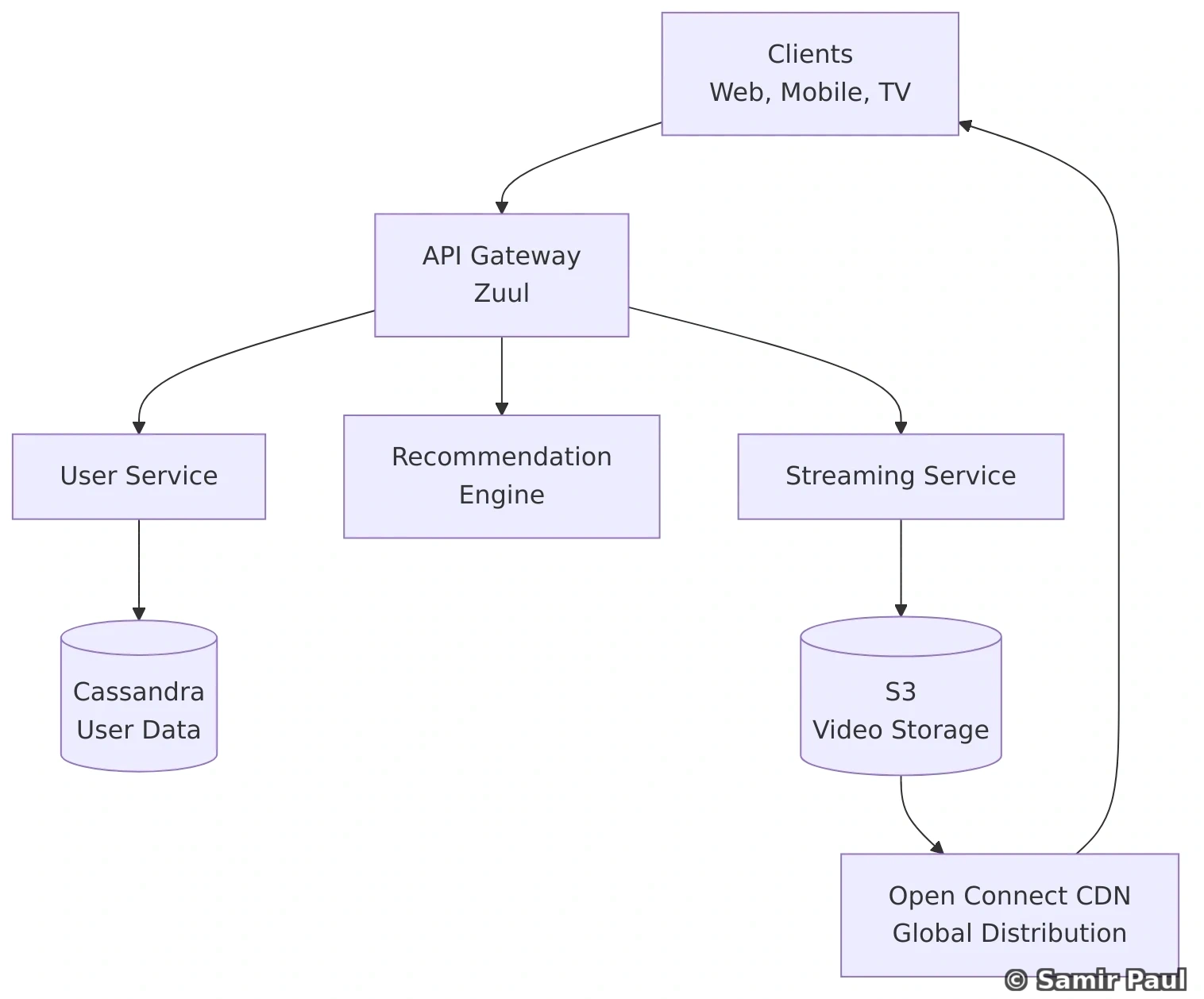
print(store.get("user:2")) # None28. Design Twitter with Microservices
28.1 High-Level Architecture
28.2 Core Services Explained
Tweet Service:
- Create, read, update, delete tweets
- Validate tweet content
- Handle media uploads
- Publish tweet events
Feed Service:
- Generate personalized feed
- Combine tweets from followed accounts
- Sort chronologically
- Cache frequently accessed feeds
Search Service:
- Full-text search on tweets
- Handle hashtags
- Trending topics
- Use Elasticsearch or similar
Follow Service:
- Manage follower/following relationships
- Social graph
- Notification for new followers
28.3 Handling the “Thundering Herd”
Challenge: When celebrity tweets, millions access simultaneously.
Solution: Fan-Out Cache
# When a celebrity tweets
def create_celebrity_tweet(user_id, content):
tweet = TweetService.create(user_id, content)
# Get all followers
followers = FollowService.get_followers(user_id)
# Pre-populate feeds for active followers
for follower_id in followers[:100000]: # Top 100K followers
feed_key = f"feed:{follower_id}"
cache.prepend(feed_key, tweet) # Add to front of feed
# Enqueue notification
notification_queue.enqueue({
'user_id': follower_id,
'event': 'new_tweet',
'from_user': user_id
})29. Design Google Maps / Location-Based Services
29.1 Architecture Overview
29.2 Geospatial Indexing
Storing location data efficiently:
# Using Geohash for spatial indexing
def geohash_encode(latitude, longitude, precision=5):
"""
Geohash encodes lat/long into a short string
Nearby locations have similar geohashes
"""
# Simplified geohash (actual implementation is more complex)
lat_bits = bin(int((latitude + 90) / 180 * (2 ** 20)))[2:].zfill(20)
lon_bits = bin(int((longitude + 180) / 360 * (2 ** 20)))[2:].zfill(20)
# Interleave bits
interleaved = ''.join(lon_bits[i] + lat_bits[i] for i in range(20))
# Convert to base32
base32 = "0123456789bcdefghjkmnpqrstuvwxyz"
geohash = ''
for i in range(0, len(interleaved), 5):
chunk = interleaved[i:i+5]
geohash += base32[int(chunk, 2)]
return geohash[:precision]
# Nearby search using geohash
def find_nearby_places(latitude, longitude, radius_km=1):
"""Find all places within radius"""
center_geohash = geohash_encode(latitude, longitude, precision=7)
# Get geohashes for surrounding cells
nearby_geohashes = get_neighbors(center_geohash)
places = []
for geohash in nearby_geohashes:
# Query database for places with this geohash prefix
db_places = PlaceDB.query(f"geohash LIKE '{geohash}%'")
# Filter by distance
for place in db_places:
dist = haversine_distance(latitude, longitude, place.lat, place.lon)
if dist <= radius_km:
places.append(place)
return places
def haversine_distance(lat1, lon1, lat2, lon2):
"""Calculate distance between two points in km"""
import math
R = 6371 # Earth radius in km
dlat = math.radians(lat2 - lat1)
dlon = math.radians(lon2 - lon1)
a = math.sin(dlat/2)**2 + math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) * math.sin(dlon/2)**2
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
return R * c29.3 Direction Finding (Shortest Path)
# Simplified Dijkstra's algorithm for shortest path
import heapq
class DirectionFinder:
def __init__(self, road_network):
self.graph = road_network # Graph of intersections and roads
def find_shortest_path(self, start_id, end_id):
"""Find shortest path between two locations"""
distances = {start_id: 0}
previous = {}
pq = [(0, start_id)] # (distance, node)
visited = set()
while pq:
current_dist, current_node = heapq.heappop(pq)
if current_node in visited:
continue
visited.add(current_node)
# Check neighbors
for neighbor, weight in self.graph[current_node]:
if neighbor in visited:
continue
new_dist = current_dist + weight
if neighbor not in distances or new_dist < distances[neighbor]:
distances[neighbor] = new_dist
previous[neighbor] = current_node
heapq.heappush(pq, (new_dist, neighbor))
# Reconstruct path
path = []
current = end_id
while current in previous:
path.append(current)
current = previous[current]
path.append(start_id)
path.reverse()
return path, distances.get(end_id, float('inf'))17. Rate Limiting
17.1 Rate Limiting Algorithms
1. Token Bucket Algorithm
Pre-calculated tokens in a bucket, remove on each request:
import time
from threading import Lock
class TokenBucket:
def __init__(self, capacity, refill_rate):
"""
capacity: max tokens in bucket
refill_rate: tokens added per second
"""
self.capacity = capacity
self.refill_rate = refill_rate
self.tokens = capacity
self.last_refill = time.time()
self.lock = Lock()
def allow_request(self, tokens=1):
with self.lock:
self._refill()
if self.tokens >= tokens:
self.tokens -= tokens
return True
return False
def _refill(self):
now = time.time()
elapsed = now - self.last_refill
self.tokens = min(
self.capacity,
self.tokens + elapsed * self.refill_rate
)
self.last_refill = now
# Usage
bucket = TokenBucket(capacity=10, refill_rate=1) # 10 tokens, 1 per second
for i in range(15):
if bucket.allow_request():
print(f"Request {i+1}: Allowed")
else:
print(f"Request {i+1}: Rate limited")2. Leaky Bucket Algorithm
Drain bucket at fixed rate:
from collections import deque
import time
from threading import Lock
class LeakyBucket:
def __init__(self, capacity, outflow_rate):
"""
capacity: max requests in queue
outflow_rate: requests processed per second
"""
self.capacity = capacity
self.outflow_rate = outflow_rate
self.queue = deque()
self.last_leak = time.time()
self.lock = Lock()
def allow_request(self):
with self.lock:
self._leak()
if len(self.queue) < self.capacity:
self.queue.append(time.time())
return True
return False
def _leak(self):
now = time.time()
elapsed = now - self.last_leak
leak_count = int(elapsed * self.outflow_rate)
for _ in range(leak_count):
if self.queue:
self.queue.popleft()
self.last_leak = now3. Sliding Window Counter
Hybrid approach combining fixed and sliding window:
import time
from threading import Lock
class SlidingWindowCounter:
def __init__(self, window_size, max_requests):
"""
window_size: time window in seconds
max_requests: max requests allowed in window
"""
self.window_size = window_size
self.max_requests = max_requests
self.counters = {} # {window_start: count}
self.lock = Lock()
def allow_request(self, identifier):
with self.lock:
now = time.time()
window_start = int(now / self.window_size) * self.window_size
# Remove old windows
for key in list(self.counters.keys()):
if key < window_start - self.window_size:
del self.counters[key]
# Check current window
key = f"{identifier}:{window_start}"
if key not in self.counters:
self.counters[key] = 0
if self.counters[key] < self.max_requests:
self.counters[key] += 1
return True
return False17.2 Distributed Rate Limiting
For multi-server deployments, use Redis:
import redis
import time
class DistributedRateLimiter:
def __init__(self, redis_client, key_prefix="rate_limit"):
self.redis = redis_client
self.key_prefix = key_prefix
def allow_request(self, identifier, limit, window):
"""
identifier: user_id or IP
limit: max requests
window: time window in seconds
"""
key = f"{self.key_prefix}:{identifier}"
now = time.time()
window_start = now - window
# Remove old entries
self.redis.zremrangebyscore(key, 0, window_start)
# Count requests in current window
count = self.redis.zcard(key)
if count < limit:
# Add current request
self.redis.zadd(key, {str(now): now})
# Set expiration
self.redis.expire(key, window + 1)
return True
return False
# Usage
redis_client = redis.Redis(host='localhost', port=6379)
limiter = DistributedRateLimiter(redis_client)
for i in range(5):
if limiter.allow_request('user:123', limit=3, window=60):
print(f"Request {i+1}: Allowed")
else:
print(f"Request {i+1}: Rate limited")18. Consistent Hashing
18.1 Problem Statement
Standard hashing breaks when servers are added/removed:
# Standard hashing - doesn't work well with dynamic servers
def standard_hash(key, num_servers):
return hash(key) % num_serversWhen you add/remove a server, most keys rehash to different locations!
18.2 Consistent Hashing Solution
Maps both keys and servers onto a circle:
import hashlib
from bisect import bisect_right
class ConsistentHashing:
def __init__(self, num_virtual_nodes=150):
self.num_virtual_nodes = num_virtual_nodes
self.ring = {} # hash -> server_id
self.sorted_hashes = []
self.servers = set()
def _hash(self, key):
"""Hash function"""
return int(hashlib.md5(str(key).encode()).hexdigest(), 16)
def add_server(self, server_id):
"""Add server to ring"""
self.servers.add(server_id)
for i in range(self.num_virtual_nodes):
virtual_key = f"{server_id}:{i}"
hash_value = self._hash(virtual_key)
self.ring[hash_value] = server_id
self.sorted_hashes.append(hash_value)
self.sorted_hashes.sort()
def remove_server(self, server_id):
"""Remove server from ring"""
self.servers.discard(server_id)
hashes_to_remove = []
for i in range(self.num_virtual_nodes):
virtual_key = f"{server_id}:{i}"
hash_value = self._hash(virtual_key)
hashes_to_remove.append(hash_value)
del self.ring[hash_value]
for h in hashes_to_remove:
self.sorted_hashes.remove(h)
def get_server(self, key):
"""Get server for key"""
if not self.servers:
return None
hash_value = self._hash(key)
# Find the first server hash >= key hash
idx = bisect_right(self.sorted_hashes, hash_value)
if idx == len(self.sorted_hashes):
idx = 0
server_hash = self.sorted_hashes[idx]
return self.ring[server_hash]
# Usage
ch = ConsistentHashing()
ch.add_server("server:1")
ch.add_server("server:2")
ch.add_server("server:3")
# Map keys to servers
for key in ["user:1", "user:2", "user:3", "user:4", "user:5"]:
server = ch.get_server(key)
print(f"{key} -> {server}")
# Add new server - only some keys rehash
print("\nAdding server:4...")
ch.add_server("server:4")
for key in ["user:1", "user:2", "user:3", "user:4", "user:5"]:
server = ch.get_server(key)
print(f"{key} -> {server}")Benefits:
- Adding/removing server affects only 1/N of keys
- Virtual nodes ensure better distribution
- Works well for cache distribution
27. Design a URL Shortener
27.1 Requirements
Functional:
- Shorten long URLs
- Redirect short URL to long URL
- Custom short URLs (optional)
Non-Functional:
- High availability
- Low latency
- Shortened URL unique and not guessable
27.2 Architecture

27.3 Implementation
import string
import random
from datetime import datetime
class URLShortener:
def __init__(self, base_url="http://short.url", cache=None, db=None):
self.base_url = base_url
self.cache = cache or {}
self.db = db or {}
self.characters = string.ascii_letters + string.digits
def _generate_short_code(self, length=6):
"""Generate random short code"""
return ''.join(random.choice(self.characters) for _ in range(length))
def shorten(self, long_url, custom_code=None):
"""Create shortened URL"""
short_code = custom_code or self._generate_short_code()
# Check if custom code exists
if short_code in self.db:
return None # Already exists
url_record = {
'long_url': long_url,
'short_code': short_code,
'created_at': datetime.now(),
'expires_at': None,
'click_count': 0
}
# Store in database
self.db[short_code] = url_record
# Cache it
self.cache[short_code] = long_url
return f"{self.base_url}/{short_code}"
def expand(self, short_code):
"""Get original URL"""
# Check cache first
if short_code in self.cache:
return self.cache[short_code]
# Check database
if short_code in self.db:
long_url = self.db[short_code]['long_url']
# Update cache
self.cache[short_code] = long_url
# Increment click count
self.db[short_code]['click_count'] += 1
return long_url
return None
def get_stats(self, short_code):
"""Get URL statistics"""
if short_code not in self.db:
return None
record = self.db[short_code]
return {
'short_code': short_code,
'long_url': record['long_url'],
'created_at': record['created_at'],
'click_count': record['click_count']
}
# Usage
shortener = URLShortener()
# Create shortened URL
short = shortener.shorten("https://www.example.com/very/long/url/path")
print(f"Shortened: {short}")
# Expand shortened URL
long = shortener.expand(short.split('/')[-1])
print(f"Expanded: {long}")
# Get statistics
code = short.split('/')[-1]
stats = shortener.get_stats(code)
print(f"Stats: {stats}")30. Design an Object Storage System (S3)
30.1 High-Level Design
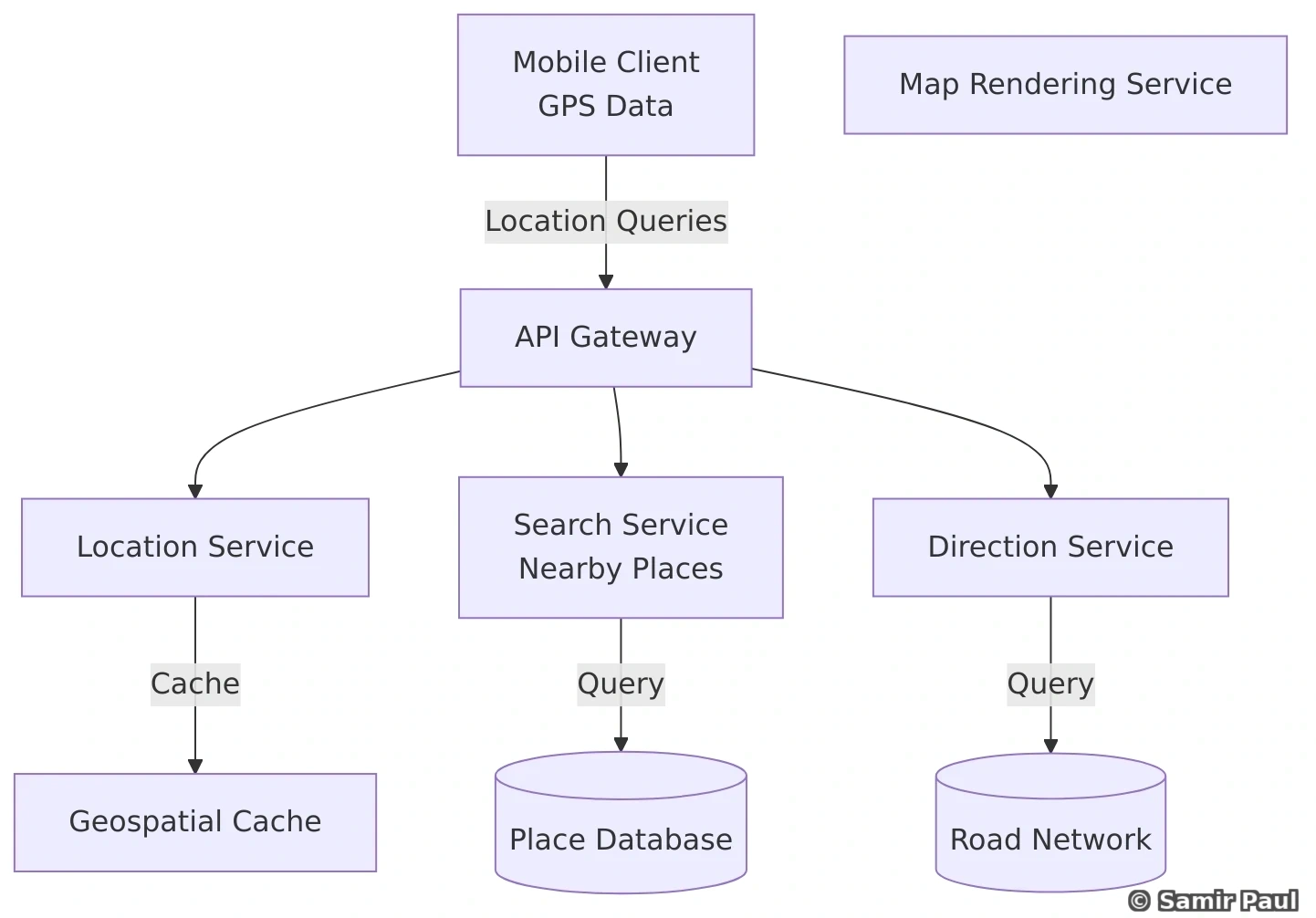
30.2 Implementation Concepts
from dataclasses import dataclass
from datetime import datetime
import hashlib
import os
@dataclass
class ObjectMetadata:
bucket: str
key: str
size: int
content_type: str
etag: str # hash for integrity
created_at: datetime
replicas: list # list of storage nodes with copies
class S3LikeStorage:
def __init__(self, storage_nodes=3):
self.metadata = {} # bucket/key -> metadata
self.storage_nodes = [f"node_{i}" for i in range(storage_nodes)]
self.object_store = {} # actual data storage
def put_object(self, bucket, key, data, content_type="binary"):
"""Upload object"""
# Calculate hash
etag = hashlib.md5(data).hexdigest()
# Store metadata
metadata = ObjectMetadata(
bucket=bucket,
key=key,
size=len(data),
content_type=content_type,
etag=etag,
created_at=datetime.now(),
replicas=self.storage_nodes.copy()
)
full_key = f"{bucket}/{key}"
self.metadata[full_key] = metadata
self.object_store[full_key] = data
# Replicate to other nodes
self._replicate(full_key, data)
return etag
def get_object(self, bucket, key):
"""Download object"""
full_key = f"{bucket}/{key}"
if full_key not in self.object_store:
return None
return self.object_store[full_key]
def delete_object(self, bucket, key):
"""Delete object"""
full_key = f"{bucket}/{key}"
if full_key in self.metadata:
del self.metadata[full_key]
if full_key in self.object_store:
del self.object_store[full_key]
return True
def list_objects(self, bucket, prefix=""):
"""List objects in bucket"""
objects = []
for key in self.object_store:
if key.startswith(f"{bucket}/"):
obj_key = key.replace(f"{bucket}/", "")
if obj_key.startswith(prefix):
objects.append(obj_key)
return objects
def _replicate(self, key, data):
"""Replicate data to storage nodes"""
for node in self.storage_nodes:
# In real system: write to remote storage node
pass
# Usage
s3 = S3LikeStorage()
# Upload
etag = s3.put_object("my-bucket", "file.txt", b"Hello World")
print(f"Uploaded with ETag: {etag}")
# Download
data = s3.get_object("my-bucket", "file.txt")
print(f"Downloaded: {data}")
# List
objects = s3.list_objects("my-bucket")
print(f"Objects: {objects}")31. Design YouTube / Video Streaming Platform
31.1 Architecture Overview
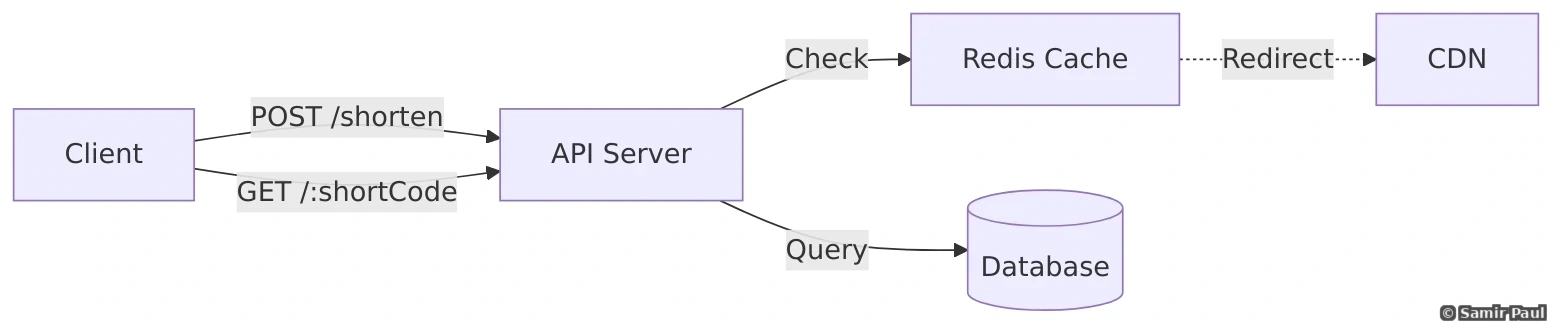
31.2 Video Processing Pipeline
from enum import Enum
class VideoQuality(Enum):
LOW = "360p"
MEDIUM = "480p"
HIGH = "720p"
HD = "1080p"
FULL_HD = "4K"
class VideoProcessingService:
def __init__(self):
self.processing_queue = []
self.storage = {}
def upload_video(self, user_id, video_file):
"""Handle video upload"""
video_id = self._generate_id()
# Store raw video
raw_path = f"raw/{video_id}/{video_file.name}"
self.storage[raw_path] = video_file
# Queue for processing
job = {
'video_id': video_id,
'user_id': user_id,
'raw_path': raw_path,
'status': 'queued'
}
self.processing_queue.append(job)
return video_id
def process_video(self, job):
"""Process video: transcode to multiple qualities"""
video_id = job['video_id']
raw_path = job['raw_path']
# Transcode to different qualities
qualities = [VideoQuality.LOW, VideoQuality.MEDIUM,
VideoQuality.HIGH, VideoQuality.HD]
processed_paths = []
for quality in qualities:
output_path = f"processed/{video_id}/{quality.value}.mp4"
self._transcode(raw_path, output_path, quality)
processed_paths.append(output_path)
# Generate thumbnail
thumbnail_path = f"thumbnails/{video_id}/thumb.jpg"
self._generate_thumbnail(raw_path, thumbnail_path)
# Update metadata
self._update_metadata(video_id, {
'processed_paths': processed_paths,
'thumbnail': thumbnail_path,
'status': 'ready'
})
return processed_paths
def _transcode(self, input_path, output_path, quality):
"""Transcode video to specified quality"""
# Simplified - real implementation uses FFmpeg
print(f"Transcoding {input_path} to {quality.value}")
self.storage[output_path] = f"transcoded_{quality.value}"
def _generate_thumbnail(self, video_path, output_path):
"""Extract thumbnail from video"""
print(f"Generating thumbnail for {video_path}")
self.storage[output_path] = "thumbnail_data"
def _generate_id(self):
import uuid
return str(uuid.uuid4())
def _update_metadata(self, video_id, metadata):
"""Update video metadata"""
print(f"Updating metadata for {video_id}: {metadata}")32. Design a Chat System
32.1 Architecture
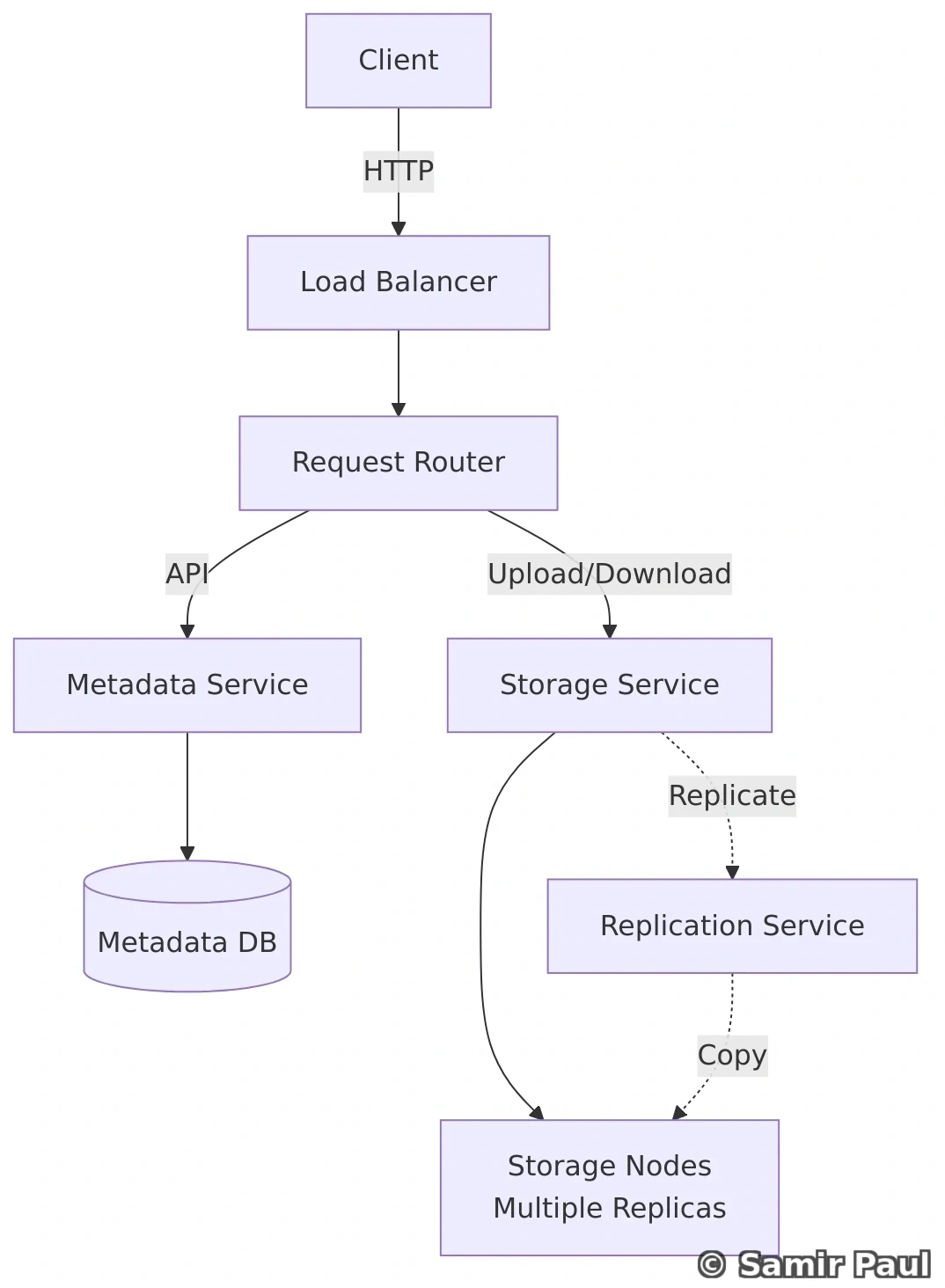
32.2 Implementation
import json
from datetime import datetime
from collections import defaultdict
class ChatSystem:
def __init__(self):
self.connections = {} # user_id -> websocket
self.messages = [] # message history
self.online_users = set()
self.typing_status = defaultdict(set) # chat_id -> set of typing users
def connect_user(self, user_id, websocket):
"""User connects to chat"""
self.connections[user_id] = websocket
self.online_users.add(user_id)
# Notify others user is online
self._broadcast_presence(user_id, 'online')
return True
def disconnect_user(self, user_id):
"""User disconnects"""
if user_id in self.connections:
del self.connections[user_id]
self.online_users.discard(user_id)
# Notify others user is offline
self._broadcast_presence(user_id, 'offline')
def send_message(self, from_user, to_user, content):
"""Send message from one user to another"""
message = {
'id': len(self.messages) + 1,
'from': from_user,
'to': to_user,
'content': content,
'timestamp': datetime.now().isoformat(),
'read': False
}
# Store message
self.messages.append(message)
# Deliver if recipient online
if to_user in self.connections:
self._deliver_message(to_user, message)
return message['id']
def send_group_message(self, from_user, group_id, content):
"""Send message to group"""
message = {
'id': len(self.messages) + 1,
'from': from_user,
'group_id': group_id,
'content': content,
'timestamp': datetime.now().isoformat()
}
self.messages.append(message)
# Deliver to all group members
group_members = self._get_group_members(group_id)
for member in group_members:
if member != from_user and member in self.connections:
self._deliver_message(member, message)
return message['id']
def mark_typing(self, user_id, chat_id, is_typing):
"""Update typing status"""
if is_typing:
self.typing_status[chat_id].add(user_id)
else:
self.typing_status[chat_id].discard(user_id)
# Notify other participants
self._broadcast_typing(chat_id, user_id, is_typing)
def get_message_history(self, user_id, other_user_id, limit=50):
"""Get chat history between two users"""
history = []
for msg in reversed(self.messages):
if ((msg.get('from') == user_id and msg.get('to') == other_user_id) or
(msg.get('from') == other_user_id and msg.get('to') == user_id)):
history.append(msg)
if len(history) >= limit:
break
return list(reversed(history))
def _deliver_message(self, user_id, message):
"""Deliver message via WebSocket"""
if user_id in self.connections:
websocket = self.connections[user_id]
# In real system: websocket.send(json.dumps(message))
print(f"Delivered to {user_id}: {message}")
def _broadcast_presence(self, user_id, status):
"""Notify all users about presence change"""
for uid, ws in self.connections.items():
if uid != user_id:
# Send presence notification
print(f"User {user_id} is {status}")
def _broadcast_typing(self, chat_id, user_id, is_typing):
"""Notify typing status"""
pass
def _get_group_members(self, group_id):
"""Get members of a group"""
# Simplified - would query database
return []
# Usage
chat = ChatSystem()
# Users connect
chat.connect_user('alice', 'websocket_alice')
chat.connect_user('bob', 'websocket_bob')
# Send message
msg_id = chat.send_message('alice', 'bob', 'Hello Bob!')
# Get history
history = chat.get_message_history('alice', 'bob')
print(f"Message history: {history}")33. Design a News Feed System
33.1 Architecture
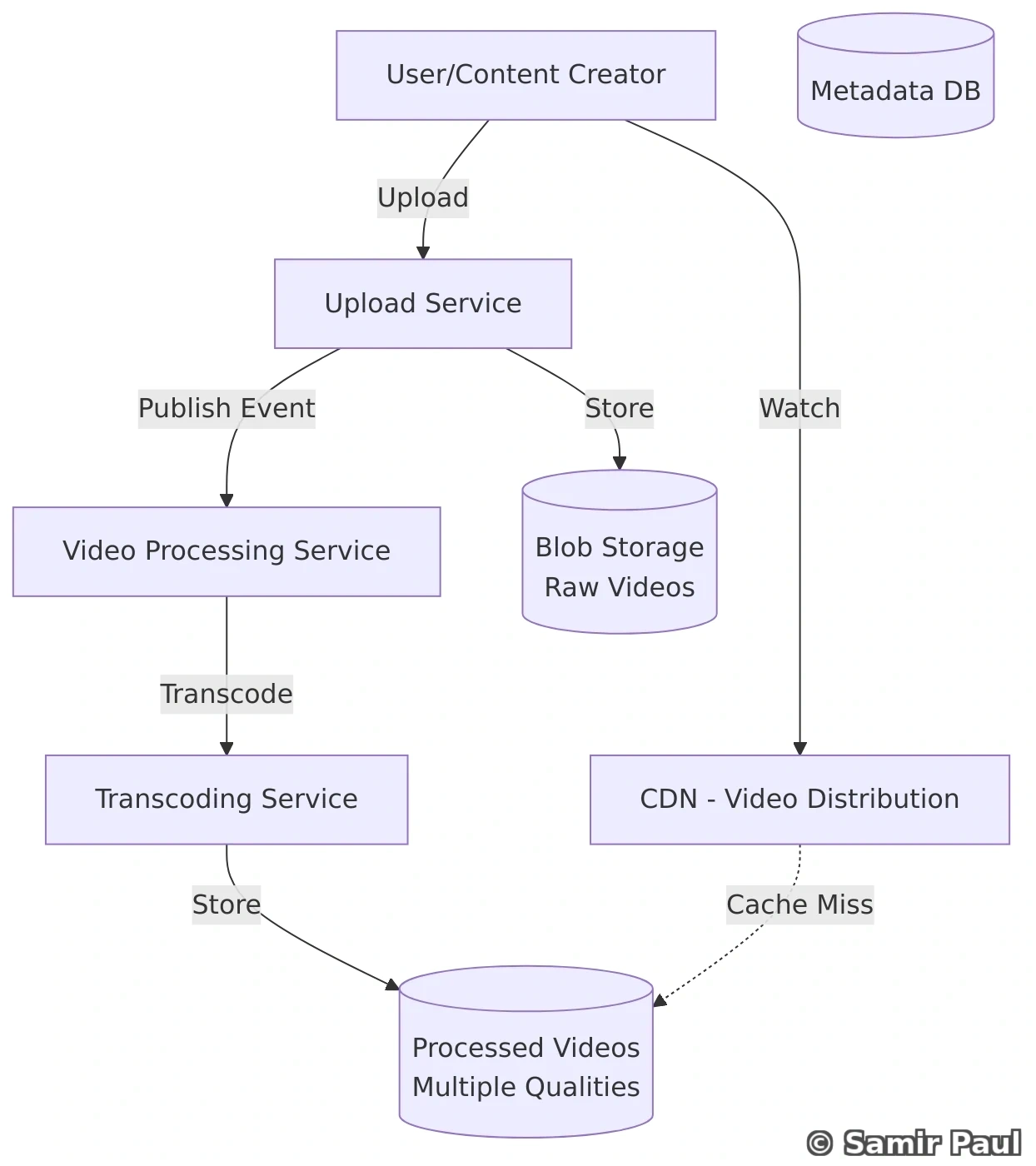
33.2 Feed Generation Strategies
Fan-out on Write (Push Model):
class FanoutOnWrite:
def __init__(self):
self.feeds = {} # user_id -> list of post_ids
self.posts = {} # post_id -> post data
self.followers = {} # user_id -> list of follower_ids
def create_post(self, user_id, content):
"""User creates a post"""
post_id = len(self.posts) + 1
post = {
'id': post_id,
'user_id': user_id,
'content': content,
'created_at': datetime.now()
}
self.posts[post_id] = post
# Fan-out: push to all followers' feeds
followers = self.followers.get(user_id, [])
for follower_id in followers:
if follower_id not in self.feeds:
self.feeds[follower_id] = []
self.feeds[follower_id].insert(0, post_id) # Add to front
return post_id
def get_feed(self, user_id, limit=10):
"""Get user's news feed"""
post_ids = self.feeds.get(user_id, [])[:limit]
return [self.posts[pid] for pid in post_ids]Fan-out on Read (Pull Model):
class FanoutOnRead:
def __init__(self):
self.posts = {} # user_id -> list of posts
self.following = {} # user_id -> list of followed user_ids
def create_post(self, user_id, content):
"""User creates a post"""
post_id = len(sum(self.posts.values(), [])) + 1
post = {
'id': post_id,
'user_id': user_id,
'content': content,
'created_at': datetime.now()
}
if user_id not in self.posts:
self.posts[user_id] = []
self.posts[user_id].insert(0, post)
return post_id
def get_feed(self, user_id, limit=10):
"""Aggregate feed on-the-fly"""
followed_users = self.following.get(user_id, [])
# Collect posts from all followed users
all_posts = []
for followed_id in followed_users:
all_posts.extend(self.posts.get(followed_id, []))
# Sort by timestamp and return top posts
all_posts.sort(key=lambda p: p['created_at'], reverse=True)
return all_posts[:limit]Hybrid Approach:
class HybridFeedService:
def __init__(self):
self.fanout_write = FanoutOnWrite()
self.fanout_read = FanoutOnRead()
self.celebrity_threshold = 10000 # Users with >10K followers
def create_post(self, user_id, content):
"""Smart fan-out based on user popularity"""
follower_count = len(self.fanout_write.followers.get(user_id, []))
if follower_count > self.celebrity_threshold:
# Celebrity: use pull model
return self.fanout_read.create_post(user_id, content)
else:
# Regular user: use push model
return self.fanout_write.create_post(user_id, content)
def get_feed(self, user_id, limit=10):
"""Get personalized feed"""
# Mix pre-computed and real-time feeds
precomputed = self.fanout_write.get_feed(user_id, limit // 2)
realtime = self.fanout_read.get_feed(user_id, limit // 2)
# Merge and sort
combined = precomputed + realtime
combined.sort(key=lambda p: p['created_at'], reverse=True)
return combined[:limit]34. Design a Search Autocomplete System
34.1 Trie-Based Implementation
class TrieNode:
def __init__(self):
self.children = {}
self.is_end = False
self.frequency = 0
self.suggestions = [] # Top suggestions from this node
class AutocompleteSystem:
def __init__(self):
self.root = TrieNode()
def add_query(self, query, frequency=1):
"""Add search query to trie"""
node = self.root
for char in query.lower():
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end = True
node.frequency += frequency
def search(self, prefix, limit=5):
"""Get autocomplete suggestions"""
node = self.root
# Navigate to prefix
for char in prefix.lower():
if char not in node.children:
return []
node = node.children[char]
# Collect all completions
suggestions = []
self._collect_suggestions(node, prefix, suggestions)
# Sort by frequency and return top results
suggestions.sort(key=lambda x: x[1], reverse=True)
return [s[0] for s in suggestions[:limit]]
def _collect_suggestions(self, node, prefix, suggestions):
"""DFS to collect all completions"""
if node.is_end:
suggestions.append((prefix, node.frequency))
for char, child_node in node.children.items():
self._collect_suggestions(child_node, prefix + char, suggestions)
# Usage
autocomplete = AutocompleteSystem()
# Add popular queries
queries = [
("system design", 1000),
("system design interview", 800),
("system design patterns", 600),
("system architecture", 500),
("distributed systems", 900)
]
for query, freq in queries:
autocomplete.add_query(query, freq)
# Search
results = autocomplete.search("sys")
print(f"Suggestions for 'sys': {results}")35. Design a Notification System
35.1 Multi-Channel Notification System
from abc import ABC, abstractmethod
from enum import Enum
class NotificationType(Enum):
EMAIL = "email"
SMS = "sms"
PUSH = "push"
IN_APP = "in_app"
class NotificationChannel(ABC):
@abstractmethod
def send(self, recipient, message):
pass
class EmailChannel(NotificationChannel):
def send(self, recipient, message):
print(f"Sending email to {recipient}: {message}")
# Implementation: SMTP, SendGrid, etc.
class SMSChannel(NotificationChannel):
def send(self, recipient, message):
print(f"Sending SMS to {recipient}: {message}")
# Implementation: Twilio, AWS SNS, etc.
class PushChannel(NotificationChannel):
def send(self, recipient, message):
print(f"Sending push to {recipient}: {message}")
# Implementation: FCM, APNS, etc.
class InAppChannel(NotificationChannel):
def send(self, recipient, message):
print(f"Sending in-app notification to {recipient}: {message}")
# Implementation: WebSocket, polling, etc.
class NotificationService:
def __init__(self):
self.channels = {
NotificationType.EMAIL: EmailChannel(),
NotificationType.SMS: SMSChannel(),
NotificationType.PUSH: PushChannel(),
NotificationType.IN_APP: InAppChannel()
}
self.user_preferences = {} # user_id -> list of enabled channels
self.notification_queue = []
def send_notification(self, user_id, message, channels=None):
"""Send notification via specified channels"""
if channels is None:
channels = self.user_preferences.get(user_id,
[NotificationType.PUSH, NotificationType.IN_APP])
for channel_type in channels:
if channel_type in self.channels:
channel = self.channels[channel_type]
# Add to queue for async processing
self.notification_queue.append({
'user_id': user_id,
'channel': channel,
'message': message
})
def process_queue(self):
"""Process notification queue"""
while self.notification_queue:
notif = self.notification_queue.pop(0)
try:
notif['channel'].send(notif['user_id'], notif['message'])
except Exception as e:
print(f"Failed to send notification: {e}")
# Retry logic here
# Usage
notification_service = NotificationService()
# Send multi-channel notification
notification_service.send_notification(
user_id='user123',
message='Your order has shipped!',
channels=[NotificationType.EMAIL, NotificationType.PUSH]
)21. Common Design Patterns in System Design
21.1 Creational Patterns
Singleton Pattern
Ensures only one instance of a class:
class Database:
_instance = None
_lock = __import__('threading').Lock()
def __new__(cls):
if cls._instance is None:
with cls._lock:
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._initialized = False
return cls._instance
def __init__(self):
if self._initialized:
return
self.connection = self._create_connection()
self._initialized = True
def _create_connection(self):
print("Creating database connection")
return "connection_object"
# Usage
db1 = Database()
db2 = Database()
print(db1 is db2) # True - same instanceFactory Pattern
Create objects without specifying exact classes:
from abc import ABC, abstractmethod
class Cache(ABC):
@abstractmethod
def get(self, key): pass
@abstractmethod
def set(self, key, value): pass
class RedisCache(Cache):
def get(self, key):
return f"Redis get {key}"
def set(self, key, value):
print(f"Redis set {key}={value}")
class MemcachedCache(Cache):
def get(self, key):
return f"Memcached get {key}"
def set(self, key, value):
print(f"Memcached set {key}={value}")
class CacheFactory:
@staticmethod
def create_cache(cache_type):
if cache_type == "redis":
return RedisCache()
elif cache_type == "memcached":
return MemcachedCache()
raise ValueError(f"Unknown cache type: {cache_type}")
# Usage
cache = CacheFactory.create_cache("redis")
cache.set("key", "value")Builder Pattern
Construct complex objects step by step:
class QueryBuilder:
def __init__(self):
self.select_fields = []
self.from_table = None
self.where_clause = None
self.order_by = None
self.limit_count = None
def select(self, *fields):
self.select_fields = list(fields)
return self
def from_table(self, table):
self.from_table = table
return self
def where(self, condition):
self.where_clause = condition
return self
def order_by(self, field, direction="ASC"):
self.order_by = f"{field} {direction}"
return self
def limit(self, count):
self.limit_count = count
return self
def build(self):
query = f"SELECT {','.join(self.select_fields)} FROM {self.from_table}"
if self.where_clause:
query += f" WHERE {self.where_clause}"
if self.order_by:
query += f" ORDER BY {self.order_by}"
if self.limit_count:
query += f" LIMIT {self.limit_count}"
return query
# Usage
query = (QueryBuilder()
.select("id", "name", "email")
.from_table("users")
.where("age > 18")
.order_by("name")
.limit(10)
.build())
print(query)21.2 Structural Patterns
Adapter Pattern
Convert one interface to another:
class LegacyPaymentSystem:
def make_payment(self, amount):
return f"Legacy system processed ${amount}"
class ModernPaymentInterface:
def charge(self, amount):
pass
class PaymentAdapter(ModernPaymentInterface):
def __init__(self, legacy_system):
self.legacy = legacy_system
def charge(self, amount):
return self.legacy.make_payment(amount)
# Usage
legacy = LegacyPaymentSystem()
adapter = PaymentAdapter(legacy)
result = adapter.charge(100)
print(result)Decorator Pattern
Add functionality to objects dynamically:
class Coffee:
def cost(self):
return 5.0
def description(self):
return "Coffee"
class CoffeeDecorator(Coffee):
def __init__(self, coffee):
self.coffee = coffee
class Milk(CoffeeDecorator):
def cost(self):
return self.coffee.cost() + 1.0
def description(self):
return self.coffee.description() + ", Milk"
class Espresso(CoffeeDecorator):
def cost(self):
return self.coffee.cost() + 2.0
def description(self):
return self.coffee.description() + ", Espresso"
# Usage
coffee = Coffee()
coffee = Milk(coffee)
coffee = Espresso(coffee)
print(f"{coffee.description()}: ${coffee.cost()}")
# Coffee, Milk, Espresso: $8.0Facade Pattern
Provide simplified interface to complex subsystem:
class VideoEncoder:
def encode(self, video):
return f"Encoded {video}"
class AudioProcessor:
def process(self, audio):
return f"Processed {audio}"
class Subtitles:
def generate(self, video):
return f"Generated subtitles for {video}"
class VideoConversionFacade:
def __init__(self):
self.encoder = VideoEncoder()
self.audio = AudioProcessor()
self.subtitles = Subtitles()
def convert_video(self, video_file):
"""Single method to convert video with all options"""
encoded = self.encoder.encode(video_file)
processed_audio = self.audio.process(video_file)
subs = self.subtitles.generate(video_file)
return f"Converted: {encoded}, {processed_audio}, {subs}"
# Usage
converter = VideoConversionFacade()
result = converter.convert_video("movie.mp4")
print(result)21.3 Behavioral Patterns
Observer Pattern
Objects notify observers of state changes:
from abc import ABC, abstractmethod
class Observer(ABC):
@abstractmethod
def update(self, event):
pass
class EventEmitter:
def __init__(self):
self.observers = []
def subscribe(self, observer):
self.observers.append(observer)
def unsubscribe(self, observer):
self.observers.remove(observer)
def emit(self, event):
for observer in self.observers:
observer.update(event)
class EmailNotifier(Observer):
def update(self, event):
print(f"Sending email: {event}")
class LogNotifier(Observer):
def update(self, event):
print(f"Logging: {event}")
# Usage
emitter = EventEmitter()
emitter.subscribe(EmailNotifier())
emitter.subscribe(LogNotifier())
emitter.emit("User registered")Strategy Pattern
Select algorithm at runtime:
from abc import ABC, abstractmethod
class PaymentStrategy(ABC):
@abstractmethod
def pay(self, amount):
pass
class CreditCardPayment(PaymentStrategy):
def pay(self, amount):
return f"Paid ${amount} with credit card"
class PayPalPayment(PaymentStrategy):
def pay(self, amount):
return f"Paid ${amount} with PayPal"
class CryptoCurrency(PaymentStrategy):
def pay(self, amount):
return f"Paid ${amount} with cryptocurrency"
class ShoppingCart:
def __init__(self, payment_strategy):
self.strategy = payment_strategy
def checkout(self, amount):
return self.strategy.pay(amount)
# Usage
cart = ShoppingCart(CreditCardPayment())
print(cart.checkout(100))
cart.strategy = PayPalPayment()
print(cart.checkout(50))State Pattern
Alter behavior when state changes:
from abc import ABC, abstractmethod
class State(ABC):
@abstractmethod
def process(self, order):
pass
class PendingState(State):
def process(self, order):
print("Order is pending")
order.state = ProcessingState()
class ProcessingState(State):
def process(self, order):
print("Order is being processed")
order.state = ShippedState()
class ShippedState(State):
def process(self, order):
print("Order has shipped")
order.state = DeliveredState()
class DeliveredState(State):
def process(self, order):
print("Order delivered")
class Order:
def __init__(self):
self.state = PendingState()
def process(self):
self.state.process(self)
# Usage
order = Order()
order.process() # Pending
order.process() # Processing
order.process() # Shipped
order.process() # Delivered41. Netflix Architecture
41.1 High-Level Overview
Netflix serves over 200 million subscribers streaming billions of hours monthly.
Key Components:
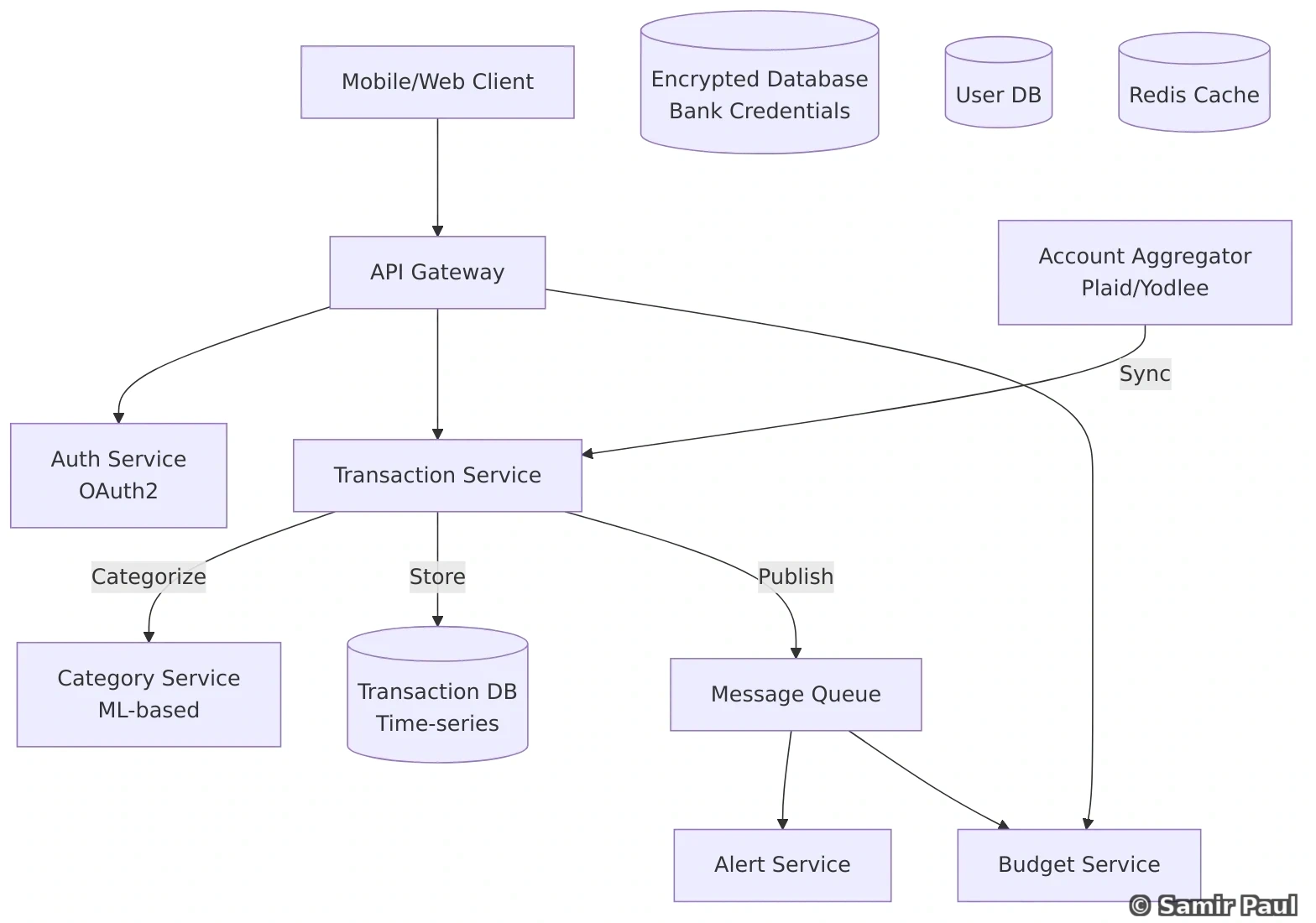
Architecture Principles:
- Microservices (500+ services)
- Chaos Engineering (Chaos Monkey)
- Global CDN (Open Connect)
- Personalized recommendations using ML
- Multi-region active-active setup
41.2 Video Streaming Pipeline
class NetflixStreamingArchitecture:
"""Simplified Netflix streaming architecture"""
def __init__(self):
self.video_qualities = ['240p', '480p', '720p', '1080p', '4K']
self.cdn_locations = []
self.user_bandwidth_data = {}
def select_video_quality(self, user_id):
"""Adaptive bitrate streaming"""
bandwidth = self.user_bandwidth_data.get(user_id, 5.0) # Mbps
if bandwidth >= 25:
return '4K'
elif bandwidth >= 5:
return '1080p'
elif bandwidth >= 3:
return '720p'
elif bandwidth >= 1.5:
return '480p'
else:
return '240p'
def get_nearest_cdn(self, user_location):
"""Find closest CDN server"""
# Geographic routing
min_distance = float('inf')
nearest_cdn = None
for cdn in self.cdn_locations:
distance = self.calculate_distance(user_location, cdn.location)
if distance < min_distance:
min_distance = distance
nearest_cdn = cdn
return nearest_cdnKey Learnings:
- Use CDN for global content delivery
- Adaptive streaming based on network conditions
- Pre-positioning content close to users
- Chaos engineering for resilience testing
42. Uber Tech Stack
42.1 Dispatch System
Core of Uber’s platform matching riders with drivers:
import heapq
from dataclasses import dataclass
from typing import Tuple
@dataclass
class Driver:
id: str
location: Tuple[float, float] # (lat, lon)
available: bool
@dataclass
class RideRequest:
rider_id: str
pickup_location: Tuple[float, float]
dropoff_location: Tuple[float, float]
class UberDispatchSystem:
def __init__(self):
self.available_drivers = [] # Available drivers
self.pending_requests = [] # Ride requests queue
def add_driver(self, driver):
"""Add driver to available pool"""
if driver.available:
self.available_drivers.append(driver)
def request_ride(self, request):
"""Find nearest available driver"""
if not self.available_drivers:
return None
# Find k nearest drivers
nearest_drivers = self._find_nearest_drivers(
request.pickup_location,
k=5
)
if not nearest_drivers:
return None
# Assign to nearest available driver
driver = nearest_drivers[0]
driver.available = False
self.available_drivers.remove(driver)
return {
'driver_id': driver.id,
'driver_location': driver.location,
'eta': self._calculate_eta(driver.location, request.pickup_location)
}
def _find_nearest_drivers(self, location, k=5):
"""Find k nearest available drivers"""
distances = []
for driver in self.available_drivers:
dist = self._haversine_distance(location, driver.location)
distances.append((dist, driver))
# Sort by distance and return top k
distances.sort(key=lambda x: x[0])
return [driver for _, driver in distances[:k]]
def _haversine_distance(self, loc1, loc2):
"""Calculate distance between two points"""
import math
lat1, lon1 = loc1
lat2, lon2 = loc2
R = 6371 # Earth radius in km
dlat = math.radians(lat2 - lat1)
dlon = math.radians(lon2 - lon1)
a = (math.sin(dlat/2)**2 +
math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) *
math.sin(dlon/2)**2)
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
return R * c
def _calculate_eta(self, from_loc, to_loc):
"""Estimate time to arrival"""
distance = self._haversine_distance(from_loc, to_loc)
avg_speed = 40 # km/h in city
return distance / avg_speed * 60 # minutesKey Technologies:
- Microservices architecture
- Cassandra for trip data
- Redis for real-time driver locations
- Apache Kafka for event streaming
- Geospatial indexing for driver matching
43. How Discord Stores Trillions of Messages
43.1 Data Model Evolution
Discord evolved from MongoDB to Cassandra to handle scale:
# Cassandra schema for messages
class DiscordMessageStorage:
"""
Cassandra table design:
CREATE TABLE messages (
channel_id bigint,
message_id bigint,
author_id bigint,
content text,
timestamp timestamp,
PRIMARY KEY ((channel_id), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
"""
def __init__(self):
self.message_buckets = {} # Simplified storage
def store_message(self, channel_id, message_id, author_id, content):
"""Store message"""
if channel_id not in self.message_buckets:
self.message_buckets[channel_id] = []
message = {
'message_id': message_id,
'author_id': author_id,
'content': content,
'timestamp': __import__('time').time()
}
# Insert at beginning (newest first)
self.message_buckets[channel_id].insert(0, message)
def get_recent_messages(self, channel_id, limit=50):
"""Get most recent messages"""
if channel_id not in self.message_buckets:
return []
return self.message_buckets[channel_id][:limit]
def get_messages_before(self, channel_id, before_id, limit=50):
"""Get messages before a message_id (pagination)"""
if channel_id not in self.message_buckets:
return []
messages = self.message_buckets[channel_id]
# Find messages before the given message_id
result = []
for msg in messages:
if msg['message_id'] < before_id:
result.append(msg)
if len(result) >= limit:
break
return resultKey Learnings:
- Use partition key = channel_id for efficient queries
- Clustering key = message_id for sorting
- Hot partition problem solved with proper sharding
- Cassandra chosen for write-heavy workload
44. How Kafka Achieves High Throughput
44.1 Architecture Principles
class KafkaOptimizations:
"""
Key optimizations that make Kafka fast:
"""
def sequential_io(self):
"""
1. Sequential I/O
- Kafka writes to disk sequentially
- Much faster than random I/O
- Modern disks: sequential writes = memory writes
"""
pass
def zero_copy(self):
"""
2. Zero-Copy Technology
- Data transferred directly from file to socket
- No copying to application memory
- Uses sendfile() system call
"""
# Traditional: Disk -> Kernel -> User Space -> Kernel -> Socket
# Zero-copy: Disk -> Kernel -> Socket
pass
def batch_compression(self):
"""
3. Batch Compression
- Compress multiple messages together
- Better compression ratio
- Reduces network bandwidth
"""
messages = ["msg1", "msg2", "msg3"]
compressed_batch = self.compress(messages)
return compressed_batch
def page_cache(self):
"""
4. Page Cache
- Relies on OS page cache
- Recently written/read data cached in memory
- No need for application-level cache
"""
passPerformance Numbers:
- 2 million writes/second per server
- Hundreds of MB/s throughput
- Sub-millisecond latency
45. Instagram’s Scaling Journey
45.1 Feed Ranking Algorithm
class InstagramFeedRanking:
"""
Instagram's feed ranking considers multiple signals
"""
def __init__(self):
self.weights = {
'recency': 0.3,
'relationship': 0.25,
'engagement': 0.25,
'content_type': 0.2
}
def calculate_score(self, post, user):
"""Calculate post relevance score"""
# Recency score
time_decay = self._time_decay_score(post.created_at)
# Relationship score
relationship_score = self._relationship_strength(user, post.author)
# Engagement score
engagement_score = self._engagement_probability(post, user)
# Content type preference
content_score = self._content_type_score(post, user)
# Weighted sum
total_score = (
self.weights['recency'] * time_decay +
self.weights['relationship'] * relationship_score +
self.weights['engagement'] * engagement_score +
self.weights['content_type'] * content_score
)
return total_score
def _time_decay_score(self, created_at):
"""Recent posts score higher"""
import time
age_hours = (time.time() - created_at) / 3600
return 1.0 / (1.0 + age_hours)
def _relationship_strength(self, user, author):
"""How close is the user to the author"""
# Factors: follows, DMs, likes, comments
return 0.8 # Placeholder
def _engagement_probability(self, post, user):
"""Likelihood user will engage"""
# ML model predicts like/comment probability
return 0.7 # Placeholder
def _content_type_score(self, post, user):
"""User preference for content type"""
# Photo vs video vs carousel preference
return 0.6 # PlaceholderScaling Techniques:
- PostgreSQL with custom sharding
- Redis for feed caching
- Cassandra for user relationships
- memcached for general caching
- Horizontal scaling of web servers
Summary: System Design Principles
This guide covered comprehensive system design concepts from fundamentals to advanced distributed systems. Here are the key takeaways:
Core Principles
Start Simple, Then Scale
- Begin with single server
- Add components as needed
- Don’t over-engineer early
Know Your Numbers
- Latency estimates
- Capacity calculations
- Performance metrics
Trade-offs Are Everywhere
- Consistency vs Availability (CAP)
- Latency vs Throughput
- Cost vs Performance
Design for Failure
- Everything fails eventually
- Build redundancy
- Implement retry logic
Scalability Patterns
- Horizontal Scaling: Add more machines
- Vertical Scaling: Bigger machines
- Caching: Speed up reads
- CDN: Distribute static content
- Load Balancing: Distribute requests
- Database Sharding: Split data
- Async Processing: Use message queues
- Microservices: Decompose system
Key Technologies
| Component | Technologies |
|---|---|
| Web Servers | Nginx, Apache, Caddy |
| Load Balancers | HAProxy, Nginx, AWS ELB |
| Caching | Redis, Memcached |
| Databases | PostgreSQL, MySQL, MongoDB, Cassandra |
| Message Queues | Kafka, RabbitMQ, Amazon SQS |
| Search | Elasticsearch, Solr |
| Object Storage | Amazon S3, MinIO |
| CDN | CloudFlare, Akamai, CloudFront |
Interview Success Tips
Ask Clarifying Questions
- Don’t assume requirements
- Understand scale
- Identify constraints
Start with High-Level Design
- Draw major components
- Show data flow
- Get buy-in
Go Deep on 2-3 Components
- Don’t try to cover everything
- Show depth of knowledge
- Discuss trade-offs
Consider Edge Cases
- What if server fails?
- What if traffic spikes?
- How to monitor?
48. References and Further Reading
Books
Designing Data-Intensive Applications by Martin Kleppmann
- Comprehensive guide to distributed systems
- Deep dive into databases, replication, partitioning
System Design Interview Vol 1 & 2 by Alex Xu
- Practical system design problems
- Step-by-step solutions
Building Microservices by Sam Newman
- Microservices architecture patterns
- Real-world implementation strategies
Online Resources
Engineering Blogs:
- Netflix Tech Blog: https://netflixtechblog.com/
- Uber Engineering: https://eng.uber.com/
- Facebook Engineering: https://engineering.fb.com/
- Twitter Engineering: https://blog.twitter.com/engineering
- LinkedIn Engineering: https://engineering.linkedin.com/
- Airbnb Engineering: https://airbnb.io/
- Pinterest Engineering: https://medium.com/pinterest-engineering
- Instagram Engineering: https://instagram-engineering.com/
Learning Platforms:
- ByteByteGo: System design concepts and interview prep
- High Scalability: Architecture case studies
- InfoQ: Software architecture articles
- System Design Primer (GitHub): Comprehensive guide
Key Papers
Dynamo: Amazon’s Highly Available Key-value Store
- Eventual consistency principles
- Distributed hash tables
MapReduce: Simplified Data Processing
- Distributed computing framework
- Google’s approach to big data
Bigtable: A Distributed Storage System
- Wide-column store design
- Scalable structured data storage
Cassandra: A Decentralized Structured Storage System
- Distributed NoSQL database
- High availability design
Practice Platforms
- LeetCode System Design
- Educative.io System Design Course
- Grokking the System Design Interview
- Pramp (Mock interviews)
Communities
- r/SystemDesign (Reddit)
- System Design Interview Discord
- Tech Twitter (#SystemDesign)
- Stack Overflow
Final Note:
System design is a vast field that requires both theoretical knowledge and practical experience. This guide provides a solid foundation, but the best way to learn is through:
- Building real systems
- Reading engineering blogs
- Practicing interview questions
- Learning from failures
- Staying curious
Remember: There’s no single “correct” answer in system design. Focus on understanding trade-offs, justifying your decisions, and communicating clearly.
Good luck with your system design journey!
22. SOLID Principles
SOLID principles are five design principles that help make software more maintainable, flexible, and scalable.
22.1 Single Responsibility Principle (SRP)
Definition: A class should have only one reason to change.
Bad Example:
# Violates SRP - User class handles too much
class User:
def __init__(self, name, email):
self.name = name
self.email = email
def save_to_database(self):
# Database logic here
print(f"Saving {self.name} to database")
def send_email(self):
# Email logic here
print(f"Sending email to {self.email}")Good Example:
# Each class has ONE responsibility
class User:
def __init__(self, name, email):
self.name = name
self.email = email
class UserRepository:
def save(self, user):
print(f"Saving {user.name} to database")
class EmailService:
def send(self, user):
print(f"Sending email to {user.email}")
# Usage
user = User("Alice", "alice@example.com")
UserRepository().save(user)
EmailService().send(user)Why it matters:
- Easy to test each class
- Changes in database don’t affect email logic
- Clear separation of concerns
22.2 Open/Closed Principle (OCP)
Definition: Classes should be open for extension, closed for modification.
Bad Example:
# Violates OCP - must modify for new discounts
class Discount:
def calculate(self, customer_type, price):
if customer_type == "regular":
return price * 0.1
elif customer_type == "vip":
return price * 0.2
elif customer_type == "premium": # Need to modify!
return price * 0.3Good Example:
# Open for extension, closed for modification
class Discount:
def calculate(self, price):
return price * 0.1
class VIPDiscount(Discount):
def calculate(self, price):
return price * 0.2
class PremiumDiscount(Discount):
def calculate(self, price):
return price * 0.3
# Usage - no modification needed
def apply_discount(discount: Discount, price: float):
return price - discount.calculate(price)
print(apply_discount(VIPDiscount(), 100)) # 80
print(apply_discount(PremiumDiscount(), 100)) # 70Why it matters:
- Add new features without changing existing code
- Reduces risk of breaking existing functionality
- Easy to extend with new discount types
22.3 Liskov Substitution Principle (LSP)
Definition: Subclasses should be substitutable for their parent classes.
Bad Example:
# Violates LSP - Square changes Rectangle behavior
class Rectangle:
def __init__(self, width, height):
self.width = width
self.height = height
def set_width(self, width):
self.width = width
def set_height(self, height):
self.height = height
def area(self):
return self.width * self.height
class Square(Rectangle):
def set_width(self, width):
self.width = width
self.height = width # Changes both!
def set_height(self, height):
self.width = height # Changes both!
# Problem:
rect = Rectangle(5, 10)
rect.set_width(3)
print(rect.area()) # 30 ✓
square = Square(5, 5)
square.set_width(3)
print(square.area()) # 9 (unexpected if treated as Rectangle)Good Example:
# Correct - use composition instead
class Shape:
def area(self):
raise NotImplementedError
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
class Square(Shape):
def __init__(self, side):
self.side = side
def area(self):
return self.side * self.side
# Works correctly
shapes = [Rectangle(5, 10), Square(5)]
for shape in shapes:
print(shape.area()) # 50, 25Why it matters:
- Prevents unexpected behavior
- Code works correctly with any subclass
- Makes inheritance more reliable
22.4 Interface Segregation Principle (ISP)
Definition: Clients shouldn’t depend on methods they don’t use.
Bad Example:
# Violates ISP - forces unnecessary methods
class Worker:
def work(self):
raise NotImplementedError
def eat(self):
raise NotImplementedError
class Human(Worker):
def work(self):
print("Working")
def eat(self):
print("Eating lunch")
class Robot(Worker):
def work(self):
print("Working")
def eat(self):
pass # Robots don't eat! Forced to implementGood Example:
# Split into specific interfaces
class Workable:
def work(self):
raise NotImplementedError
class Eatable:
def eat(self):
raise NotImplementedError
class Human(Workable, Eatable):
def work(self):
print("Working")
def eat(self):
print("Eating lunch")
class Robot(Workable):
def work(self):
print("Working")
# No eat() method needed!Why it matters:
- Classes only implement what they need
- More flexible and maintainable
- Clear interface contracts
22.5 Dependency Inversion Principle (DIP)
Definition: Depend on abstractions, not concrete implementations.
Bad Example:
# Violates DIP - depends on concrete class
class MySQLDatabase:
def save(self, data):
print(f"Saving to MySQL: {data}")
class UserService:
def __init__(self):
self.db = MySQLDatabase() # Tightly coupled!
def create_user(self, user):
self.db.save(user)
# Problem: Can't easily switch to PostgreSQLGood Example:
# Depend on abstraction
from abc import ABC, abstractmethod
class Database(ABC):
@abstractmethod
def save(self, data):
pass
class MySQLDatabase(Database):
def save(self, data):
print(f"Saving to MySQL: {data}")
class PostgreSQLDatabase(Database):
def save(self, data):
print(f"Saving to PostgreSQL: {data}")
class UserService:
def __init__(self, database: Database):
self.db = database # Depends on abstraction
def create_user(self, user):
self.db.save(user)
# Easy to switch implementations
service1 = UserService(MySQLDatabase())
service2 = UserService(PostgreSQLDatabase())Why it matters:
- Easy to swap implementations
- Better for testing (can use mock database)
- Loose coupling between components
SOLID Principles Summary
| Principle | Key Idea | Benefit |
|---|---|---|
| SRP | One class, one job | Easy to maintain |
| OCP | Extend, don’t modify | Safe to add features |
| LSP | Subclass = Parent | Reliable inheritance |
| ISP | Small, focused interfaces | No unused methods |
| DIP | Depend on abstractions | Flexible architecture |
Real-World Application
# Complete example using all SOLID principles
from abc import ABC, abstractmethod
# DIP - Abstract payment interface
class PaymentProcessor(ABC):
@abstractmethod
def process(self, amount):
pass
# ISP - Separate interfaces
class Refundable(ABC):
@abstractmethod
def refund(self, amount):
pass
# OCP - Extensible payment types
class StripePayment(PaymentProcessor, Refundable):
def process(self, amount):
return f"Stripe processed ${amount}"
def refund(self, amount):
return f"Stripe refunded ${amount}"
class PayPalPayment(PaymentProcessor):
def process(self, amount):
return f"PayPal processed ${amount}"
# No refund - some payment methods don't support it
# SRP - Each class has one responsibility
class Order:
def __init__(self, items, total):
self.items = items
self.total = total
class OrderProcessor:
def __init__(self, payment: PaymentProcessor):
self.payment = payment
def process_order(self, order: Order):
result = self.payment.process(order.total)
print(result)
return True
# LSP - Can substitute any PaymentProcessor
processors = [
OrderProcessor(StripePayment()),
OrderProcessor(PayPalPayment())
]
order = Order(["item1", "item2"], 100)
for processor in processors:
processor.process_order(order) # Works with any processorWhen to Use SOLID:
- ✅ Building large applications
- ✅ Code that will be maintained long-term
- ✅ Teams working on same codebase
- ✅ When you need flexibility
When to Skip:
- ⚠️ Small scripts or prototypes
- ⚠️ One-time use code
- ⚠️ Very simple applications
Remember: SOLID principles guide good design but aren’t absolute rules. Use judgment based on your project’s needs.
Additional Real-World System Designs
36. Design Pastebin (Text Sharing Service)
Pastebin allows users to share text snippets via short URLs.
36.1 Requirements
Functional:
- Users paste text and get a unique short URL
- Users access URL to view content
- Optional expiration time
- Track view statistics
Non-Functional:
- High availability
- Low latency for URL generation
- Handle 10M users, 10M writes/month, 100M reads/month
- 10:1 read-to-write ratio
36.2 Capacity Estimation
Storage:
Average paste size: 1 KB
Metadata: ~270 bytes (URL, expiration, timestamps)
Total per paste: ~1.27 KB
Monthly storage: 1.27 KB × 10M = 12.7 GB/month
3-year storage: 12.7 GB × 36 = 457 GBTraffic:
Write QPS: 10M/month ÷ 2.5M seconds = 4 writes/second
Read QPS: 100M/month ÷ 2.5M seconds = 40 reads/second
Peak: 2× average = 8 writes/sec, 80 reads/sec36.3 High-Level Design
36.4 Implementation
import hashlib
import base64
from datetime import datetime, timedelta
class PastebinService:
def __init__(self, db, object_store, cache):
self.db = db
self.object_store = object_store
self.cache = cache
def create_paste(self, content, expiration_minutes=None):
"""Create a new paste and return short URL"""
# Generate unique ID using MD5 + Base62
unique_str = content + str(datetime.now().timestamp())
hash_value = hashlib.md5(unique_str.encode()).hexdigest()
short_id = self._base62_encode(int(hash_value[:16], 16))[:7]
# Store content in object store
object_key = f"pastes/{short_id}"
self.object_store.put(object_key, content)
# Store metadata in database
paste_metadata = {
'short_id': short_id,
'object_key': object_key,
'created_at': datetime.now(),
'expires_at': datetime.now() + timedelta(minutes=expiration_minutes)
if expiration_minutes else None,
'size_bytes': len(content)
}
self.db.insert('pastes', paste_metadata)
return short_id
def get_paste(self, short_id):
"""Retrieve paste content"""
# Check cache first
cache_key = f"paste:{short_id}"
cached = self.cache.get(cache_key)
if cached:
return cached
# Get metadata from database
metadata = self.db.query(f"SELECT * FROM pastes WHERE short_id = '{short_id}'")
if not metadata:
return None
# Check if expired
if metadata['expires_at'] and datetime.now() > metadata['expires_at']:
return None
# Fetch content from object store
content = self.object_store.get(metadata['object_key'])
# Cache for future requests
self.cache.set(cache_key, content, ttl=3600)
# Update view count asynchronously
self.db.execute(f"UPDATE pastes SET views = views + 1 WHERE short_id = '{short_id}'")
return content
def _base62_encode(self, num):
"""Encode number to Base62"""
chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
if num == 0:
return chars[0]
result = []
while num > 0:
result.append(chars[num % 62])
num //= 62
return ''.join(reversed(result))
# Usage
service = PastebinService(db, s3, redis)
url = service.create_paste("Hello World!", expiration_minutes=60)
content = service.get_paste(url)37. Design a Web Crawler
A web crawler systematically browses the web to index pages for search engines.
37.1 Requirements
Functional:
- Crawl 1 billion links
- Generate reverse index (words → pages)
- Extract titles and snippets
- Respect robots.txt
- Handle duplicate content
Non-Functional:
- Scalable to billions of pages
- Fresh content (recrawl weekly)
- Avoid infinite loops
- Politeness (rate limiting per domain)
37.2 Capacity Estimation
1 billion links to crawl
Average page size: 500 KB
Crawl frequency: Weekly
Monthly crawls: 4 billion pages
Monthly storage: 500 KB × 4B = 2 PB/month
Write QPS: 4B / 2.5M seconds = 1,600 writes/second
Search QPS: 100B / 2.5M seconds = 40,000 searches/second37.3 Architecture
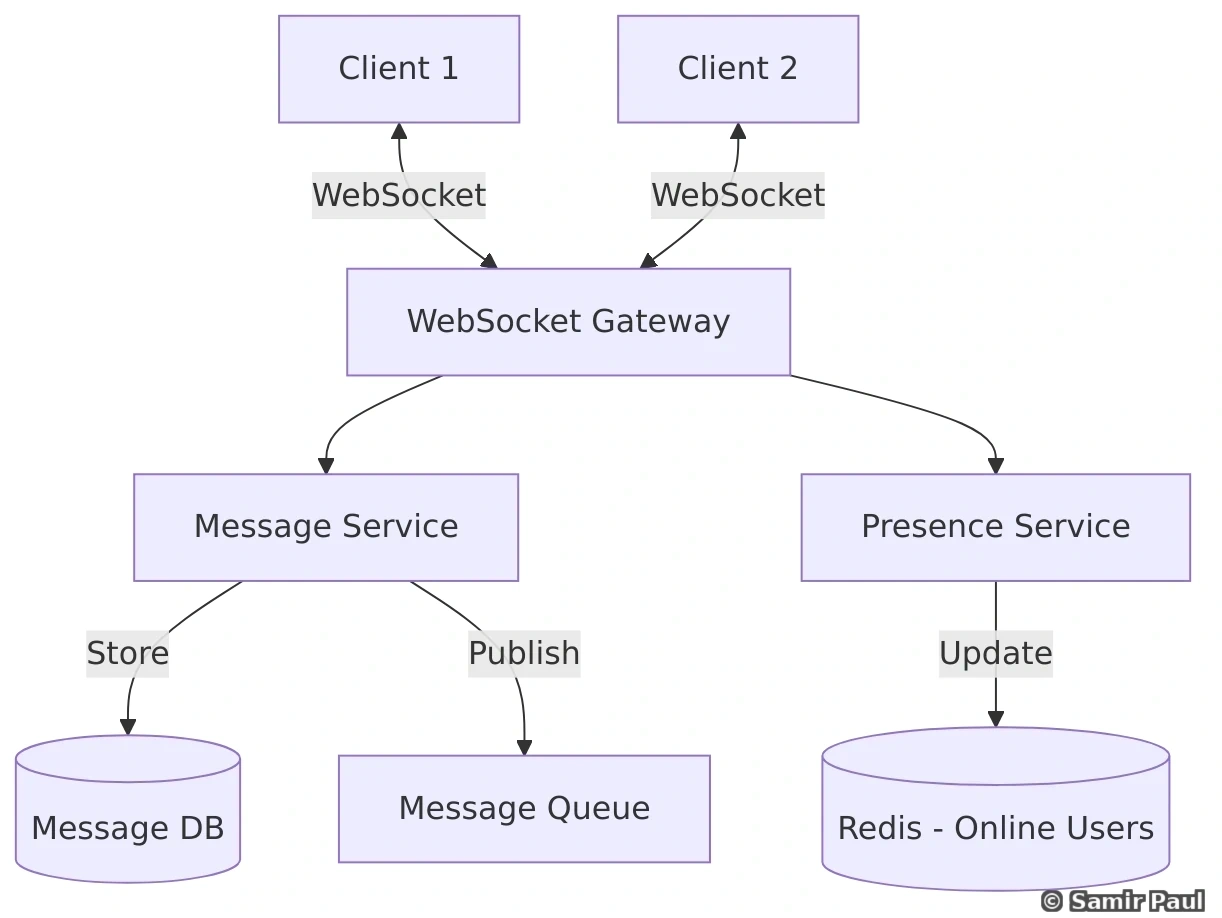
37.4 Implementation
import hashlib
from collections import deque
from urllib.parse import urljoin, urlparse
import requests
from bs4 import BeautifulSoup
class WebCrawler:
def __init__(self, seed_urls, max_pages=1000):
self.to_crawl = deque(seed_urls)
self.crawled = set()
self.page_signatures = {}
self.max_pages = max_pages
self.crawled_count = 0
def crawl(self):
"""Main crawling loop"""
while self.to_crawl and self.crawled_count < self.max_pages:
url = self.to_crawl.popleft()
if url in self.crawled:
continue
try:
page_data = self.fetch_page(url)
if not page_data:
continue
# Check for duplicates
signature = self.create_signature(page_data['content'])
if signature in self.page_signatures:
print(f"Duplicate content: {url}")
continue
self.page_signatures[signature] = url
self.crawled.add(url)
self.crawled_count += 1
# Extract and queue new URLs
new_urls = self.extract_urls(url, page_data['content'])
for new_url in new_urls:
if new_url not in self.crawled:
self.to_crawl.append(new_url)
# Process page (index, store, etc.)
self.process_page(url, page_data)
print(f"Crawled ({self.crawled_count}): {url}")
except Exception as e:
print(f"Error crawling {url}: {e}")
def fetch_page(self, url):
"""Fetch page content"""
try:
response = requests.get(url, timeout=5)
if response.status_code == 200:
return {
'url': url,
'content': response.text,
'headers': dict(response.headers)
}
except:
return None
def create_signature(self, content):
"""Create page signature for duplicate detection"""
# Normalize and hash content
normalized = content.lower().strip()
return hashlib.md5(normalized.encode()).hexdigest()
def extract_urls(self, base_url, html_content):
"""Extract all URLs from page"""
soup = BeautifulSoup(html_content, 'html.parser')
urls = []
for link in soup.find_all('a', href=True):
url = urljoin(base_url, link['href'])
# Filter only HTTP(S) URLs
if urlparse(url).scheme in ['http', 'https']:
urls.append(url)
return urls
def process_page(self, url, page_data):
"""Process crawled page - index, store, etc."""
# Extract title and snippet
soup = BeautifulSoup(page_data['content'], 'html.parser')
title = soup.find('title').text if soup.find('title') else url
# Create reverse index (word -> URLs)
words = self.tokenize(page_data['content'])
# Store in reverse index...
# Store document
# Store in document service...
print(f" Title: {title}")
print(f" Words: {len(words)}")
def tokenize(self, text):
"""Simple tokenization"""
soup = BeautifulSoup(text, 'html.parser')
text = soup.get_text()
words = text.lower().split()
return [w.strip('.,!?;:()[]{}') for w in words if len(w) > 2]
# Usage
crawler = WebCrawler(['https://example.com'], max_pages=100)
crawler.crawl()Advanced Features:
class PoliteCrawler(WebCrawler):
"""Crawler with politeness - rate limiting per domain"""
def __init__(self, seed_urls, max_pages=1000, delay_seconds=1):
super().__init__(seed_urls, max_pages)
self.domain_last_crawl = {}
self.delay_seconds = delay_seconds
def can_crawl_domain(self, url):
"""Check if enough time has passed since last crawl"""
import time
domain = urlparse(url).netloc
last_crawl = self.domain_last_crawl.get(domain, 0)
if time.time() - last_crawl < self.delay_seconds:
return False
self.domain_last_crawl[domain] = time.time()
return True
def fetch_page(self, url):
"""Fetch with politeness check"""
if not self.can_crawl_domain(url):
return None
return super().fetch_page(url)38. Design Mint.com (Personal Finance Tracker)
Mint.com aggregates financial data from multiple sources and provides insights.
38.1 Requirements
Functional:
- Connect to multiple bank accounts
- Automatically categorize transactions
- Budget tracking and alerts
- Financial insights and trends
- Bill reminders
Non-Functional:
- Highly secure (financial data)
- Near real-time sync
- Support millions of users
- 99.99% uptime
38.2 Architecture
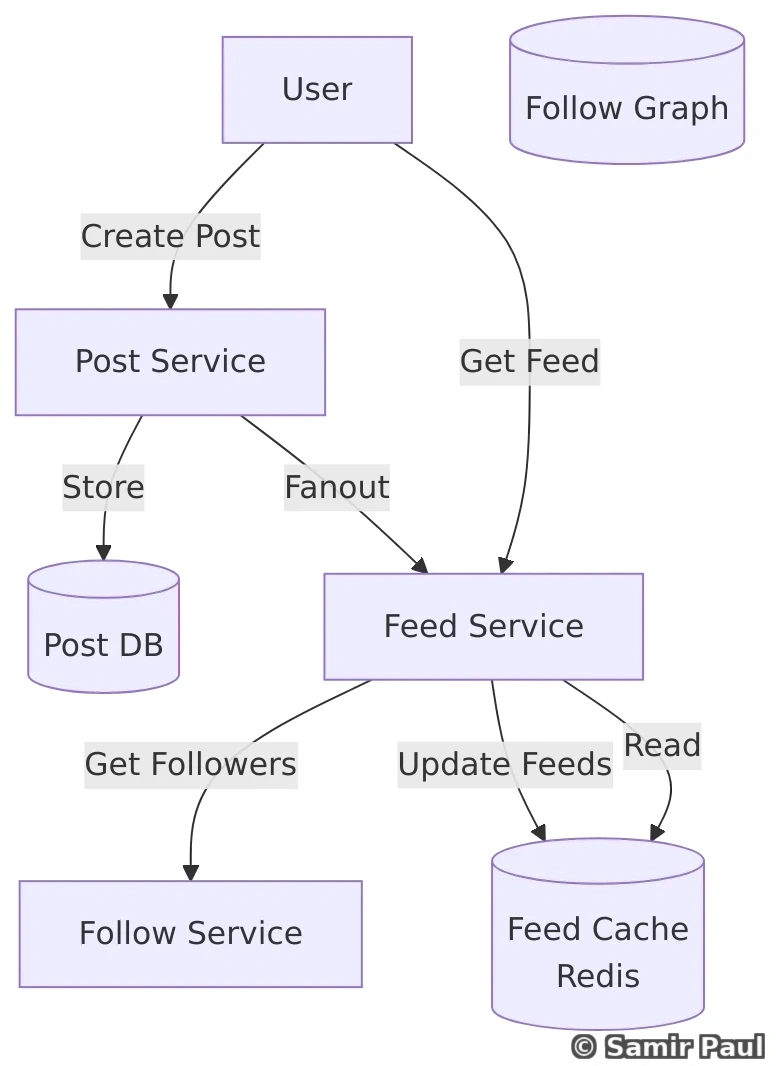
38.3 Key Components
Transaction Categorization (ML-based):
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
class TransactionCategorizer:
def __init__(self):
self.vectorizer = TfidfVectorizer(max_features=1000)
self.classifier = MultinomialNB()
self.categories = [
'Groceries', 'Restaurants', 'Transportation',
'Entertainment', 'Bills', 'Shopping', 'Healthcare',
'Travel', 'Income', 'Other'
]
def train(self, transactions, labels):
"""Train categorizer on labeled data"""
descriptions = [t['description'] for t in transactions]
X = self.vectorizer.fit_transform(descriptions)
self.classifier.fit(X, labels)
def categorize(self, transaction):
"""Predict category for new transaction"""
description = transaction['description']
X = self.vectorizer.transform([description])
category_idx = self.classifier.predict(X)[0]
confidence = max(self.classifier.predict_proba(X)[0])
return {
'category': self.categories[category_idx],
'confidence': confidence
}
class MintService:
def __init__(self):
self.categorizer = TransactionCategorizer()
self.accounts = {}
self.transactions = []
def sync_accounts(self, user_id):
"""Sync transactions from all connected accounts"""
accounts = self.get_user_accounts(user_id)
new_transactions = []
for account in accounts:
# Fetch from bank API (via Plaid/Yodlee)
recent_transactions = self.fetch_transactions(account)
for txn in recent_transactions:
# Categorize automatically
category_info = self.categorizer.categorize(txn)
txn['category'] = category_info['category']
txn['auto_categorized'] = True
new_transactions.append(txn)
# Store transactions
self.store_transactions(user_id, new_transactions)
# Check budget alerts
self.check_budget_alerts(user_id)
return new_transactions
def get_user_accounts(self, user_id):
"""Get all linked accounts for user"""
return [] # Query from database
def fetch_transactions(self, account):
"""Fetch transactions from bank via aggregator"""
return [] # Call Plaid/Yodlee API
def store_transactions(self, user_id, transactions):
"""Store transactions in database"""
pass
def check_budget_alerts(self, user_id):
"""Check if user exceeded budget categories"""
budgets = self.get_user_budgets(user_id)
spending = self.calculate_spending(user_id)
alerts = []
for category, limit in budgets.items():
if spending.get(category, 0) > limit:
alerts.append({
'type': 'budget_exceeded',
'category': category,
'limit': limit,
'actual': spending[category]
})
if alerts:
self.send_alerts(user_id, alerts)
return alerts
def get_user_budgets(self, user_id):
"""Get budget limits for user"""
return {
'Groceries': 500,
'Restaurants': 300,
'Entertainment': 200
}
def calculate_spending(self, user_id):
"""Calculate spending by category this month"""
return {
'Groceries': 450,
'Restaurants': 350, # Exceeded!
'Entertainment': 150
}
def send_alerts(self, user_id, alerts):
"""Send push notification/email"""
print(f"Alerts for user {user_id}: {alerts}")Security Considerations:
- Encrypt bank credentials at rest
- Use OAuth2 for authentication
- PCI DSS compliance
- End-to-end encryption
- Regular security audits
39. Design a Social Network Graph
Storing and querying social connections efficiently.
39.1 Requirements
Functional:
- Add/remove friendships
- Find friends of user
- Find mutual friends
- Friend recommendations
- Degree of separation
Non-Functional:
- Billions of users
- Millions of connections per user
- Fast friend queries (< 100ms)
- Scale horizontally
39.2 Data Structures
Adjacency List (Most Common):
class SocialGraph:
def __init__(self):
self.adjacency_list = {} # user_id -> set of friend_ids
def add_friendship(self, user1, user2):
"""Add bidirectional friendship"""
if user1 not in self.adjacency_list:
self.adjacency_list[user1] = set()
if user2 not in self.adjacency_list:
self.adjacency_list[user2] = set()
self.adjacency_list[user1].add(user2)
self.adjacency_list[user2].add(user1)
def remove_friendship(self, user1, user2):
"""Remove friendship"""
if user1 in self.adjacency_list:
self.adjacency_list[user1].discard(user2)
if user2 in self.adjacency_list:
self.adjacency_list[user2].discard(user1)
def get_friends(self, user_id):
"""Get all friends of user"""
return self.adjacency_list.get(user_id, set())
def get_mutual_friends(self, user1, user2):
"""Find mutual friends between two users"""
friends1 = self.get_friends(user1)
friends2 = self.get_friends(user2)
return friends1 & friends2 # Set intersection
def are_friends(self, user1, user2):
"""Check if two users are friends"""
return user2 in self.adjacency_list.get(user1, set())
def get_friend_count(self, user_id):
"""Get number of friends"""
return len(self.adjacency_list.get(user_id, set()))
def friend_recommendations(self, user_id, limit=10):
"""Recommend friends (friends of friends)"""
friends = self.get_friends(user_id)
recommendations = {}
# Find friends of friends
for friend in friends:
for friend_of_friend in self.get_friends(friend):
if friend_of_friend == user_id:
continue
if friend_of_friend in friends:
continue
# Count mutual friends
recommendations[friend_of_friend] = \
recommendations.get(friend_of_friend, 0) + 1
# Sort by number of mutual friends
sorted_recs = sorted(
recommendations.items(),
key=lambda x: x[1],
reverse=True
)
return [user for user, _ in sorted_recs[:limit]]
def degrees_of_separation(self, user1, user2):
"""Find shortest path between two users (BFS)"""
if user1 == user2:
return 0
from collections import deque
queue = deque([(user1, 0)])
visited = {user1}
while queue:
current_user, distance = queue.popleft()
for friend in self.get_friends(current_user):
if friend == user2:
return distance + 1
if friend not in visited:
visited.add(friend)
queue.append((friend, distance + 1))
return -1 # Not connected
# Usage
graph = SocialGraph()
graph.add_friendship("alice", "bob")
graph.add_friendship("bob", "charlie")
graph.add_friendship("charlie", "david")
print(graph.degrees_of_separation("alice", "david")) # 3
print(graph.friend_recommendations("alice")) # ['charlie']Database Schema for Scale:
-- Users table
CREATE TABLE users (
user_id BIGINT PRIMARY KEY,
username VARCHAR(50) UNIQUE,
created_at TIMESTAMP
);
-- Friendships table (bidirectional)
CREATE TABLE friendships (
user_id1 BIGINT,
user_id2 BIGINT,
created_at TIMESTAMP,
PRIMARY KEY (user_id1, user_id2),
INDEX idx_user1 (user_id1),
INDEX idx_user2 (user_id2)
);
-- Denormalized for faster queries
CREATE TABLE user_friends_count (
user_id BIGINT PRIMARY KEY,
friend_count INT,
updated_at TIMESTAMP
);40. Design Amazon Sales Rank by Category
Track best-selling products per category in real-time.
40.1 Requirements
Functional:
- Track sales for millions of products
- Calculate rank per category
- Update ranks in near real-time
- Support historical rankings
Non-Functional:
- Handle millions of sales/hour
- Rankings updated within 1 hour
- Support 1000s of categories
- Scalable to billions of products
40.2 Architecture
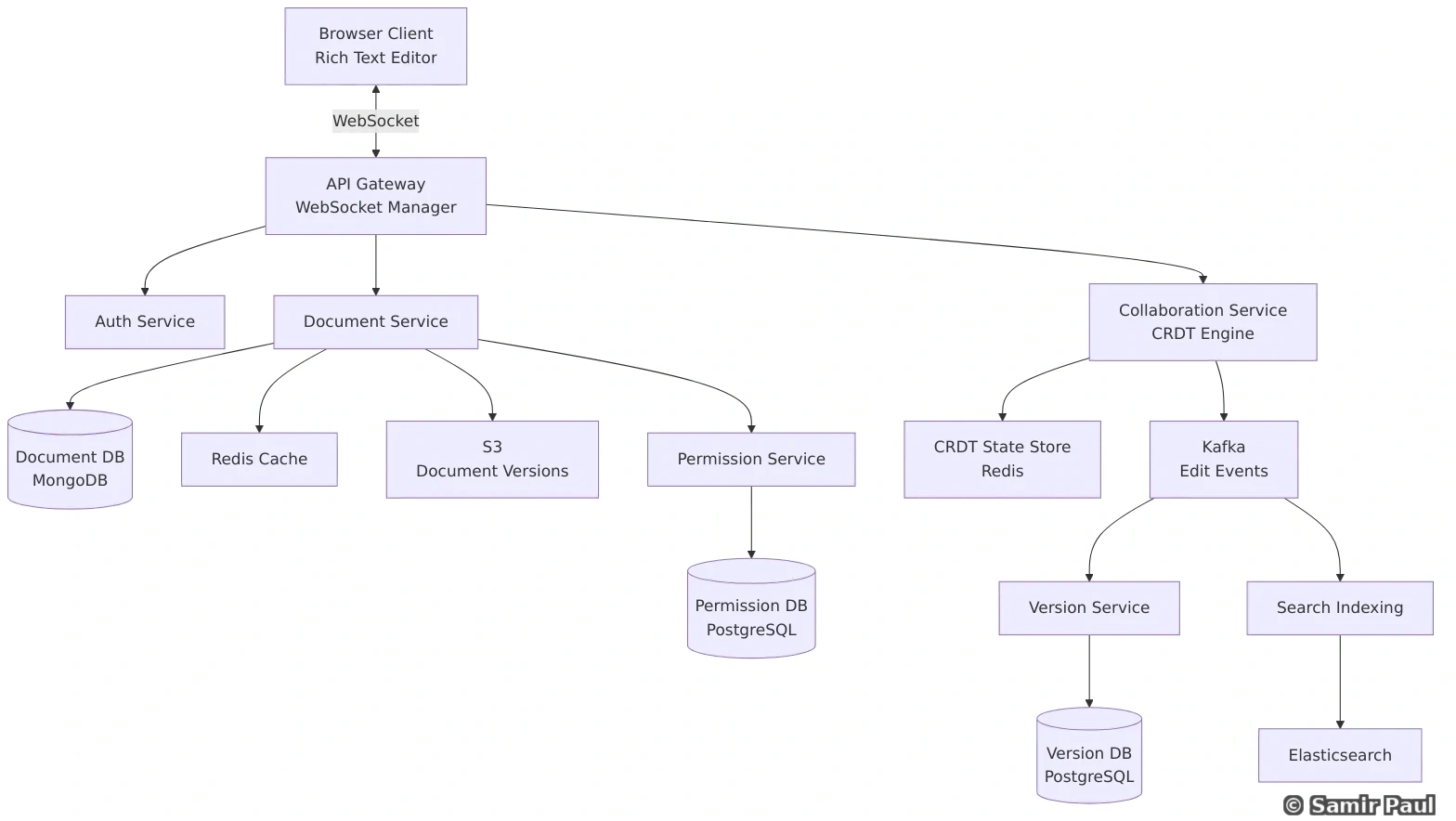
40.3 Implementation
from collections import defaultdict
import heapq
class SalesRankingService:
def __init__(self):
self.sales_by_category = defaultdict(lambda: defaultdict(int))
# category -> {product_id -> sales_count}
self.ranks_by_category = defaultdict(list)
# category -> [(sales_count, product_id), ...]
def record_sale(self, product_id, category_id, timestamp):
"""Record a product sale"""
self.sales_by_category[category_id][product_id] += 1
def calculate_ranks(self, category_id):
"""Calculate rankings for category"""
sales = self.sales_by_category[category_id]
# Sort by sales count (descending)
sorted_products = sorted(
sales.items(),
key=lambda x: x[1],
reverse=True
)
# Store ranks
ranks = []
for rank, (product_id, sales_count) in enumerate(sorted_products, 1):
ranks.append({
'rank': rank,
'product_id': product_id,
'sales_count': sales_count
})
return ranks
def get_top_n(self, category_id, n=100):
"""Get top N products in category"""
ranks = self.calculate_ranks(category_id)
return ranks[:n]
def get_product_rank(self, product_id, category_id):
"""Get rank of specific product"""
ranks = self.calculate_ranks(category_id)
for item in ranks:
if item['product_id'] == product_id:
return item['rank']
return None
# For scale: Use sliding window aggregation
class StreamingSalesRank:
"""Real-time ranking using sliding window"""
def __init__(self, window_hours=24):
self.window_hours = window_hours
self.hourly_buckets = defaultdict(lambda: defaultdict(lambda: defaultdict(int)))
# timestamp_hour -> category -> product -> count
def record_sale(self, product_id, category_id, timestamp):
"""Record sale in time bucket"""
import datetime
hour_bucket = timestamp.replace(minute=0, second=0, microsecond=0)
self.hourly_buckets[hour_bucket][category_id][product_id] += 1
def get_rankings(self, category_id):
"""Get rankings for category using sliding window"""
import datetime
now = datetime.datetime.now()
start_window = now - datetime.timedelta(hours=self.window_hours)
# Aggregate sales in window
total_sales = defaultdict(int)
for hour_bucket, categories in self.hourly_buckets.items():
if hour_bucket >= start_window:
for product_id, count in categories[category_id].items():
total_sales[product_id] += count
# Calculate ranks
sorted_products = sorted(
total_sales.items(),
key=lambda x: x[1],
reverse=True
)
return [(rank, pid, count)
for rank, (pid, count) in enumerate(sorted_products, 1)]Section 41: Design a System that Scales to Millions of Users on AWS
Overview
Scaling a web application from a single user to millions requires an iterative approach: Benchmark → Profile → Address Bottlenecks → Repeat. This section demonstrates progressive scaling strategies using AWS services, applicable to any cloud platform.
Problem Requirements
Use Cases:
- User makes read/write requests
- Service processes requests and stores data
- Evolution from 1 user to 10 million users
- Maintain high availability throughout
Traffic Assumptions:
- 10 million users
- 1 billion writes per month (~400 writes/sec)
- 100 billion reads per month (~40,000 reads/sec)
- 100:1 read-to-write ratio
- 1 KB per write
- 1 TB new content per month
- 36 TB in 3 years
Evolution Stage 1: Single Server (1-100 Users)
Architecture:
- Single EC2 instance running web server
- MySQL database on same instance
- Public static IP (Elastic IP)
- Route 53 for DNS mapping
Characteristics:
- Vertical scaling only
- No redundancy
- Simple monitoring (CloudWatch, CPU, memory)
- Open ports: 80 (HTTP), 443 (HTTPS), 22 (SSH - whitelisted IPs only)
# Simple single-server setup
class SingleServerApp:
def __init__(self):
self.db = MySQLDatabase()
def handle_request(self, user_id, data):
# Process request
result = self.process(data)
# Store in local database
self.db.save(user_id, result)
return resultEvolution Stage 2: Separate Components (100-1000 Users)
Key Changes:
- Move MySQL to RDS (managed database service)
- Store static content on S3 (object storage)
- Implement VPC with public/private subnets
Benefits:
- Independent scaling of components
- Reduced load on web server
- Automatic backups and multi-AZ replication (RDS)
- Server-side encryption at rest
Architecture:
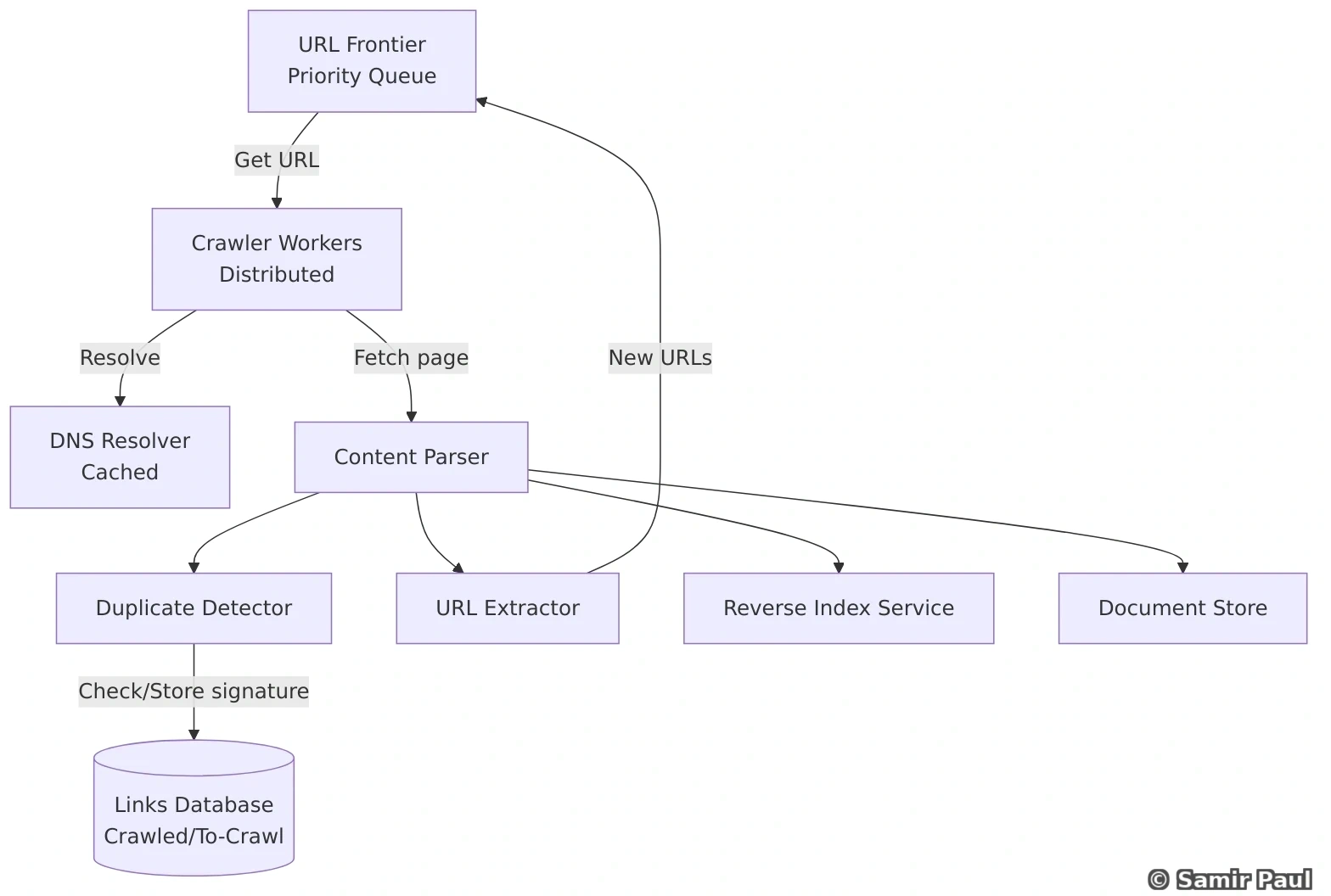
Evolution Stage 3: Horizontal Scaling (1,000-10,000 Users)
Key Changes:
- Add Elastic Load Balancer (ELB)
- Multiple web servers across availability zones
- Master-Slave MySQL replication
- Separate web and application tiers
- CloudFront CDN for static content
Load Balancer Configuration:
class LoadBalancedArchitecture:
def __init__(self):
self.load_balancer = ELB()
self.web_servers = [
WebServer(az='us-east-1a'),
WebServer(az='us-east-1b'),
WebServer(az='us-east-1c')
]
self.app_servers = [
AppServer(type='read_api'),
AppServer(type='write_api')
]
self.db_master = RDS_Master()
self.db_slaves = [RDS_Slave(), RDS_Slave()]
def route_request(self, request):
# ELB distributes to web servers
web_server = self.load_balancer.select_server()
# Web server routes to appropriate app server
if request.method == 'GET':
app_server = self.select_read_server()
else:
app_server = self.select_write_server()
return app_server.handle(request)
def select_read_server(self):
# Route reads to slave replicas
return random.choice(self.app_servers)Architecture:
Evolution Stage 4: Caching Layer (10,000-100,000 Users)
Key Changes:
- Add ElastiCache (Redis/Memcached)
- Cache frequently accessed data from MySQL
- Store session data in cache (enables stateless web servers)
- Add more read replicas
Why Caching?
- Memory access: 250 microseconds
- SSD access: 1,000 microseconds (4x slower)
- Disk access: 20,000 microseconds (80x slower)
class CachedArchitecture:
def __init__(self):
self.cache = Redis() # ElastiCache
self.db_master = RDS_Master()
self.db_slaves = [RDS_Slave() for _ in range(3)]
def read_data(self, key):
# Try cache first
cached = self.cache.get(key)
if cached:
return cached
# Cache miss - read from slave
slave = random.choice(self.db_slaves)
data = slave.query(key)
# Update cache
self.cache.set(key, data, ttl=3600)
return data
def write_data(self, key, value):
# Write to master
self.db_master.write(key, value)
# Invalidate cache
self.cache.delete(key)
def store_session(self, session_id, session_data):
# Store session in Redis for stateless servers
self.cache.set(f"session:{session_id}", session_data, ttl=1800)Evolution Stage 5: Autoscaling (100,000-1M Users)
Key Changes:
- Auto Scaling Groups for web and app servers
- CloudWatch metrics trigger scaling
- Chef/Puppet/Ansible for configuration management
- Enhanced monitoring and alerting
Autoscaling Configuration:
class AutoScalingConfig:
def __init__(self):
self.web_server_group = AutoScalingGroup(
min_instances=2,
max_instances=20,
desired_capacity=5,
availability_zones=['us-east-1a', 'us-east-1b', 'us-east-1c']
)
self.app_server_group = AutoScalingGroup(
min_instances=3,
max_instances=30,
desired_capacity=10
)
def configure_scaling_policies(self):
# Scale up when CPU > 70% for 5 minutes
scale_up_policy = ScalingPolicy(
metric='CPUUtilization',
threshold=70,
comparison='GreaterThanThreshold',
evaluation_periods=2,
period=300,
action='add',
adjustment=2 # Add 2 instances
)
# Scale down when CPU < 30% for 10 minutes
scale_down_policy = ScalingPolicy(
metric='CPUUtilization',
threshold=30,
comparison='LessThanThreshold',
evaluation_periods=2,
period=600,
action='remove',
adjustment=1 # Remove 1 instance
)
return [scale_up_policy, scale_down_policy]Monitoring Stack:
- CloudWatch for metrics
- CloudTrail for API logging
- PagerDuty for incident management
- Sentry for error tracking
- New Relic for application performance
Evolution Stage 6: Advanced Scaling (1M-10M Users)
Key Changes:
- Database sharding or federation
- NoSQL databases (DynamoDB) for specific use cases
- Data warehouse (Redshift) for analytics
- Asynchronous processing with SQS and Lambda
When to Use NoSQL:
- High write throughput (> 400 writes/sec)
- Simple key-value access patterns
- Denormalized data structures
- Geographic distribution needs
Asynchronous Processing:
class AsyncArchitecture:
def __init__(self):
self.sqs = SQS_Queue('image-processing-queue')
self.lambda_function = Lambda('thumbnail-creator')
self.s3 = S3_Bucket('user-images')
self.dynamodb = DynamoDB_Table('image-metadata')
def upload_image(self, user_id, image_data):
# 1. Upload original to S3
image_key = f"images/{user_id}/{uuid.uuid4()}.jpg"
self.s3.put_object(image_key, image_data)
# 2. Send message to queue for processing
message = {
'user_id': user_id,
'image_key': image_key,
'created_at': datetime.now().isoformat()
}
self.sqs.send_message(message)
# 3. Return immediately (non-blocking)
return {'image_key': image_key, 'status': 'processing'}
def process_image_async(self, message):
# Lambda function triggered by SQS
image_key = message['image_key']
user_id = message['user_id']
# Download original
original = self.s3.get_object(image_key)
# Create thumbnail
thumbnail = self.create_thumbnail(original)
thumbnail_key = image_key.replace('.jpg', '_thumb.jpg')
self.s3.put_object(thumbnail_key, thumbnail)
# Update metadata
self.dynamodb.put_item({
'user_id': user_id,
'image_key': image_key,
'thumbnail_key': thumbnail_key,
'status': 'completed',
'processed_at': datetime.now().isoformat()
})Database Sharding Strategy:
class ShardedDatabase:
def __init__(self, num_shards=8):
self.shards = [RDS_Instance(f'shard-{i}') for i in range(num_shards)]
self.num_shards = num_shards
def get_shard(self, user_id):
# Hash-based sharding
shard_id = hash(user_id) % self.num_shards
return self.shards[shard_id]
def write_user_data(self, user_id, data):
shard = self.get_shard(user_id)
shard.write(user_id, data)
def read_user_data(self, user_id):
shard = self.get_shard(user_id)
return shard.read(user_id)Cost Optimization Strategies
Right-sizing Instances:
- Use T3 instances for variable workloads (burstable CPU)
- Use C5 for compute-intensive tasks
- Use R5 for memory-intensive workloads
Reserved Instances:
- 1-year or 3-year commitments for baseline capacity
- Save up to 75% vs on-demand pricing
Spot Instances:
- Use for fault-tolerant, flexible workloads
- Save up to 90% vs on-demand
class CostOptimizedScaling:
def __init__(self):
self.baseline_servers = [
EC2_Reserved('c5.large') for _ in range(5) # Reserved instances
]
self.burst_servers = [] # Spot instances
self.peak_servers = [] # On-demand instances
def handle_traffic_spike(self, current_load):
if current_load > self.baseline_capacity():
# Try to use spot instances first
spot_instance = self.request_spot_instance('c5.large', max_price=0.05)
if spot_instance:
self.burst_servers.append(spot_instance)
else:
# Fall back to on-demand
on_demand = self.launch_on_demand('c5.large')
self.peak_servers.append(on_demand)Disaster Recovery and Multi-Region
Strategies:
- Backup and Restore (RPO: hours, RTO: hours, cheapest)
- Pilot Light (RPO: minutes, RTO: 10s of minutes)
- Warm Standby (RPO: seconds, RTO: minutes)
- Multi-Region Active-Active (RPO: none, RTO: none, most expensive)
class MultiRegionArchitecture:
def __init__(self):
self.primary_region = Region('us-east-1')
self.secondary_region = Region('us-west-2')
self.route53 = Route53_HealthCheck()
def configure_failover(self):
# Health check on primary
self.route53.add_health_check(
endpoint=self.primary_region.load_balancer,
interval=30,
failure_threshold=3
)
# Failover routing policy
self.route53.add_record(
name='api.example.com',
type='A',
primary=self.primary_region.load_balancer,
secondary=self.secondary_region.load_balancer,
failover=True
)
def sync_data(self):
# Cross-region replication for S3
self.primary_region.s3.enable_cross_region_replication(
destination=self.secondary_region.s3
)
# Database replication
self.primary_region.rds.create_read_replica(
target_region='us-west-2'
)Key Takeaways
- Start Simple: Begin with single server, scale incrementally
- Monitor Everything: Use metrics to identify real bottlenecks
- Horizontal Scaling: Easier to scale than vertical
- Caching is Critical: Dramatically reduces database load
- Decouple Components: Use queues for asynchronous processing
- Plan for Failure: Multi-AZ, auto-healing, backups
- Cost vs Performance: Balance based on business needs
Progressive Evolution:
- 1-100 users: Single server
- 100-1K users: Separate database, object storage
- 1K-10K users: Load balancing, horizontal scaling
- 10K-100K users: Caching layer, more replicas
- 100K-1M users: Autoscaling, configuration management
- 1M-10M users: Sharding, NoSQL, async processing, multi-region
Section 42: Design a Query Cache for Search Engine
Overview
Design a distributed key-value cache to save results of recent web search queries, reducing latency and load on backend search services. This pattern applies to any high-traffic query system (Google, Bing, e-commerce search).
Problem Requirements
Use Cases:
- User sends search request → cache hit (fast response)
- User sends search request → cache miss (query backend, cache result)
- High availability with low latency
Traffic Assumptions:
- 10 million users
- 10 billion queries per month (~4,000 queries/sec)
- Traffic not evenly distributed (popular queries dominate)
- Limited cache memory (cannot store everything)
Capacity Estimation:
Each cache entry:
- Query: 50 bytes
- Title: 20 bytes
- Snippet: 200 bytes
- Total: 270 bytes per entry
If all 10 billion queries were unique:
- 270 bytes × 10 billion = 2.7 TB/month
- Reality: Popular queries repeat, need LRU eviction
QPS Calculation:
- 2.5 million seconds per month
- 10 billion queries / 2.5M seconds = 4,000 QPS
High-Level Architecture
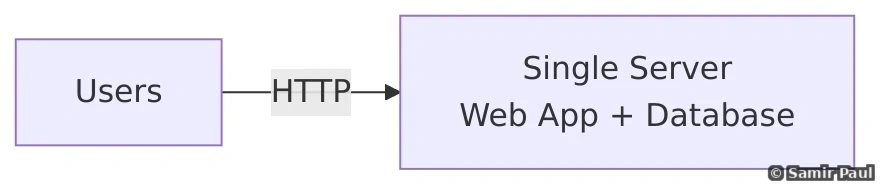
Component Design
1. Query API Server
Responsibilities:
- Parse and normalize queries
- Check cache first
- Route to search backend on miss
- Update cache with results
class QueryAPIServer:
def __init__(self, cache, reverse_index_service, document_service):
self.cache = cache
self.reverse_index = reverse_index_service
self.doc_service = document_service
def parse_query(self, raw_query):
"""Normalize query for consistent cache keys."""
# Remove HTML/markup
query = self.strip_html(raw_query)
# Fix typos (simple example)
query = self.spell_check(query)
# Normalize: lowercase, trim whitespace
query = query.lower().strip()
# Remove stop words for better matching
query = self.remove_stop_words(query)
# Convert to boolean operations
terms = query.split()
boolean_query = ' AND '.join(terms)
return boolean_query
def process_query(self, raw_query):
# 1. Parse and normalize
query = self.parse_query(raw_query)
# 2. Check cache
results = self.cache.get(query)
if results is not None:
print(f"Cache HIT for query: {query}")
return results
print(f"Cache MISS for query: {query}")
# 3. Query backend services
doc_ids = self.reverse_index.search(query)
results = self.doc_service.fetch_documents(doc_ids)
# 4. Update cache
self.cache.set(query, results)
return results
def strip_html(self, text):
# Remove HTML tags
import re
return re.sub(r'<[^>]+>', '', text)
def spell_check(self, query):
# Simplified: use edit distance or ML model
corrections = {
'gogle': 'google',
'amazn': 'amazon',
'facebok': 'facebook'
}
return corrections.get(query, query)
def remove_stop_words(self, query):
stop_words = {'the', 'a', 'an', 'and', 'or', 'but', 'in', 'on', 'at'}
words = query.split()
filtered = [w for w in words if w not in stop_words]
return ' '.join(filtered)2. LRU Cache Implementation
Use doubly-linked list + hash map for O(1) operations:
class Node:
def __init__(self, query, results):
self.query = query
self.results = results
self.prev = None
self.next = None
class DoublyLinkedList:
def __init__(self):
self.head = None
self.tail = None
def move_to_front(self, node):
"""Move existing node to front (most recently used)."""
if node == self.head:
return # Already at front
# Remove from current position
if node.prev:
node.prev.next = node.next
if node.next:
node.next.prev = node.prev
if node == self.tail:
self.tail = node.prev
# Move to front
node.prev = None
node.next = self.head
if self.head:
self.head.prev = node
self.head = node
if self.tail is None:
self.tail = node
def append_to_front(self, node):
"""Add new node to front."""
node.next = self.head
node.prev = None
if self.head:
self.head.prev = node
self.head = node
if self.tail is None:
self.tail = node
def remove_from_tail(self):
"""Remove least recently used node from tail."""
if self.tail is None:
return None
removed = self.tail
if self.tail.prev:
self.tail.prev.next = None
self.tail = self.tail.prev
else:
# Only one node
self.head = None
self.tail = None
return removed
class LRUCache:
def __init__(self, max_size):
self.max_size = max_size
self.size = 0
self.lookup = {} # query -> node
self.linked_list = DoublyLinkedList()
def get(self, query):
"""Get cached results. O(1) time complexity."""
node = self.lookup.get(query)
if node is None:
return None
# Move to front (mark as recently used)
self.linked_list.move_to_front(node)
return node.results
def set(self, query, results):
"""Cache query results. O(1) time complexity."""
node = self.lookup.get(query)
if node is not None:
# Update existing entry
node.results = results
self.linked_list.move_to_front(node)
else:
# New entry
if self.size >= self.max_size:
# Evict least recently used
evicted = self.linked_list.remove_from_tail()
if evicted:
del self.lookup[evicted.query]
self.size -= 1
# Add new node
new_node = Node(query, results)
self.linked_list.append_to_front(new_node)
self.lookup[query] = new_node
self.size += 1
def clear(self):
"""Clear entire cache."""
self.lookup.clear()
self.linked_list = DoublyLinkedList()
self.size = 0
# Example usage
cache = LRUCache(max_size=1000)
# Cache miss
results1 = cache.get("python tutorials") # None
# Store in cache
cache.set("python tutorials", ["Tutorial 1", "Tutorial 2", "Tutorial 3"])
# Cache hit
results2 = cache.get("python tutorials") # ["Tutorial 1", "Tutorial 2", "Tutorial 3"]3. Cache Update Strategies
When to update cache:
- Page content changes
- Page is added/removed
- Page rank changes (search ranking algorithm updates)
TTL (Time To Live) Approach:
import time
class CacheEntryWithTTL:
def __init__(self, query, results, ttl_seconds=3600):
self.query = query
self.results = results
self.created_at = time.time()
self.ttl = ttl_seconds
def is_expired(self):
return (time.time() - self.created_at) > self.ttl
class LRUCacheWithTTL(LRUCache):
def get(self, query):
node = self.lookup.get(query)
if node is None:
return None
# Check if expired
if isinstance(node, CacheEntryWithTTL) and node.is_expired():
# Remove expired entry
self.linked_list.remove_from_tail()
del self.lookup[query]
self.size -= 1
return None
self.linked_list.move_to_front(node)
return node.resultsCache Invalidation Strategies:
class CacheInvalidationService:
def __init__(self, cache):
self.cache = cache
def invalidate_by_pattern(self, pattern):
"""Invalidate all queries matching a pattern."""
# Example: Invalidate all queries containing "python"
keys_to_delete = [
key for key in self.cache.lookup.keys()
if pattern in key
]
for key in keys_to_delete:
node = self.cache.lookup[key]
# Remove from linked list and lookup
del self.cache.lookup[key]
self.cache.size -= 1
def invalidate_url(self, url):
"""When a URL is updated, invalidate queries that returned it."""
# In production, maintain reverse index: URL -> queries
passDistributed Caching at Scale
For 4,000 QPS and millions of entries, single-server cache won’t work.
Option 1: Replicate Cache on Every Server
- Simple but inefficient memory usage
- Low cache hit rate (each server has different subset)
Option 2: Dedicated Cache Servers (Recommended)
- Use consistent hashing to shard cache
- Multiple cache servers with replication
import hashlib
import bisect
class ConsistentHashRing:
def __init__(self, num_virtual_nodes=150):
self.num_virtual_nodes = num_virtual_nodes
self.ring = {} # hash_value -> server_id
self.sorted_hashes = []
def add_server(self, server_id):
for i in range(self.num_virtual_nodes):
virtual_key = f"{server_id}:{i}"
hash_value = int(hashlib.md5(virtual_key.encode()).hexdigest(), 16)
self.ring[hash_value] = server_id
bisect.insort(self.sorted_hashes, hash_value)
def remove_server(self, server_id):
for i in range(self.num_virtual_nodes):
virtual_key = f"{server_id}:{i}"
hash_value = int(hashlib.md5(virtual_key.encode()).hexdigest(), 16)
del self.ring[hash_value]
self.sorted_hashes.remove(hash_value)
def get_server(self, query):
query_hash = int(hashlib.md5(query.encode()).hexdigest(), 16)
idx = bisect.bisect_right(self.sorted_hashes, query_hash)
if idx == len(self.sorted_hashes):
idx = 0
server_hash = self.sorted_hashes[idx]
return self.ring[server_hash]
class DistributedCache:
def __init__(self, cache_servers):
self.hash_ring = ConsistentHashRing()
self.cache_servers = {} # server_id -> LRUCache instance
for server_id in cache_servers:
self.add_cache_server(server_id)
def add_cache_server(self, server_id):
self.hash_ring.add_server(server_id)
self.cache_servers[server_id] = LRUCache(max_size=100000)
def get(self, query):
server_id = self.hash_ring.get_server(query)
cache = self.cache_servers[server_id]
return cache.get(query)
def set(self, query, results):
server_id = self.hash_ring.get_server(query)
cache = self.cache_servers[server_id]
cache.set(query, results)
# Example: 5 cache servers
distributed_cache = DistributedCache(['cache-1', 'cache-2', 'cache-3', 'cache-4', 'cache-5'])
# Queries are automatically sharded
distributed_cache.set("python tutorials", ["Result 1", "Result 2"])
distributed_cache.set("java tutorials", ["Result 3", "Result 4"])
results = distributed_cache.get("python tutorials")Monitoring and Metrics
Key Metrics:
- Cache Hit Rate: (Hits / Total Requests) × 100%
- Cache Miss Latency: Time to fetch from backend
- Memory Usage: Prevent OOM
- Eviction Rate: How often entries are removed
class CacheMetrics:
def __init__(self):
self.hits = 0
self.misses = 0
self.total_latency = 0.0
self.evictions = 0
def record_hit(self):
self.hits += 1
def record_miss(self, latency):
self.misses += 1
self.total_latency += latency
def record_eviction(self):
self.evictions += 1
def get_stats(self):
total_requests = self.hits + self.misses
hit_rate = (self.hits / total_requests * 100) if total_requests > 0 else 0
avg_miss_latency = (self.total_latency / self.misses) if self.misses > 0 else 0
return {
'hit_rate': hit_rate,
'total_requests': total_requests,
'hits': self.hits,
'misses': self.misses,
'avg_miss_latency_ms': avg_miss_latency * 1000,
'evictions': self.evictions
}Complete System Integration
class SearchEngineQueryCache:
def __init__(self):
self.distributed_cache = DistributedCache(
['cache-1', 'cache-2', 'cache-3', 'cache-4', 'cache-5']
)
self.metrics = CacheMetrics()
self.reverse_index = ReverseIndexService()
self.doc_service = DocumentService()
def search(self, raw_query):
# Parse query
query = self.parse_query(raw_query)
# Check distributed cache
start_time = time.time()
results = self.distributed_cache.get(query)
if results is not None:
# Cache hit
self.metrics.record_hit()
return results
# Cache miss - query backend
doc_ids = self.reverse_index.search(query)
results = self.doc_service.fetch_documents(doc_ids)
# Record metrics
latency = time.time() - start_time
self.metrics.record_miss(latency)
# Update cache
self.distributed_cache.set(query, results)
return results
def parse_query(self, raw_query):
# Same as QueryAPIServer implementation
return raw_query.lower().strip()Trade-offs and Considerations
Memory vs Latency:
- Larger cache = higher hit rate but more memory cost
- Optimal size depends on query distribution (Zipf’s law)
TTL Selection:
- Short TTL (minutes): Fresh data, but more backend load
- Long TTL (hours): Less backend load, but stale data risk
- Adaptive TTL based on query popularity
Consistency:
- Cache-aside pattern: Simple but can serve stale data
- Write-through: Always consistent but slower writes
- Eventual consistency acceptable for search (not financial data)
Replication:
- Single cache node: Fast but single point of failure
- Replicated cache: High availability but consistency challenges
Key Takeaways
- LRU eviction balances memory usage and hit rate
- Consistent hashing enables horizontal scaling
- Cache-aside pattern works well for read-heavy workloads
- TTL prevents stale data without manual invalidation
- Monitoring hit rate guides cache size tuning
- Distributed caching required for high QPS (4,000+)
Performance Impact:
- Memory access: 0.25 ms
- Cache miss + SSD: 1 ms
- Cache miss + HDD: 20 ms
- 80x speedup vs disk for popular queries!
Section 43: Design an E-Commerce Website (Amazon-like)
Overview
Design a scalable e-commerce platform handling millions of products, orders, and users with features like product catalog, cart, checkout, inventory management, and order processing.
Problem Requirements
Functional Requirements:
- User registration/authentication
- Product browsing and search
- Shopping cart management
- Checkout and payment processing
- Order tracking
- Inventory management
- Seller portal (for marketplace model)
- Reviews and ratings
Non-Functional Requirements:
- 100 million active users
- 50 million products
- 1 million orders per day (~12 orders/sec)
- 99.99% availability
- Sub-second search latency
- ACID transactions for payments
- PCI DSS compliance
Capacity Estimation:
- Storage: 50M products × 10KB metadata = 500 GB
- Images: 50M products × 5 images × 500KB = 125 TB
- Orders: 1M/day × 365 × 5 years × 5KB = 9 TB
- Peak traffic: 12 orders/sec × 10 (peak multiplier) = 120 orders/sec
High-Level Architecture
Database Schema
# Product Schema
class Product:
id: UUID (PK)
seller_id: UUID (FK)
name: str
description: text
category_id: UUID (FK)
price: decimal(10, 2)
currency: str
brand: str
created_at: timestamp
updated_at: timestamp
is_active: boolean
class ProductImage:
id: UUID (PK)
product_id: UUID (FK)
image_url: str
is_primary: boolean
display_order: int
class Inventory:
id: UUID (PK)
product_id: UUID (FK)
warehouse_id: UUID (FK)
quantity: int
reserved_quantity: int # For pending orders
updated_at: timestamp
# Order Schema
class Order:
id: UUID (PK)
user_id: UUID (FK)
status: enum('pending', 'confirmed', 'shipped', 'delivered', 'cancelled')
subtotal: decimal(10, 2)
tax: decimal(10, 2)
shipping: decimal(10, 2)
total: decimal(10, 2)
shipping_address_id: UUID (FK)
billing_address_id: UUID (FK)
created_at: timestamp
updated_at: timestamp
class OrderItem:
id: UUID (PK)
order_id: UUID (FK)
product_id: UUID (FK)
quantity: int
unit_price: decimal(10, 2)
total_price: decimal(10, 2)
class Payment:
id: UUID (PK)
order_id: UUID (FK)
payment_method: enum('credit_card', 'debit_card', 'paypal', 'crypto')
amount: decimal(10, 2)
status: enum('pending', 'completed', 'failed', 'refunded')
transaction_id: str # From payment gateway
created_at: timestampCore Service Implementations
1. Product Service
from flask import Flask, jsonify, request
import redis
import psycopg2
class ProductService:
def __init__(self):
self.db = psycopg2.connect("dbname=products user=admin")
self.cache = redis.Redis(host='localhost', port=6379)
def get_product(self, product_id):
# Try cache first
cache_key = f"product:{product_id}"
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
# Cache miss - query database
cursor = self.db.cursor()
cursor.execute("""
SELECT p.*, array_agg(pi.image_url) as images
FROM products p
LEFT JOIN product_images pi ON p.id = pi.product_id
WHERE p.id = %s AND p.is_active = true
GROUP BY p.id
""", (product_id,))
product = cursor.fetchone()
if product:
product_data = self.serialize_product(product)
# Cache for 1 hour
self.cache.setex(cache_key, 3600, json.dumps(product_data))
return product_data
return None
def search_products(self, query, filters, page=1, page_size=20):
# Delegate to Elasticsearch for full-text search
es_query = {
"query": {
"bool": {
"must": {
"multi_match": {
"query": query,
"fields": ["name^3", "description", "brand^2"]
}
},
"filter": self.build_filters(filters)
}
},
"from": (page - 1) * page_size,
"size": page_size,
"sort": [{"_score": "desc"}, {"created_at": "desc"}]
}
results = self.elasticsearch.search(index="products", body=es_query)
return results['hits']['hits']
def build_filters(self, filters):
filter_clauses = []
if filters.get('category'):
filter_clauses.append({"term": {"category_id": filters['category']}})
if filters.get('price_range'):
filter_clauses.append({
"range": {
"price": {
"gte": filters['price_range']['min'],
"lte": filters['price_range']['max']
}
}
})
if filters.get('brand'):
filter_clauses.append({"terms": {"brand": filters['brand']}})
return filter_clauses2. Cart Service (Redis-based)
import json
from datetime import timedelta
class CartService:
def __init__(self):
self.redis = redis.Redis(host='localhost', port=6379)
def add_to_cart(self, user_id, product_id, quantity):
cart_key = f"cart:{user_id}"
# Get current cart
cart = self.get_cart(user_id)
# Add/update item
if product_id in cart:
cart[product_id]['quantity'] += quantity
else:
# Fetch product details
product = self.product_service.get_product(product_id)
cart[product_id] = {
'product_id': product_id,
'name': product['name'],
'price': product['price'],
'quantity': quantity,
'image': product['images'][0] if product['images'] else None
}
# Save cart (expires in 7 days)
self.redis.setex(cart_key, timedelta(days=7), json.dumps(cart))
return cart
def get_cart(self, user_id):
cart_key = f"cart:{user_id}"
cart_data = self.redis.get(cart_key)
return json.loads(cart_data) if cart_data else {}
def remove_from_cart(self, user_id, product_id):
cart_key = f"cart:{user_id}"
cart = self.get_cart(user_id)
if product_id in cart:
del cart[product_id]
self.redis.setex(cart_key, timedelta(days=7), json.dumps(cart))
return cart
def clear_cart(self, user_id):
cart_key = f"cart:{user_id}"
self.redis.delete(cart_key)
def calculate_totals(self, user_id):
cart = self.get_cart(user_id)
subtotal = sum(
item['price'] * item['quantity']
for item in cart.values()
)
tax = subtotal * 0.08 # 8% tax
shipping = 10.00 if subtotal < 50 else 0.00 # Free shipping over $50
total = subtotal + tax + shipping
return {
'subtotal': subtotal,
'tax': tax,
'shipping': shipping,
'total': total
}3. Order Service with Transaction Management
from contextlib import contextmanager
import uuid
from datetime import datetime
class OrderService:
def __init__(self):
self.db = psycopg2.connect("dbname=orders user=admin")
self.kafka_producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
@contextmanager
def transaction(self):
"""Context manager for database transactions."""
conn = self.db
try:
yield conn
conn.commit()
except Exception as e:
conn.rollback()
raise e
def create_order(self, user_id, cart_items, shipping_address, payment_method):
"""Create order with ACID guarantees."""
with self.transaction() as conn:
cursor = conn.cursor()
# 1. Create order
order_id = str(uuid.uuid4())
totals = self.cart_service.calculate_totals(user_id)
cursor.execute("""
INSERT INTO orders (id, user_id, status, subtotal, tax, shipping, total, shipping_address_id, created_at)
VALUES (%s, %s, 'pending', %s, %s, %s, %s, %s, %s)
RETURNING id
""", (
order_id, user_id, totals['subtotal'], totals['tax'],
totals['shipping'], totals['total'], shipping_address['id'], datetime.now()
))
# 2. Create order items
for product_id, item in cart_items.items():
cursor.execute("""
INSERT INTO order_items (id, order_id, product_id, quantity, unit_price, total_price)
VALUES (%s, %s, %s, %s, %s, %s)
""", (
str(uuid.uuid4()), order_id, product_id, item['quantity'],
item['price'], item['price'] * item['quantity']
))
# 3. Reserve inventory
for product_id, item in cart_items.items():
cursor.execute("""
UPDATE inventory
SET reserved_quantity = reserved_quantity + %s
WHERE product_id = %s AND quantity - reserved_quantity >= %s
RETURNING id
""", (item['quantity'], product_id, item['quantity']))
if cursor.rowcount == 0:
raise InsufficientInventoryError(f"Product {product_id} out of stock")
# 4. Process payment
payment_result = self.payment_service.process_payment(
order_id, payment_method, totals['total']
)
if not payment_result['success']:
raise PaymentFailedError("Payment processing failed")
# 5. Update order status
cursor.execute("""
UPDATE orders SET status = 'confirmed' WHERE id = %s
""", (order_id,))
# 6. Publish event to Kafka
self.kafka_producer.send('order-events', {
'event_type': 'order_created',
'order_id': order_id,
'user_id': user_id,
'total': totals['total'],
'timestamp': datetime.now().isoformat()
})
# 7. Clear cart
self.cart_service.clear_cart(user_id)
return {
'order_id': order_id,
'status': 'confirmed',
'total': totals['total']
}4. Inventory Management
class InventoryService:
def __init__(self):
self.db = psycopg2.connect("dbname=inventory user=admin")
self.kafka_consumer = KafkaConsumer(
'order-events',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
def listen_for_orders(self):
"""Background worker to process order events."""
for message in self.kafka_consumer:
event = message.value
if event['event_type'] == 'order_confirmed':
self.deduct_inventory(event['order_id'])
elif event['event_type'] == 'order_cancelled':
self.release_inventory(event['order_id'])
def deduct_inventory(self, order_id):
"""Move reserved quantity to actual deduction."""
with self.transaction() as conn:
cursor = conn.cursor()
# Get order items
cursor.execute("""
SELECT product_id, quantity FROM order_items WHERE order_id = %s
""", (order_id,))
order_items = cursor.fetchall()
for product_id, quantity in order_items:
cursor.execute("""
UPDATE inventory
SET quantity = quantity - %s,
reserved_quantity = reserved_quantity - %s,
updated_at = NOW()
WHERE product_id = %s
""", (quantity, quantity, product_id))
def check_availability(self, product_id, quantity):
"""Check if product is available."""
cursor = self.db.cursor()
cursor.execute("""
SELECT (quantity - reserved_quantity) as available
FROM inventory
WHERE product_id = %s
""", (product_id,))
result = cursor.fetchone()
return result[0] >= quantity if result else FalseSearch Implementation with Elasticsearch
from elasticsearch import Elasticsearch
class SearchService:
def __init__(self):
self.es = Elasticsearch(['localhost:9200'])
def index_product(self, product):
"""Index product for search."""
self.es.index(index='products', id=product['id'], body={
'name': product['name'],
'description': product['description'],
'category': product['category'],
'brand': product['brand'],
'price': product['price'],
'rating': product.get('rating', 0),
'num_reviews': product.get('num_reviews', 0),
'in_stock': product.get('in_stock', True),
'created_at': product['created_at']
})
def autocomplete(self, query):
"""Suggest completions for search query."""
result = self.es.search(index='products', body={
'suggest': {
'product-suggest': {
'prefix': query,
'completion': {
'field': 'name.completion',
'size': 10,
'skip_duplicates': True
}
}
}
})
suggestions = result['suggest']['product-suggest'][0]['options']
return [s['text'] for s in suggestions]Scalability Optimizations
1. Database Sharding:
- Shard orders by user_id (user affinity)
- Shard products by category (hot products in separate shards)
2. Caching Strategy:
- Product details: Redis (1-hour TTL)
- Cart: Redis (7-day TTL)
- Search results: Redis (15-minute TTL)
3. CDN for Static Assets:
- Product images
- CSS/JS bundles
- Category thumbnails
4. Async Processing:
- Order confirmation emails
- Inventory updates
- Analytics events
- Review indexing
Key Takeaways
- Use Redis for cart - Fast, supports TTL, scales horizontally
- ACID for payments - PostgreSQL transactions ensure consistency
- Elasticsearch for search - Fast full-text search with facets
- Kafka for events - Decouple order processing
- Inventory reservation - Prevent overselling during checkout
- Idempotency keys - Prevent duplicate orders on retry
Section 44: Design an Online Bookstore (Amazon Books / Goodreads)
Overview
Design a comprehensive online bookstore with features for browsing, purchasing, reading reviews, creating reading lists, and personalized book recommendations.
Problem Requirements
Functional Requirements:
- Book catalog browsing and search
- Book details, reviews, and ratings
- Purchase and download (for e-books)
- Reading lists and bookshelves
- Book recommendations
- Author pages and following
- Book clubs and discussions
Non-Functional Requirements:
- 50 million users
- 10 million books in catalog
- 1 billion reviews
- 100K concurrent users
- Sub-second search response
- 99.9% availability
- Personalized recommendations
Capacity Estimation:
- Book metadata: 10M books × 5KB = 50 GB
- Book covers: 10M × 200KB = 2 TB
- Reviews: 1B × 500 bytes = 500 GB
- E-books: 1M × 5MB = 5 TB
High-Level Architecture
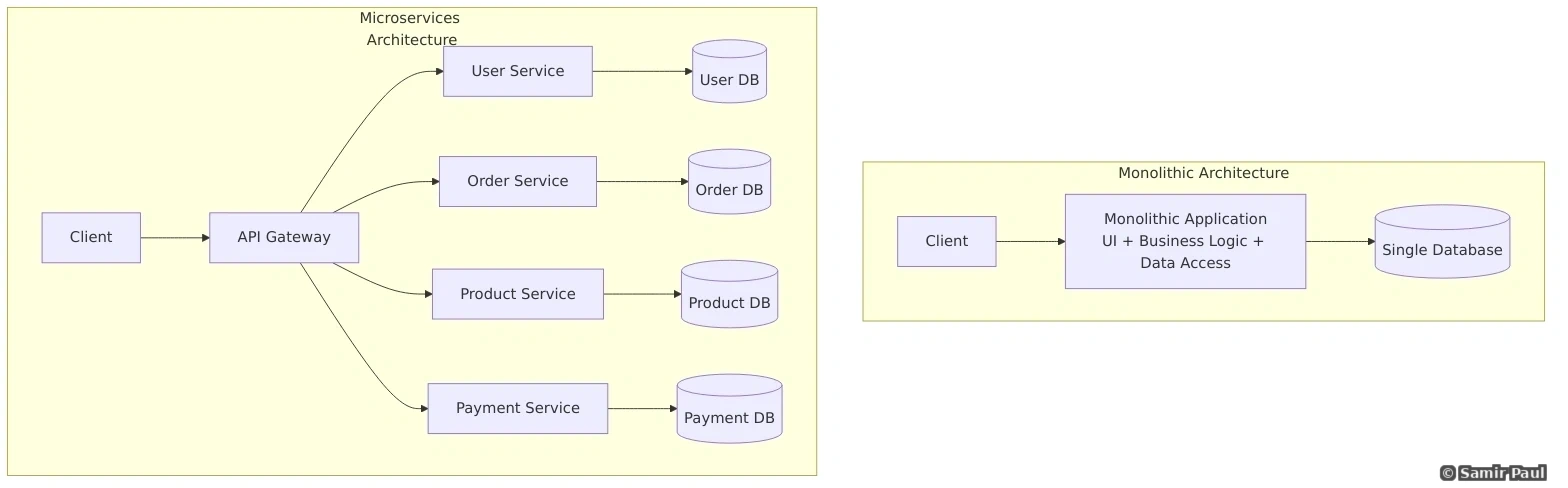
Database Schema
# Book Schema
class Book:
isbn: str (PK)
title: str
subtitle: str
author_ids: UUID[] (FK)
publisher: str
publication_date: date
language: str
pages: int
format: enum('hardcover', 'paperback', 'ebook', 'audiobook')
description: text
genre_ids: UUID[]
price: decimal(10, 2)
avg_rating: float
num_ratings: int
cover_image_url: str
ebook_url: str # S3 link
created_at: timestamp
class Author:
id: UUID (PK)
name: str
bio: text
birth_date: date
nationality: str
photo_url: str
num_followers: int
class Review:
id: UUID (PK)
user_id: UUID (FK)
book_isbn: str (FK)
rating: int (1-5)
review_text: text
num_likes: int
num_comments: int
spoiler: boolean
created_at: timestamp
updated_at: timestamp
class Bookshelf:
id: UUID (PK)
user_id: UUID (FK)
name: str # "Want to Read", "Currently Reading", "Read"
is_public: boolean
created_at: timestamp
class BookshelfItem:
id: UUID (PK)
bookshelf_id: UUID (FK)
book_isbn: str (FK)
added_at: timestamp
reading_progress: int # Percentage read
started_at: timestamp
finished_at: timestampCore Service Implementations
1. Book Service with Multi-Format Support
class BookService:
def __init__(self):
self.db = PostgreSQL()
self.cache = Redis()
self.s3 = S3Client()
def get_book(self, isbn):
"""Get book details with caching."""
cache_key = f"book:{isbn}"
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
book = self.db.query("""
SELECT b.*,
array_agg(DISTINCT a.name) as authors,
array_agg(DISTINCT g.name) as genres
FROM books b
LEFT JOIN book_authors ba ON b.isbn = ba.book_isbn
LEFT JOIN authors a ON ba.author_id = a.id
LEFT JOIN book_genres bg ON b.isbn = bg.book_isbn
LEFT JOIN genres g ON bg.genre_id = g.id
WHERE b.isbn = %s
GROUP BY b.isbn
""", (isbn,))
if book:
book_data = self.serialize(book)
self.cache.setex(cache_key, 3600, json.dumps(book_data))
return book_data
return None
def get_similar_books(self, isbn, limit=10):
"""Find similar books using content-based filtering."""
book = self.get_book(isbn)
if not book:
return []
# Find books with similar genres and authors
similar = self.db.query("""
WITH book_features AS (
SELECT
b.isbn,
array_agg(DISTINCT bg.genre_id) as genres,
array_agg(DISTINCT ba.author_id) as authors
FROM books b
LEFT JOIN book_genres bg ON b.isbn = bg.book_isbn
LEFT JOIN book_authors ba ON b.isbn = ba.book_isbn
WHERE b.isbn = %s
GROUP BY b.isbn
)
SELECT b.isbn, b.title, b.avg_rating,
-- Calculate similarity score
(
-- Genre overlap
cardinality(array_intersect(
(SELECT genres FROM book_features),
array_agg(DISTINCT bg2.genre_id)
)) * 2 +
-- Author overlap
cardinality(array_intersect(
(SELECT authors FROM book_features),
array_agg(DISTINCT ba2.author_id)
)) * 3
) as similarity_score
FROM books b
LEFT JOIN book_genres bg2 ON b.isbn = bg2.book_isbn
LEFT JOIN book_authors ba2 ON b.isbn = ba2.book_isbn
WHERE b.isbn != %s
GROUP BY b.isbn
HAVING similarity_score > 0
ORDER BY similarity_score DESC, b.avg_rating DESC
LIMIT %s
""", (isbn, isbn, limit))
return similar
def download_ebook(self, user_id, isbn):
"""Generate pre-signed URL for e-book download."""
# Verify user owns the book
if not self.verify_purchase(user_id, isbn):
raise UnauthorizedError("User has not purchased this e-book")
book = self.get_book(isbn)
if not book['ebook_url']:
raise NotFoundError("E-book not available for this title")
# Generate pre-signed URL (valid for 1 hour)
download_url = self.s3.generate_presigned_url(
'get_object',
Params={'Bucket': 'ebooks', 'Key': book['ebook_url']},
ExpiresIn=3600
)
# Log download for analytics
self.analytics.track('ebook_downloaded', {
'user_id': user_id,
'isbn': isbn,
'timestamp': datetime.now()
})
return download_url2. Review Service with Cassandra for Scale
from cassandra.cluster import Cluster
class ReviewService:
def __init__(self):
self.cluster = Cluster(['cassandra-node-1', 'cassandra-node-2'])
self.session = self.cluster.connect('bookstore')
self.cache = Redis()
def create_review(self, user_id, book_isbn, rating, review_text, spoiler=False):
"""Create a new book review."""
review_id = uuid.uuid4()
# Insert into Cassandra (denormalized for fast reads)
self.session.execute("""
INSERT INTO reviews_by_book (book_isbn, review_id, user_id, rating, review_text, spoiler, num_likes, created_at)
VALUES (%s, %s, %s, %s, %s, %s, 0, %s)
""", (book_isbn, review_id, user_id, rating, review_text, spoiler, datetime.now()))
self.session.execute("""
INSERT INTO reviews_by_user (user_id, review_id, book_isbn, rating, review_text, created_at)
VALUES (%s, %s, %s, %s, %s, %s)
""", (user_id, review_id, book_isbn, rating, review_text, datetime.now()))
# Update book's average rating (async via Kafka)
self.kafka_producer.send('review-events', {
'event_type': 'review_created',
'book_isbn': book_isbn,
'rating': rating
})
# Invalidate cache
self.cache.delete(f"reviews:book:{book_isbn}")
self.cache.delete(f"book:{book_isbn}")
return review_id
def get_reviews_for_book(self, book_isbn, sort_by='helpful', page=1, page_size=20):
"""Get paginated reviews for a book."""
cache_key = f"reviews:book:{book_isbn}:sort:{sort_by}:page:{page}"
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
# Cassandra query (already sorted by timestamp)
rows = self.session.execute("""
SELECT review_id, user_id, rating, review_text, num_likes, created_at
FROM reviews_by_book
WHERE book_isbn = %s
LIMIT %s
""", (book_isbn, page_size))
reviews = [self.serialize_review(row) for row in rows]
# Sort in application layer if needed
if sort_by == 'helpful':
reviews.sort(key=lambda r: r['num_likes'], reverse=True)
elif sort_by == 'recent':
reviews.sort(key=lambda r: r['created_at'], reverse=True)
# Cache for 5 minutes
self.cache.setex(cache_key, 300, json.dumps(reviews))
return reviews
def like_review(self, review_id, user_id):
"""Like a review (increment counter)."""
# Use lightweight transaction to prevent double-liking
result = self.session.execute("""
UPDATE reviews_by_book
SET num_likes = num_likes + 1
WHERE book_isbn = %s AND review_id = %s
IF NOT EXISTS IN user_likes(%s)
""", (book_isbn, review_id, user_id))
if result.was_applied:
# Record user liked this review
self.session.execute("""
INSERT INTO review_likes (review_id, user_id, created_at)
VALUES (%s, %s, %s)
""", (review_id, user_id, datetime.now()))
return result.was_applied3. Recommendation Engine
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
class RecommendationService:
def __init__(self):
self.db = PostgreSQL()
self.feature_store = Redis()
self.ml_model = self.load_model()
def get_recommendations(self, user_id, num_recommendations=10):
"""Generate personalized book recommendations."""
# 1. Get user's reading history
user_books = self.get_user_books(user_id)
if not user_books:
return self.get_popular_books()
# 2. Hybrid approach: Collaborative + Content-based
collaborative_recs = self.collaborative_filtering(user_id)
content_recs = self.content_based_filtering(user_books)
# 3. Combine with weighted average
combined = self.combine_recommendations(
collaborative_recs,
content_recs,
weights=[0.6, 0.4]
)
# 4. Re-rank with business logic
final_recs = self.rerank(combined, user_id)
return final_recs[:num_recommendations]
def collaborative_filtering(self, user_id):
"""Find similar users and recommend their liked books."""
# Get user embedding from feature store
user_embedding_key = f"user_embedding:{user_id}"
user_embedding = self.feature_store.get(user_embedding_key)
if not user_embedding:
# Generate embedding from user's ratings
user_embedding = self.generate_user_embedding(user_id)
self.feature_store.setex(user_embedding_key, 86400, user_embedding)
user_embedding = np.frombuffer(user_embedding, dtype=np.float32)
# Find similar users (using pre-computed embeddings)
similar_users = self.find_similar_users(user_embedding, top_k=50)
# Get books liked by similar users
recommended_isbns = self.db.query("""
SELECT DISTINCT b.book_isbn, COUNT(*) as score
FROM bookshelf_items b
WHERE b.user_id IN %s
AND b.book_isbn NOT IN (
SELECT book_isbn FROM bookshelf_items WHERE user_id = %s
)
GROUP BY b.book_isbn
ORDER BY score DESC
LIMIT 100
""", (tuple(similar_users), user_id))
return recommended_isbns
def content_based_filtering(self, user_books):
"""Recommend books similar to what user has read."""
# Extract genres and authors from user's books
user_genres = Counter()
user_authors = set()
for book in user_books:
user_genres.update(book['genres'])
user_authors.update(book['authors'])
# Find books matching preferred genres/authors
top_genres = [g for g, _ in user_genres.most_common(5)]
similar_books = self.db.query("""
SELECT DISTINCT b.isbn, b.title,
(
-- Genre match score
cardinality(array_intersect(
ARRAY[%s]::uuid[],
array_agg(bg.genre_id)
)) * 2 +
-- Author match score
CASE WHEN ba.author_id = ANY(%s::uuid[]) THEN 5 ELSE 0 END
) as score
FROM books b
LEFT JOIN book_genres bg ON b.isbn = bg.book_isbn
LEFT JOIN book_authors ba ON b.isbn = ba.book_isbn
WHERE b.isbn NOT IN %s
GROUP BY b.isbn
HAVING score > 0
ORDER BY score DESC, b.avg_rating DESC
LIMIT 100
""", (top_genres, list(user_authors), tuple([b['isbn'] for b in user_books])))
return similar_books
def generate_user_embedding(self, user_id):
"""Generate 128-dim embedding for user based on preferences."""
# Get user's ratings
ratings = self.db.query("""
SELECT book_isbn, rating FROM reviews_by_user WHERE user_id = %s
""", (user_id,))
# Use matrix factorization (SVD) or neural network
# Simplified: weighted average of book embeddings
user_vector = np.zeros(128)
total_weight = 0
for isbn, rating in ratings:
book_embedding = self.get_book_embedding(isbn)
weight = rating / 5.0 # Normalize rating to 0-1
user_vector += book_embedding * weight
total_weight += weight
if total_weight > 0:
user_vector /= total_weight
return user_vector.tobytes()4. Reading List / Bookshelf Management
class BookshelfService:
def __init__(self):
self.db = PostgreSQL()
self.cache = Redis()
def add_to_shelf(self, user_id, book_isbn, shelf_name='want_to_read'):
"""Add book to user's bookshelf."""
# Get or create shelf
shelf = self.db.query("""
INSERT INTO bookshelves (user_id, name)
VALUES (%s, %s)
ON CONFLICT (user_id, name) DO UPDATE SET user_id = user_id
RETURNING id
""", (user_id, shelf_name))
shelf_id = shelf['id']
# Add book to shelf
self.db.execute("""
INSERT INTO bookshelf_items (bookshelf_id, book_isbn, added_at)
VALUES (%s, %s, NOW())
ON CONFLICT (bookshelf_id, book_isbn) DO NOTHING
""", (shelf_id, book_isbn))
# Invalidate cache
self.cache.delete(f"bookshelf:{user_id}:{shelf_name}")
return True
def update_reading_progress(self, user_id, book_isbn, progress_percentage):
"""Update reading progress for a book."""
self.db.execute("""
UPDATE bookshelf_items
SET reading_progress = %s,
started_at = COALESCE(started_at, NOW()),
finished_at = CASE WHEN %s >= 100 THEN NOW() ELSE NULL END
WHERE bookshelf_id IN (
SELECT id FROM bookshelves WHERE user_id = %s
) AND book_isbn = %s
""", (progress_percentage, progress_percentage, user_id, book_isbn))
# Move to "Read" shelf if finished
if progress_percentage >= 100:
self.add_to_shelf(user_id, book_isbn, 'read')
def get_reading_stats(self, user_id):
"""Get user's reading statistics."""
stats = self.db.query("""
SELECT
COUNT(CASE WHEN finished_at IS NOT NULL THEN 1 END) as books_read,
COUNT(CASE WHEN reading_progress > 0 AND reading_progress < 100 THEN 1 END) as currently_reading,
COUNT(CASE WHEN reading_progress = 0 THEN 1 END) as want_to_read,
AVG(CASE WHEN finished_at IS NOT NULL
THEN EXTRACT(EPOCH FROM (finished_at - started_at)) / 86400
END) as avg_days_to_finish
FROM bookshelf_items bi
JOIN bookshelves bs ON bi.bookshelf_id = bs.id
WHERE bs.user_id = %s
""", (user_id,))
return statsScalability Optimizations
1. Caching Strategy:
- Book details: 1-hour TTL (rarely changes)
- Reviews: 5-minute TTL (frequently updated)
- User embeddings: 24-hour TTL
- Popular books: 1-hour TTL
2. Database Sharding:
- Books: Shard by ISBN prefix
- Reviews: Shard by book_isbn (Cassandra partition key)
- Users: Shard by user_id
3. Search Optimization:
- Elasticsearch with custom analyzers for book titles
- Autocomplete with edge n-grams
- Faceted search (genre, author, rating, price)
4. ML Model Serving:
- TensorFlow Serving for real-time recommendations
- Batch processing for embedding generation (nightly)
- A/B testing framework for recommendation algorithms
Key Takeaways
- Cassandra for reviews - Write-heavy, needs horizontal scaling
- Hybrid recommendations - Combine collaborative + content-based
- User embeddings - Cache in Redis for fast lookups
- Pre-signed URLs - Secure e-book downloads without exposing S3
- Reading progress tracking - Engages users, improves recommendations
- Denormalization - Store avg_rating on book to avoid aggregation queries
Section 45: Design an Online Multiplayer Game Backend (Real-Time)
Overview
Design a scalable backend for a real-time multiplayer game (like Fortnite, Among Us, or League of Legends) supporting matchmaking, game state synchronization, chat, leaderboards, and anti-cheat.
Problem Requirements
Functional Requirements:
- Player authentication and profiles
- Matchmaking system
- Real-time game state synchronization
- In-game chat
- Leaderboards and rankings
- Match history
- Anti-cheat detection
- Game replay system
Non-Functional Requirements:
- 10 million daily active users
- 500K concurrent players
- Sub-50ms latency for game actions
- 99.99% uptime during matches
- Support 100-player battle royale matches
- Global distribution (multiple regions)
Capacity Estimation:
- 500K concurrent / 100 players per match = 5,000 concurrent matches
- Game state updates: 20 updates/sec × 100 players × 5,000 matches = 10M updates/sec
- Bandwidth: 10M updates × 200 bytes = 2 GB/sec
High-Level Architecture
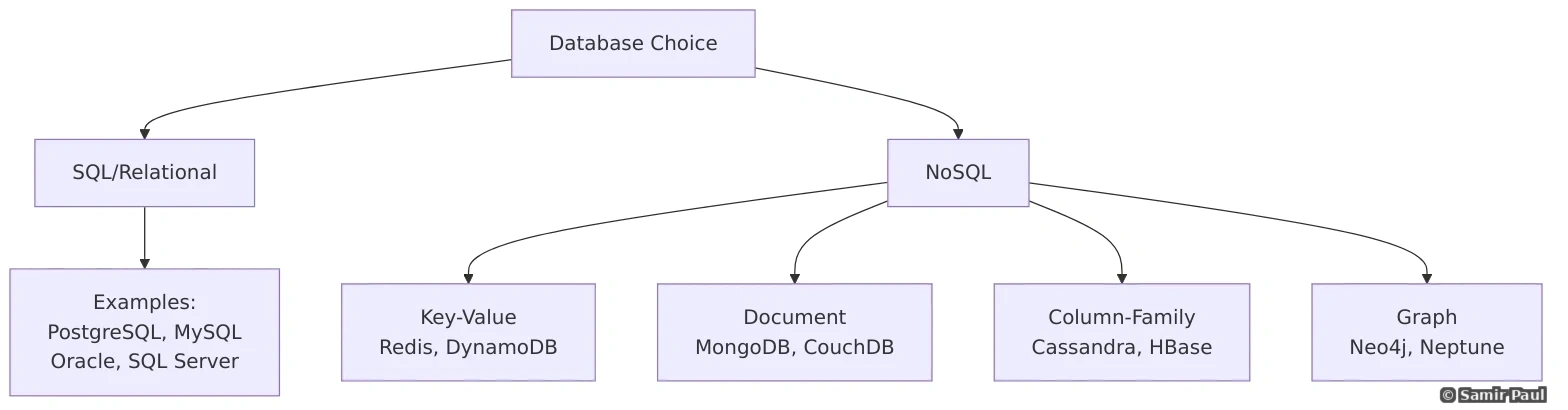
Detailed Game Server Architecture
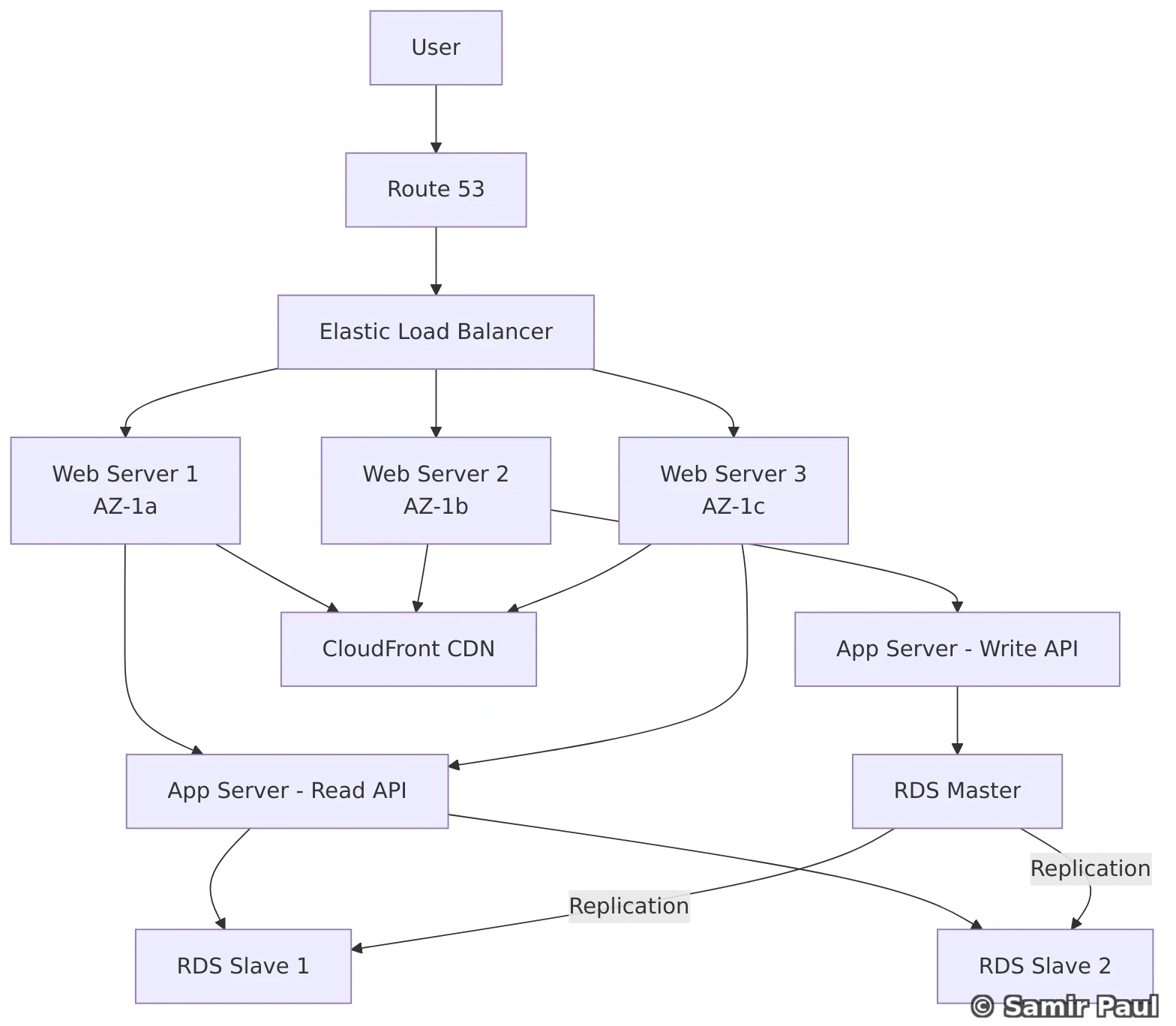
Core Service Implementations
1. Matchmaking Service
import asyncio
import redis
from dataclasses import dataclass
from typing import List
import heapq
@dataclass
class Player:
player_id: str
skill_rating: int # ELO or MMR
region: str
queue_time: float
preferred_roles: List[str]
class MatchmakingService:
def __init__(self):
self.redis = redis.Redis(host='localhost', port=6379)
self.queue_key_prefix = "matchmaking:queue:"
self.min_players = 10 # For 10-player matches
self.max_skill_diff = 200 # Maximum MMR difference
async def add_to_queue(self, player: Player):
"""Add player to matchmaking queue."""
queue_key = f"{self.queue_key_prefix}{player.region}"
# Add to Redis sorted set (score = skill_rating)
self.redis.zadd(queue_key, {
json.dumps({
'player_id': player.player_id,
'skill_rating': player.skill_rating,
'queue_time': time.time(),
'preferred_roles': player.preferred_roles
}): player.skill_rating
})
# Start matchmaking check
asyncio.create_task(self.find_matches(player.region))
async def find_matches(self, region):
"""Find suitable matches from queue."""
queue_key = f"{self.queue_key_prefix}{region}"
# Get all players in queue
players_data = self.redis.zrange(queue_key, 0, -1, withscores=True)
players = [json.loads(p[0]) for p in players_data]
if len(players) < self.min_players:
return # Not enough players
# Sort by skill rating
players.sort(key=lambda p: p['skill_rating'])
# Try to create balanced matches
matches = []
current_match = []
for player in players:
if not current_match:
current_match.append(player)
continue
# Check skill difference
avg_skill = sum(p['skill_rating'] for p in current_match) / len(current_match)
skill_diff = abs(player['skill_rating'] - avg_skill)
# Check queue time (expand search range over time)
queue_time = time.time() - player['queue_time']
max_diff = self.max_skill_diff + (queue_time * 10) # +10 MMR per second
if skill_diff <= max_diff:
current_match.append(player)
if len(current_match) == self.min_players:
matches.append(current_match)
current_match = []
# Create game sessions for matches
for match in matches:
await self.create_game_session(match, region)
# Remove matched players from queue
for player in match:
self.redis.zrem(queue_key, json.dumps(player))
async def create_game_session(self, players: List[dict], region: str):
"""Allocate game server and start match."""
# Find available game server in region
game_server = await self.allocate_game_server(region)
# Create game session
session_id = str(uuid.uuid4())
# Store session info in Redis
self.redis.hmset(f"game_session:{session_id}", {
'session_id': session_id,
'server_ip': game_server['ip'],
'server_port': game_server['port'],
'region': region,
'players': json.dumps([p['player_id'] for p in players]),
'status': 'waiting',
'created_at': time.time()
})
# Notify players (via WebSocket or push notification)
for player in players:
await self.notify_player(player['player_id'], {
'event': 'match_found',
'session_id': session_id,
'server_ip': game_server['ip'],
'server_port': game_server['port']
})
return session_id
async def allocate_game_server(self, region):
"""Find or spin up game server instance."""
# Check for idle servers
idle_servers_key = f"game_servers:idle:{region}"
server_data = self.redis.lpop(idle_servers_key)
if server_data:
return json.loads(server_data)
# No idle servers - request new instance from orchestrator
new_server = await self.orchestrator.provision_server(region)
return new_server2. Real-Time Game Server
import asyncio
import websockets
from dataclasses import dataclass
from typing import Dict, Set
import numpy as np
@dataclass
class GameState:
players: Dict[str, 'PlayerState']
projectiles: List['Projectile']
game_time: float
tick_number: int
@dataclass
class PlayerState:
player_id: str
position: np.ndarray # [x, y, z]
velocity: np.ndarray
rotation: float
health: int
score: int
is_alive: bool
class GameServer:
def __init__(self, session_id, max_players=100):
self.session_id = session_id
self.max_players = max_players
self.tick_rate = 20 # 20 updates per second (50ms tick)
self.tick_duration = 1.0 / self.tick_rate
self.game_state = GameState(
players={},
projectiles=[],
game_time=0.0,
tick_number=0
)
self.connections: Dict[str, websockets.WebSocketServerProtocol] = {}
self.input_buffer: Dict[str, List] = {} # Player inputs per tick
async def start_server(self, host='0.0.0.0', port=8765):
"""Start WebSocket server and game loop."""
# Start WebSocket server
server = await websockets.serve(self.handle_connection, host, port)
# Start game loop
asyncio.create_task(self.game_loop())
await server.wait_closed()
async def handle_connection(self, websocket, path):
"""Handle player WebSocket connection."""
try:
# Authenticate player
auth_msg = await websocket.recv()
auth_data = json.loads(auth_msg)
player_id = auth_data['player_id']
session_token = auth_data['session_token']
if not await self.verify_session(player_id, session_token):
await websocket.close(1008, "Authentication failed")
return
# Add player to game
self.connections[player_id] = websocket
self.spawn_player(player_id)
# Listen for player inputs
async for message in websocket:
await self.handle_player_input(player_id, message)
except websockets.exceptions.ConnectionClosed:
# Player disconnected
await self.handle_disconnect(player_id)
async def game_loop(self):
"""Main game loop running at fixed tick rate."""
last_tick = time.time()
while True:
current_time = time.time()
delta_time = current_time - last_tick
if delta_time >= self.tick_duration:
# Process game tick
await self.process_tick(delta_time)
last_tick = current_time
else:
# Sleep until next tick
await asyncio.sleep(self.tick_duration - delta_time)
async def process_tick(self, delta_time):
"""Process one game tick."""
self.game_state.tick_number += 1
self.game_state.game_time += delta_time
# 1. Process player inputs
for player_id, inputs in self.input_buffer.items():
for input_data in inputs:
self.apply_player_input(player_id, input_data)
self.input_buffer.clear()
# 2. Update physics
self.update_physics(delta_time)
# 3. Check collisions
self.check_collisions()
# 4. Update game logic (scoring, win conditions, etc.)
self.update_game_logic()
# 5. Broadcast state to all players
await self.broadcast_state()
# 6. Check for match end
if self.check_match_end():
await self.end_match()
async def handle_player_input(self, player_id, message):
"""Handle player input message."""
input_data = json.loads(message)
# Validate input timestamp (prevent cheating)
server_time = self.game_state.game_time
client_time = input_data.get('timestamp', 0)
if abs(server_time - client_time) > 0.5: # 500ms tolerance
# Potential lag or time manipulation
await self.flag_suspicious_activity(player_id, "timestamp_mismatch")
return
# Buffer input for next tick
if player_id not in self.input_buffer:
self.input_buffer[player_id] = []
self.input_buffer[player_id].append(input_data)
def apply_player_input(self, player_id, input_data):
"""Apply player input to game state."""
if player_id not in self.game_state.players:
return
player = self.game_state.players[player_id]
# Movement
if 'move' in input_data:
direction = np.array(input_data['move']) # [x, y]
speed = 5.0 # units per second
player.velocity = direction * speed
# Rotation
if 'rotation' in input_data:
player.rotation = input_data['rotation']
# Actions (shoot, use ability, etc.)
if 'action' in input_data:
action = input_data['action']
if action == 'shoot':
self.create_projectile(player)
elif action == 'use_ability':
self.use_ability(player, input_data.get('ability_id'))
def update_physics(self, delta_time):
"""Update positions based on velocities."""
for player in self.game_state.players.values():
if player.is_alive:
player.position += player.velocity * delta_time
# Apply friction
player.velocity *= 0.9
# Clamp to map bounds
player.position = np.clip(player.position, 0, 1000)
# Update projectiles
for projectile in self.game_state.projectiles:
projectile.position += projectile.velocity * delta_time
def check_collisions(self):
"""Check for collisions between entities."""
# Player vs Projectile collisions
for projectile in self.game_state.projectiles[:]:
for player in self.game_state.players.values():
if not player.is_alive:
continue
# Skip if projectile owner is the player
if projectile.owner_id == player.player_id:
continue
# Simple distance-based collision
distance = np.linalg.norm(player.position - projectile.position)
if distance < 2.0: # Collision radius
# Apply damage
player.health -= projectile.damage
if player.health <= 0:
player.is_alive = False
self.handle_player_death(player, projectile.owner_id)
# Remove projectile
self.game_state.projectiles.remove(projectile)
break
async def broadcast_state(self):
"""Send game state to all connected players."""
# Use delta compression - only send changes
state_update = {
'tick': self.game_state.tick_number,
'time': self.game_state.game_time,
'players': {}
}
# Only include alive players and their essential data
for player_id, player in self.game_state.players.items():
if player.is_alive:
state_update['players'][player_id] = {
'pos': player.position.tolist(),
'rot': player.rotation,
'hp': player.health
}
# Serialize and send
message = json.dumps(state_update)
# Broadcast to all players
disconnected = []
for player_id, websocket in self.connections.items():
try:
await websocket.send(message)
except websockets.exceptions.ConnectionClosed:
disconnected.append(player_id)
# Clean up disconnected players
for player_id in disconnected:
await self.handle_disconnect(player_id)
def handle_player_death(self, player, killer_id):
"""Handle player elimination."""
# Update scores
if killer_id in self.game_state.players:
self.game_state.players[killer_id].score += 100
# Broadcast death event
asyncio.create_task(self.broadcast_event({
'event': 'player_eliminated',
'player_id': player.player_id,
'killer_id': killer_id
}))3. Leaderboard Service
class LeaderboardService:
def __init__(self):
self.redis = redis.Redis(host='localhost', port=6379)
self.cassandra = CassandraCluster(['cassandra-node'])
def update_player_score(self, player_id, score, match_id):
"""Update player's score after match."""
# Update global leaderboard (Redis Sorted Set)
self.redis.zincrby('leaderboard:global', score, player_id)
# Update regional leaderboard
player_region = self.get_player_region(player_id)
self.redis.zincrby(f'leaderboard:region:{player_region}', score, player_id)
# Store in Cassandra for history
self.cassandra.execute("""
INSERT INTO player_scores (player_id, match_id, score, timestamp)
VALUES (%s, %s, %s, %s)
""", (player_id, match_id, score, datetime.now()))
def get_top_players(self, limit=100, region=None):
"""Get top players on leaderboard."""
key = 'leaderboard:global' if not region else f'leaderboard:region:{region}'
# Get top players (descending order)
top_players = self.redis.zrevrange(key, 0, limit-1, withscores=True)
# Format response
leaderboard = []
for rank, (player_id, score) in enumerate(top_players, 1):
player_data = self.get_player_profile(player_id)
leaderboard.append({
'rank': rank,
'player_id': player_id,
'username': player_data['username'],
'score': int(score),
'avatar': player_data['avatar_url']
})
return leaderboard
def get_player_rank(self, player_id):
"""Get player's current rank."""
rank = self.redis.zrevrank('leaderboard:global', player_id)
return rank + 1 if rank is not None else None4. Anti-Cheat Service
import numpy as np
from sklearn.ensemble import IsolationForest
class AntiCheatService:
def __init__(self):
self.redis = redis.Redis()
self.ml_model = IsolationForest(contamination=0.01)
self.flags_threshold = 3 # Flags before ban
async def analyze_player_behavior(self, player_id, match_data):
"""Analyze player behavior for cheating patterns."""
features = self.extract_features(match_data)
# Check for anomalies
is_anomaly = self.ml_model.predict([features])[0] == -1
if is_anomaly:
await self.flag_player(player_id, "behavioral_anomaly", features)
# Rule-based checks
if self.check_impossible_movement(match_data):
await self.flag_player(player_id, "impossible_movement")
if self.check_perfect_accuracy(match_data):
await self.flag_player(player_id, "suspicious_accuracy")
if self.check_wallhacks(match_data):
await self.flag_player(player_id, "wall_hacks")
def extract_features(self, match_data):
"""Extract features for ML model."""
return np.array([
match_data['kills_per_minute'],
match_data['accuracy'],
match_data['headshot_percentage'],
match_data['reaction_time_avg'],
match_data['movement_speed_variance']
])
async def flag_player(self, player_id, reason, details=None):
"""Flag player for suspicious activity."""
flag_count = self.redis.incr(f"anticheat:flags:{player_id}")
# Log flag
await self.log_flag(player_id, reason, details)
# Auto-ban if threshold reached
if flag_count >= self.flags_threshold:
await self.ban_player(player_id, reason="multiple_flags")Scalability Optimizations
1. Regional Game Servers:
- Deploy servers in multiple regions (US, EU, Asia)
- Route players to nearest region for low latency
2. Game Server Fleet Management:
- Kubernetes for orchestration
- Auto-scaling based on queue size
- Warm pool of idle servers
3. State Synchronization:
- UDP for low-latency game state (tolerate packet loss)
- TCP for critical actions (weapon purchases, match results)
4. Database Strategy:
- Cassandra for match history (write-heavy)
- Redis for real-time leaderboards
- PostgreSQL for player profiles
Key Takeaways
- Fixed tick rate - Ensures consistent gameplay across clients
- Client-side prediction - Reduces perceived latency
- Server reconciliation - Prevents cheating with authoritative server
- UDP for game state - Lower latency than TCP
- Regional distribution - Critical for low-latency global gameplay
- Anti-cheat ML - Detect anomalous behavior patterns
- Redis sorted sets - Perfect for leaderboards
Section 46: Design a Collaborative Document Editor (Google Docs)
Overview
Design a real-time collaborative document editor where multiple users can simultaneously edit the same document with conflict-free synchronization, version history, comments, and rich text formatting.
Problem Requirements
Functional Requirements:
- Real-time collaborative editing
- Rich text formatting (bold, italic, headings, lists, etc.)
- Document sharing and permissions
- Comments and suggestions
- Version history
- Auto-save
- Offline editing with sync
Non-Functional Requirements:
- 100 million users
- 50 million documents
- Support 100 concurrent editors per document
- Sub-100ms latency for edits
- 99.99% availability
- Conflict-free synchronization
Capacity Estimation:
- Storage: 50M documents × 100KB average = 5 TB
- Versions: 50M documents × 10 versions × 100KB = 50 TB
- Concurrent editors: 100K active documents × 10 editors = 1M WebSocket connections
High-Level Architecture
CRDT (Conflict-free Replicated Data Type) Architecture
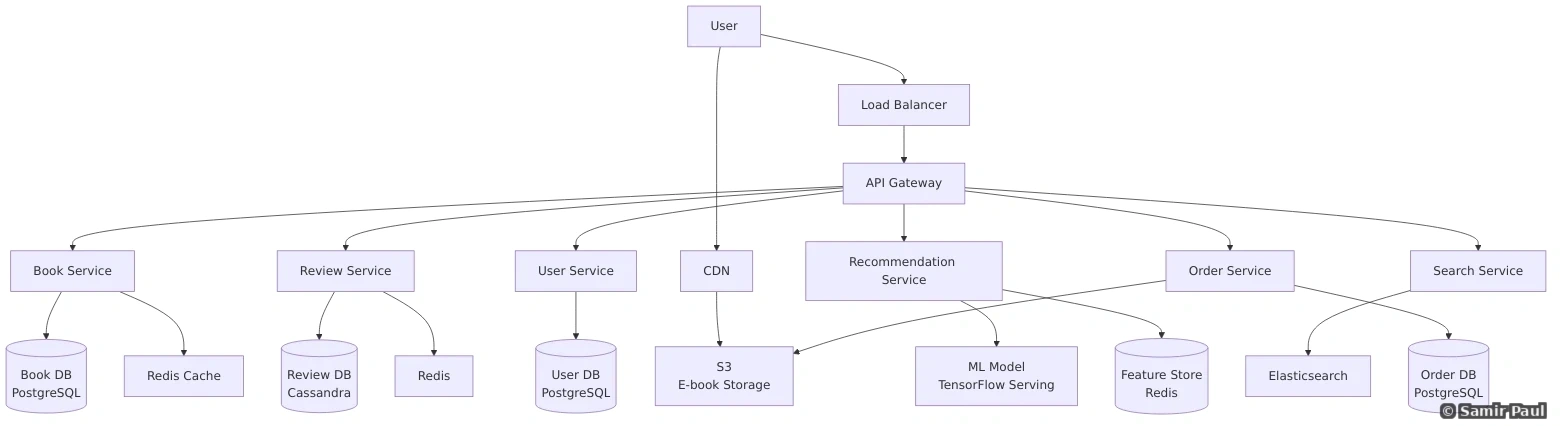
Core Service Implementations
1. Operational Transformation (OT) / CRDT for Sync
from dataclasses import dataclass
from typing import List, Tuple
import uuid
@dataclass
class Character:
char: str
char_id: str # Unique ID for each character
site_id: str # Client/user who created it
position: List[int] # Fractional indexing position
class CRDTDocument:
"""
CRDT-based document using fractional indexing.
Enables conflict-free concurrent editing.
"""
def __init__(self, doc_id):
self.doc_id = doc_id
self.characters: List[Character] = []
self.tombstones = set() # Deleted character IDs
self.version = 0
def local_insert(self, char, position, site_id):
"""Insert character at position (local operation)."""
# Generate unique fractional position
frac_pos = self.generate_position(position)
char_id = f"{site_id}:{uuid.uuid4()}"
character = Character(
char=char,
char_id=char_id,
site_id=site_id,
position=frac_pos
)
# Insert into sorted array
self.characters.insert(position, character)
self.version += 1
# Return operation to broadcast
return {
'type': 'insert',
'char_id': char_id,
'char': char,
'position': frac_pos,
'site_id': site_id,
'version': self.version
}
def local_delete(self, position, site_id):
"""Delete character at position (local operation)."""
if position >= len(self.characters):
return None
character = self.characters[position]
char_id = character.char_id
# Mark as tombstone (don't actually delete for consistency)
self.tombstones.add(char_id)
self.characters.pop(position)
self.version += 1
return {
'type': 'delete',
'char_id': char_id,
'site_id': site_id,
'version': self.version
}
def remote_insert(self, operation):
"""Apply remote insert operation."""
char_id = operation['char_id']
# Check if already applied (idempotency)
if any(c.char_id == char_id for c in self.characters):
return False
# Check if previously deleted
if char_id in self.tombstones:
return False
character = Character(
char=operation['char'],
char_id=char_id,
site_id=operation['site_id'],
position=operation['position']
)
# Find insertion point based on fractional position
insert_idx = self.find_insert_position(character.position)
self.characters.insert(insert_idx, character)
return True
def remote_delete(self, operation):
"""Apply remote delete operation."""
char_id = operation['char_id']
# Find and remove character
for i, char in enumerate(self.characters):
if char.char_id == char_id:
self.characters.pop(i)
self.tombstones.add(char_id)
return True
# Already deleted
self.tombstones.add(char_id)
return False
def generate_position(self, index):
"""Generate fractional position for insertion."""
if index == 0:
if not self.characters:
return [0.5]
else:
prev_pos = [0.0]
next_pos = self.characters[0].position
elif index >= len(self.characters):
prev_pos = self.characters[-1].position
next_pos = [1.0]
else:
prev_pos = self.characters[index - 1].position
next_pos = self.characters[index].position
# Generate position between prev and next
return self.between(prev_pos, next_pos)
def between(self, prev, next):
"""Generate position between two fractional positions."""
# Simplified fractional indexing
if len(prev) < len(next):
prev = prev + [0] * (len(next) - len(prev))
elif len(next) < len(prev):
next = next + [0] * (len(prev) - len(next))
result = []
for i in range(len(prev)):
if prev[i] < next[i]:
result.append((prev[i] + next[i]) / 2)
break
result.append(prev[i])
return result
def to_string(self):
"""Convert document to string."""
return ''.join(char.char for char in self.characters)
def find_insert_position(self, position):
"""Binary search for insertion position."""
left, right = 0, len(self.characters)
while left < right:
mid = (left + right) // 2
if self.characters[mid].position < position:
left = mid + 1
else:
right = mid
return left2. Collaboration Service
import asyncio
import websockets
from collections import defaultdict
class CollaborationService:
def __init__(self):
self.documents: Dict[str, CRDTDocument] = {}
self.connections: Dict[str, Set[websockets.WebSocketServerProtocol]] = defaultdict(set)
self.user_cursors: Dict[str, Dict] = defaultdict(dict) # doc_id -> {user_id: cursor_pos}
self.redis = redis.Redis()
async def handle_connection(self, websocket, path):
"""Handle WebSocket connection for collaborative editing."""
doc_id = None
user_id = None
try:
# Authenticate and get document ID
auth_msg = await websocket.recv()
auth_data = json.loads(auth_msg)
doc_id = auth_data['doc_id']
user_id = auth_data['user_id']
token = auth_data['token']
# Verify permissions
if not await self.verify_permission(user_id, doc_id, token):
await websocket.close(1008, "Unauthorized")
return
# Add to document's connection pool
self.connections[doc_id].add(websocket)
# Load document if not in memory
if doc_id not in self.documents:
await self.load_document(doc_id)
# Send current document state
await websocket.send(json.dumps({
'type': 'init',
'content': self.documents[doc_id].to_string(),
'version': self.documents[doc_id].version,
'active_users': await self.get_active_users(doc_id)
}))
# Broadcast user joined
await self.broadcast_to_document(doc_id, {
'type': 'user_joined',
'user_id': user_id,
'username': await self.get_username(user_id)
}, exclude=websocket)
# Handle incoming operations
async for message in websocket:
await self.handle_operation(doc_id, user_id, message, websocket)
except websockets.exceptions.ConnectionClosed:
pass
finally:
# Clean up on disconnect
if doc_id and user_id:
self.connections[doc_id].discard(websocket)
if doc_id in self.user_cursors:
self.user_cursors[doc_id].pop(user_id, None)
await self.broadcast_to_document(doc_id, {
'type': 'user_left',
'user_id': user_id
})
async def handle_operation(self, doc_id, user_id, message, sender_ws):
"""Handle edit operation from client."""
operation = json.loads(message)
op_type = operation['type']
doc = self.documents[doc_id]
if op_type == 'insert':
# Apply operation to CRDT
op = doc.remote_insert(operation)
if op:
# Broadcast to other users
await self.broadcast_to_document(doc_id, operation, exclude=sender_ws)
# Save to Redis for persistence
await self.save_operation(doc_id, operation)
elif op_type == 'delete':
op = doc.remote_delete(operation)
if op:
await self.broadcast_to_document(doc_id, operation, exclude=sender_ws)
await self.save_operation(doc_id, operation)
elif op_type == 'cursor':
# Update cursor position
self.user_cursors[doc_id][user_id] = {
'position': operation['position'],
'user_id': user_id
}
# Broadcast cursor update
await self.broadcast_to_document(doc_id, {
'type': 'cursor_update',
'user_id': user_id,
'position': operation['position']
}, exclude=sender_ws)
elif op_type == 'format':
# Handle formatting (bold, italic, etc.)
await self.broadcast_to_document(doc_id, operation, exclude=sender_ws)
await self.save_operation(doc_id, operation)
async def broadcast_to_document(self, doc_id, message, exclude=None):
"""Broadcast message to all users editing the document."""
if doc_id not in self.connections:
return
message_json = json.dumps(message)
disconnected = []
for ws in self.connections[doc_id]:
if ws == exclude:
continue
try:
await ws.send(message_json)
except websockets.exceptions.ConnectionClosed:
disconnected.append(ws)
# Clean up disconnected clients
for ws in disconnected:
self.connections[doc_id].discard(ws)
async def save_operation(self, doc_id, operation):
"""Save operation to Redis for crash recovery."""
key = f"doc_ops:{doc_id}"
self.redis.rpush(key, json.dumps(operation))
self.redis.expire(key, 3600) # Keep for 1 hour
# Trigger async save to database
asyncio.create_task(self.persist_to_db(doc_id))3. Document Service
class DocumentService:
def __init__(self):
self.mongo = MongoClient('mongodb://localhost:27017/')
self.db = self.mongo['docs_db']
self.cache = redis.Redis()
self.s3 = S3Client()
def create_document(self, user_id, title, content=""):
"""Create new document."""
doc_id = str(uuid.uuid4())
doc = {
'_id': doc_id,
'title': title,
'content': content,
'owner_id': user_id,
'created_at': datetime.now(),
'updated_at': datetime.now(),
'version': 1,
'collaborators': [user_id]
}
self.db.documents.insert_one(doc)
# Set default permissions
self.permission_service.set_permission(doc_id, user_id, 'owner')
return doc_id
def get_document(self, doc_id):
"""Retrieve document with caching."""
# Try cache first
cache_key = f"doc:{doc_id}"
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
# Fetch from MongoDB
doc = self.db.documents.find_one({'_id': doc_id})
if doc:
doc['_id'] = str(doc['_id'])
self.cache.setex(cache_key, 300, json.dumps(doc))
return doc
return None
def save_document(self, doc_id, content):
"""Save document content (debounced auto-save)."""
self.db.documents.update_one(
{'_id': doc_id},
{
'$set': {
'content': content,
'updated_at': datetime.now()
},
'$inc': {'version': 1}
}
)
# Invalidate cache
self.cache.delete(f"doc:{doc_id}")
# Create version snapshot
asyncio.create_task(self.create_version_snapshot(doc_id, content))
async def create_version_snapshot(self, doc_id, content):
"""Create version snapshot for history."""
doc = self.get_document(doc_id)
version = {
'doc_id': doc_id,
'version': doc['version'],
'content': content,
'created_at': datetime.now(),
'created_by': doc['owner_id']
}
# Store in S3 for cost efficiency
s3_key = f"versions/{doc_id}/v{doc['version']}.json"
self.s3.put_object(
Bucket='document-versions',
Key=s3_key,
Body=json.dumps(version)
)
# Store metadata in PostgreSQL
self.version_db.execute("""
INSERT INTO document_versions (doc_id, version, s3_key, created_at)
VALUES (%s, %s, %s, %s)
""", (doc_id, doc['version'], s3_key, datetime.now()))
def get_version_history(self, doc_id, limit=50):
"""Get version history for document."""
versions = self.version_db.query("""
SELECT version, created_at, created_by
FROM document_versions
WHERE doc_id = %s
ORDER BY version DESC
LIMIT %s
""", (doc_id, limit))
return versions
def restore_version(self, doc_id, version):
"""Restore document to specific version."""
# Get version from S3
s3_key = f"versions/{doc_id}/v{version}.json"
version_data = self.s3.get_object(Bucket='document-versions', Key=s3_key)
version_content = json.loads(version_data['Body'].read())
# Update current document
self.save_document(doc_id, version_content['content'])
return version_content4. Permission Service
class PermissionService:
def __init__(self):
self.db = PostgreSQL()
def set_permission(self, doc_id, user_id, role):
"""Set user permission for document."""
self.db.execute("""
INSERT INTO document_permissions (doc_id, user_id, role, granted_at)
VALUES (%s, %s, %s, NOW())
ON CONFLICT (doc_id, user_id) DO UPDATE SET role = %s
""", (doc_id, user_id, role, role))
def check_permission(self, user_id, doc_id, required_permission):
"""Check if user has permission."""
result = self.db.query("""
SELECT role FROM document_permissions
WHERE doc_id = %s AND user_id = %s
""", (doc_id, user_id))
if not result:
return False
role = result['role']
# Permission hierarchy: owner > editor > commenter > viewer
permissions = {
'owner': ['read', 'write', 'share', 'delete'],
'editor': ['read', 'write', 'comment'],
'commenter': ['read', 'comment'],
'viewer': ['read']
}
return required_permission in permissions.get(role, [])Client-Side Implementation (JavaScript)
class CollaborativeEditor {
constructor(docId, userId) {
this.docId = docId;
this.userId = userId;
this.ws = null;
this.crdt = new CRDTDocument(docId);
this.editor = document.getElementById('editor');
this.connect();
}
connect() {
this.ws = new WebSocket(`wss://api.docs.com/ws`);
this.ws.onopen = () => {
// Authenticate
this.ws.send(JSON.stringify({
doc_id: this.docId,
user_id: this.userId,
token: localStorage.getItem('auth_token')
}));
};
this.ws.onmessage = (event) => {
const message = JSON.parse(event.data);
this.handleMessage(message);
};
// Listen for local edits
this.editor.addEventListener('input', (e) => {
this.handleLocalEdit(e);
});
}
handleLocalEdit(event) {
const operation = this.crdt.local_insert(
event.data,
this.editor.selectionStart,
this.userId
);
// Send to server
this.ws.send(JSON.stringify(operation));
// Update UI optimistically
// (already done by browser)
}
handleMessage(message) {
if (message.type === 'insert') {
// Apply remote insert
if (this.crdt.remote_insert(message)) {
// Update editor content
this.updateEditor();
}
} else if (message.type === 'delete') {
if (this.crdt.remote_delete(message)) {
this.updateEditor();
}
} else if (message.type === 'cursor_update') {
// Show other user's cursor
this.showRemoteCursor(message.user_id, message.position);
}
}
updateEditor() {
const currentCursor = this.editor.selectionStart;
this.editor.value = this.crdt.to_string();
// Restore cursor position
this.editor.setSelectionRange(currentCursor, currentCursor);
}
}Scalability Optimizations
1. Connection Pooling:
- WebSocket gateway with connection pooling
- Multiple servers behind load balancer with sticky sessions
2. Document Sharding:
- Shard documents by doc_id
- Co-locate related data (document + operations)
3. Caching:
- Recent documents in Redis
- Version snapshots in S3 (cold storage)
4. Compression:
- Compress operations in transit
- Store compressed versions
Key Takeaways
- CRDT for conflict resolution - Guarantees eventual consistency
- Fractional indexing - Enables efficient position tracking
- WebSockets for real-time - Bi-directional communication
- Debounced auto-save - Reduce database writes
- Version snapshots - S3 for cost-efficient storage
- Cursor broadcasting - Enhance collaboration awareness
- Permission hierarchy - Fine-grained access control
Section 47: Design an Online Food Delivery System (Uber Eats / DoorDash)
Overview
Design a scalable food delivery platform connecting restaurants, delivery partners, and customers with real-time order tracking, optimized delivery routing, and dynamic pricing.
Problem Requirements
Functional Requirements:
- Restaurant browsing and menu search
- Order placement and tracking
- Real-time delivery tracking
- Payment processing
- Ratings and reviews
- Push notifications
- Delivery optimization
Non-Functional Requirements:
- 50 million users
- 500K restaurants
- 100K concurrent orders
- Sub-second search latency
- Real-time location tracking with < 5-second updates
- 99.9% availability
- Support 50 geographic regions
Capacity Estimation:
- 100K concurrent orders × 50 states = 2M orders/day
- Each order: Order details (1KB) + Location data (500B) = 1.5KB
- 2M orders × 1.5KB × 30 days = 90 GB/month (metadata)
- Location updates: 100K active deliveries × 1 update/5sec = 20K updates/sec
High-Level Architecture
Detailed Location & Delivery Service Architecture

Core Service Implementations
1. Order Service
from enum import Enum
from datetime import datetime, timedelta
class OrderStatus(Enum):
PENDING = "pending"
CONFIRMED = "confirmed"
PREPARING = "preparing"
READY = "ready"
PICKED_UP = "picked_up"
IN_TRANSIT = "in_transit"
DELIVERED = "delivered"
CANCELLED = "cancelled"
class OrderService:
def __init__(self):
self.db = PostgreSQL()
self.cache = redis.Redis()
self.kafka_producer = KafkaProducer()
self.payment_service = PaymentService()
def create_order(self, customer_id, restaurant_id, items, delivery_address):
"""Create new order."""
order_id = str(uuid.uuid4())
# Calculate order total
total = self.calculate_total(restaurant_id, items)
# Create order in database
order = {
'id': order_id,
'customer_id': customer_id,
'restaurant_id': restaurant_id,
'items': items,
'status': OrderStatus.PENDING.value,
'subtotal': total['subtotal'],
'tax': total['tax'],
'delivery_fee': total['delivery_fee'],
'total': total['total'],
'delivery_address': delivery_address,
'created_at': datetime.now(),
'estimated_delivery': datetime.now() + timedelta(minutes=45)
}
self.db.execute("""
INSERT INTO orders (id, customer_id, restaurant_id, items, total, status, created_at)
VALUES (%s, %s, %s, %s, %s, %s, %s)
""", (order_id, customer_id, restaurant_id, json.dumps(items),
total['total'], OrderStatus.PENDING.value, datetime.now()))
# Process payment
payment_result = self.payment_service.charge(
customer_id,
total['total'],
order_id
)
if not payment_result['success']:
self.db.execute("UPDATE orders SET status = %s WHERE id = %s",
(OrderStatus.CANCELLED.value, order_id))
raise PaymentFailedError("Payment failed")
# Update status
self.update_order_status(order_id, OrderStatus.CONFIRMED)
# Publish event to Kafka
self.kafka_producer.send('order-events', {
'event_type': 'order_created',
'order_id': order_id,
'restaurant_id': restaurant_id,
'total': total['total'],
'timestamp': datetime.now().isoformat()
})
return order_id
def calculate_total(self, restaurant_id, items):
"""Calculate order total with taxes and fees."""
# Get menu items and prices
prices = self.get_menu_prices(restaurant_id, [item['menu_item_id'] for item in items])
subtotal = sum(
prices[item['menu_item_id']] * item['quantity']
for item in items
)
# Tax
tax_rate = 0.08 # 8%
tax = subtotal * tax_rate
# Delivery fee (base + distance-based)
delivery_distance = self.get_delivery_distance(restaurant_id, None) # Will add address
delivery_fee = 2.99 + (delivery_distance * 0.5)
# Promotions/discounts
discount = self.apply_promotions(restaurant_id, customer_id, subtotal)
total = subtotal + tax + delivery_fee - discount
return {
'subtotal': subtotal,
'tax': tax,
'delivery_fee': delivery_fee,
'discount': discount,
'total': total
}
def update_order_status(self, order_id, new_status):
"""Update order status and notify parties."""
old_status = self.get_order_status(order_id)
if new_status == old_status:
return
self.db.execute("""
UPDATE orders SET status = %s, updated_at = NOW() WHERE id = %s
""", (new_status.value, order_id))
# Cache invalidation
self.cache.delete(f"order:{order_id}")
# Publish status change event
order = self.get_order(order_id)
self.kafka_producer.send('order-status-updates', {
'order_id': order_id,
'status': new_status.value,
'customer_id': order['customer_id'],
'restaurant_id': order['restaurant_id'],
'timestamp': datetime.now().isoformat()
})
# Send notifications
asyncio.create_task(self.notify_status_change(order, new_status))2. Delivery Service with Real-Time Tracking
import math
class DeliveryService:
def __init__(self):
self.redis = redis.Redis()
self.db = PostgreSQL()
self.route_optimizer = RouteOptimizer()
def assign_delivery(self, order_id, restaurant_location, delivery_address):
"""Assign order to nearest available delivery partner."""
# Find nearby available delivery partners (within 5 km)
partners = self.find_nearby_partners(
restaurant_location,
radius_km=5
)
if not partners:
raise NoAvailableDeliveryError("No delivery partners available")
# Score each partner based on:
# 1. Distance to restaurant
# 2. Current load (orders being delivered)
# 3. Acceptance rate
# 4. Delivery speed rating
scores = []
for partner in partners:
distance = self.calculate_distance(
restaurant_location,
partner['location']
)
load = partner['current_orders'] # Higher load = lower priority
acceptance_rate = partner['acceptance_rate']
speed_rating = partner['avg_delivery_time']
# Weighted score (lower is better)
score = (
distance * 0.4 +
load * 0.3 +
(1 - acceptance_rate) * 20 +
speed_rating * 0.1
)
scores.append((partner['id'], score))
# Select partner with best score
best_partner_id = min(scores, key=lambda x: x[1])[0]
# Create delivery record
delivery_id = str(uuid.uuid4())
self.db.execute("""
INSERT INTO deliveries (id, order_id, delivery_partner_id, status, created_at)
VALUES (%s, %s, %s, 'assigned', NOW())
""", (delivery_id, order_id, best_partner_id))
# Notify delivery partner
asyncio.create_task(self.notify_delivery_partner(
best_partner_id,
order_id,
restaurant_location,
delivery_address
))
return delivery_id
def find_nearby_partners(self, location, radius_km=5):
"""Find available delivery partners using geospatial index."""
# Use Redis geospatial commands
nearby = self.redis.georadius(
'delivery_partners:locations',
location['longitude'],
location['latitude'],
radius_km,
unit='km',
count=50,
sort='ASC'
)
partners = []
for partner_id in nearby:
partner_data = self.redis.hgetall(f"partner:{partner_id}")
if partner_data.get(b'status') == b'available':
partners.append({
'id': partner_id.decode(),
'location': self.get_partner_location(partner_id),
'current_orders': int(partner_data.get(b'current_orders', 0)),
'acceptance_rate': float(partner_data.get(b'acceptance_rate', 0.9)),
'avg_delivery_time': float(partner_data.get(b'avg_delivery_time', 30))
})
return partners
def update_delivery_location(self, delivery_partner_id, latitude, longitude, timestamp=None):
"""Update delivery partner's real-time location."""
location_key = f"partner_location:{delivery_partner_id}"
# Store in Redis geospatial index
self.redis.geoadd(
'delivery_partners:locations',
longitude, latitude,
delivery_partner_id
)
# Store detailed location with timestamp
self.redis.hset(
f"partner:{delivery_partner_id}",
mapping={
'latitude': latitude,
'longitude': longitude,
'last_update': timestamp or time.time()
}
)
# Broadcast location update to customers tracking this delivery
deliveries = self.get_active_deliveries_for_partner(delivery_partner_id)
for delivery in deliveries:
# Notify customer via WebSocket
asyncio.create_task(self.broadcast_location_update(
delivery['order_id'],
delivery_partner_id,
{
'latitude': latitude,
'longitude': longitude,
'timestamp': timestamp or time.time()
}
))
def calculate_distance(self, location1, location2):
"""Calculate distance between two coordinates (Haversine formula)."""
R = 6371 # Earth's radius in km
lat1, lon1 = math.radians(location1['latitude']), math.radians(location1['longitude'])
lat2, lon2 = math.radians(location2['latitude']), math.radians(location2['longitude'])
dlat = lat2 - lat1
dlon = lon2 - lon1
a = math.sin(dlat/2)**2 + math.cos(lat1) * math.cos(lat2) * math.sin(dlon/2)**2
c = 2 * math.asin(math.sqrt(a))
return R * c
def estimate_delivery_time(self, restaurant_location, delivery_location, current_time):
"""Estimate delivery time based on distance, traffic, and partner metrics."""
distance = self.calculate_distance(restaurant_location, delivery_location)
# Get traffic data (via Google Maps API or internal model)
traffic_factor = self.get_traffic_factor(
restaurant_location,
delivery_location,
current_time
)
# Base time: distance / average speed
avg_speed = 30 # km/h
base_time = (distance / avg_speed) * 60 # minutes
# Adjust for traffic
estimated_time = base_time * traffic_factor
# Add buffer for restaurant prep time (already prepared by this point)
# Add buffer for minor delays
estimated_time += 5 # 5 minute buffer
return int(estimated_time)3. Search Service with Filtering
class RestaurantSearchService:
def __init__(self):
self.es = Elasticsearch(['localhost:9200'])
def search_restaurants(self, location, query, filters):
"""Search for restaurants with filters."""
es_query = {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": query,
"fields": ["name^3", "cuisine_types", "description"]
}
},
{
"geo_distance": {
"distance": "5km",
"location": {
"lat": location['latitude'],
"lon": location['longitude']
}
}
}
],
"filter": []
}
},
"size": 20,
"sort": [
{
"_geo_distance": {
"location": {
"lat": location['latitude'],
"lon": location['longitude']
},
"order": "asc",
"unit": "km"
}
}
]
}
# Add filters
if filters.get('cuisine'):
es_query['query']['bool']['filter'].append({
"terms": {"cuisine_types": filters['cuisine']}
})
if filters.get('min_rating'):
es_query['query']['bool']['filter'].append({
"range": {"rating": {"gte": filters['min_rating']}}
})
if filters.get('delivery_time_max'):
es_query['query']['bool']['filter'].append({
"range": {"avg_delivery_time": {"lte": filters['delivery_time_max']}}
})
if filters.get('price_level'):
es_query['query']['bool']['filter'].append({
"terms": {"price_level": filters['price_level']}
})
results = self.es.search(index="restaurants", body=es_query)
# Format results
restaurants = []
for hit in results['hits']['hits']:
restaurant = hit['_source']
restaurant['distance_km'] = hit['sort'][0]
restaurants.append(restaurant)
return restaurants4. Dynamic Pricing Service
class PricingService:
def __init__(self):
self.redis = redis.Redis()
self.ml_model = self.load_demand_model()
def calculate_delivery_fee(self, order_id, restaurant_location, delivery_location,
order_time=None):
"""Calculate dynamic delivery fee based on demand."""
if order_time is None:
order_time = datetime.now()
# Base distance
distance = self.calculate_distance(restaurant_location, delivery_location)
base_fee = 2.99 + (distance * 0.5)
# Demand multiplier (surge pricing)
demand_level = self.estimate_demand(order_time)
# demand_level values: 1.0 (normal) to 2.0+ (surge)
# Capped at 2.5x to prevent excessive surge
demand_multiplier = min(demand_level, 2.5)
# Check for promotions/discounts
discount = self.get_applicable_promotions(
restaurant_location,
delivery_location,
order_time
)
final_fee = base_fee * demand_multiplier
final_fee = max(0, final_fee - discount) # Can't go negative
return round(final_fee, 2)
def estimate_demand(self, order_time):
"""Estimate current demand using ML model."""
# Features: hour of day, day of week, recent order count, weather, etc.
hour = order_time.hour
day_of_week = order_time.weekday()
# Get recent order count (last 30 minutes)
recent_orders_key = f"orders:recent:{int(order_time.timestamp() / 1800)}"
recent_count = int(self.redis.get(recent_orders_key) or 0)
# Predict demand
features = [hour, day_of_week, recent_count]
demand_level = self.ml_model.predict([features])[0]
return demand_level
def get_applicable_promotions(self, restaurant_location, delivery_location, order_time):
"""Find applicable promotions for order."""
promotions = []
# Time-based promotions (lunch rush, late night, etc.)
hour = order_time.hour
if 23 <= hour or hour < 6:
promotions.append(('late_night_discount', 0.50))
# Location-based promotions
# ...
# First-time user promotion
# ...
# Maximum discount
return min(promo[1] for promo in promotions) if promotions else 0Scalability Optimizations
1. Geographic Sharding:
- Shard data by region/city
- Deploy services in each region for low latency
2. Redis Geospatial Index:
- Track all active delivery partners and their locations
- Fast nearest-neighbor queries
3. Event-Driven Architecture:
- Kafka for order events
- Asynchronous updates to analytics, ratings, etc.
4. Caching Strategy:
- Restaurant data: 1-hour TTL
- Menu data: 2-hour TTL
- Delivery locations: Real-time (Redis)
5. Database Optimization:
- Orders: PostgreSQL (strong consistency needed)
- Delivery history: Cassandra (time-series data)
- Locations: Redis (real-time)
Key Takeaways
- Geospatial indexing - Critical for location-based matching
- Real-time tracking - WebSocket for live delivery updates
- Dynamic pricing - ML-based demand estimation
- Intelligent assignment - Score-based delivery partner matching
- Regional deployment - Minimize latency for critical operations
- Event sourcing - Track all state changes for auditing
- Eventual consistency - Between regions is acceptable
Section 48: Advanced System Design Topics
Testing Distributed Systems
Challenges in Testing Distributed Systems:
- Non-deterministic behavior
- Network partitions
- Race conditions
- Timing issues
Testing Strategies:
# Example: Chaos Engineering Test
class ChaosTest:
def __init__(self, system):
self.system = system
def test_network_partition(self):
"""Simulate network partition between nodes."""
# Isolate node from cluster
self.system.isolate_node('node-2')
# Verify system continues operating
assert self.system.is_available()
# Restore network
self.system.restore_node('node-2')
# Verify data consistency
assert self.system.verify_consistency()
def test_node_failure(self):
"""Test system behavior when node crashes."""
self.system.kill_node('node-1')
# Verify failover
assert self.system.leader_elected()
assert self.system.is_available()
def test_latency_injection(self):
"""Inject random latencies to find race conditions."""
self.system.inject_latency(min_ms=100, max_ms=500)
# Run concurrent operations
results = self.system.concurrent_writes(count=1000)
# Verify eventual consistency
self.system.wait_for_convergence()
assert self.system.verify_consistency()Tools:
- Jepsen - Distributed systems testing framework
- TLA+ - Formal specification language (by Leslie Lamport)
- Chaos Monkey (Netflix) - Random failure injection
Distributed Consensus Algorithms
Paxos Algorithm:
class PaxosNode:
def __init__(self, node_id):
self.node_id = node_id
self.promised_id = None
self.accepted_id = None
self.accepted_value = None
# Phase 1a: Proposer sends Prepare(n)
def prepare(self, proposal_id):
if proposal_id > (self.promised_id or 0):
self.promised_id = proposal_id
return {
'promised': True,
'accepted_id': self.accepted_id,
'accepted_value': self.accepted_value
}
return {'promised': False}
# Phase 2a: Proposer sends Accept(n, value)
def accept(self, proposal_id, value):
if proposal_id >= (self.promised_id or 0):
self.promised_id = proposal_id
self.accepted_id = proposal_id
self.accepted_value = value
return {'accepted': True}
return {'accepted': False}Raft Consensus (Simplified):
- Leader election
- Log replication
- Safety guarantees
Time Series Databases
Use Cases:
- Metrics monitoring
- IoT sensor data
- Financial market data
- Application performance monitoring (APM)
Design Considerations:
class TimeSeriesDB:
def __init__(self):
self.segments = {} # time_bucket -> data
self.compression_enabled = True
def write(self, metric_name, timestamp, value, tags=None):
"""Write time series data point."""
# Determine time bucket (e.g., hourly)
time_bucket = self.get_time_bucket(timestamp)
# Create segment if not exists
if time_bucket not in self.segments:
self.segments[time_bucket] = TimeSeriesSegment(time_bucket)
# Append to segment
self.segments[time_bucket].append({
'metric': metric_name,
'timestamp': timestamp,
'value': value,
'tags': tags or {}
})
# Compress old segments
if len(self.segments) > 24: # Keep 24 hours hot
self.compress_old_segments()
def query(self, metric_name, start_time, end_time, aggregation='avg'):
"""Query time series data with aggregation."""
results = []
# Find relevant segments
segments = self.get_segments_in_range(start_time, end_time)
for segment in segments:
data_points = segment.get_metric(metric_name)
results.extend(data_points)
# Aggregate
if aggregation == 'avg':
return sum(r['value'] for r in results) / len(results)
elif aggregation == 'max':
return max(r['value'] for r in results)
elif aggregation == 'min':
return min(r['value'] for r in results)
return results
def compress_old_segments(self):
"""Compress segments older than 24 hours."""
cutoff = datetime.now() - timedelta(hours=24)
for time_bucket, segment in list(self.segments.items()):
if segment.timestamp < cutoff:
# Downsample and compress
compressed = segment.downsample(factor=10)
self.segments[time_bucket] = compressedPopular Time Series DBs:
- InfluxDB
- Prometheus
- TimescaleDB (PostgreSQL extension)
- Facebook Gorilla
Authorization Systems
Role-Based Access Control (RBAC):
class RBACSystem:
def __init__(self):
self.roles = {} # role_name -> permissions
self.user_roles = {} # user_id -> [role_names]
def create_role(self, role_name, permissions):
"""Create role with permissions."""
self.roles[role_name] = set(permissions)
def assign_role(self, user_id, role_name):
"""Assign role to user."""
if user_id not in self.user_roles:
self.user_roles[user_id] = []
self.user_roles[user_id].append(role_name)
def check_permission(self, user_id, resource, action):
"""Check if user has permission."""
user_roles = self.user_roles.get(user_id, [])
for role in user_roles:
permissions = self.roles.get(role, set())
if f"{resource}:{action}" in permissions:
return True
return False
# Usage
rbac = RBACSystem()
rbac.create_role('admin', ['user:create', 'user:read', 'user:update', 'user:delete'])
rbac.create_role('viewer', ['user:read'])
rbac.assign_role('user123', 'admin')
rbac.check_permission('user123', 'user', 'delete') # TrueAttribute-Based Access Control (ABAC):
- More flexible than RBAC
- Uses attributes (user, resource, environment)
- Example: “Allow if user.department == resource.department”
Batch vs Stream Processing
Batch Processing (MapReduce):
# Map function
def map_word_count(document):
words = document.split()
return [(word, 1) for word in words]
# Reduce function
def reduce_word_count(word, counts):
return (word, sum(counts))
# MapReduce framework
class MapReduce:
def __init__(self, num_workers=4):
self.num_workers = num_workers
def run(self, documents, map_fn, reduce_fn):
# Map phase (parallel)
mapped = []
with ThreadPoolExecutor(max_workers=self.num_workers) as executor:
futures = [executor.submit(map_fn, doc) for doc in documents]
for future in futures:
mapped.extend(future.result())
# Shuffle phase (group by key)
shuffled = {}
for key, value in mapped:
if key not in shuffled:
shuffled[key] = []
shuffled[key].append(value)
# Reduce phase (parallel)
results = []
with ThreadPoolExecutor(max_workers=self.num_workers) as executor:
futures = [
executor.submit(reduce_fn, key, values)
for key, values in shuffled.items()
]
results = [future.result() for future in futures]
return resultsStream Processing (Kafka Streams):
from kafka import KafkaConsumer, KafkaProducer
import json
class StreamProcessor:
def __init__(self, input_topic, output_topic):
self.consumer = KafkaConsumer(
input_topic,
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
self.producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda m: json.dumps(m).encode('utf-8')
)
self.output_topic = output_topic
# Windowed aggregation state
self.windows = {} # window_key -> aggregate
def process(self):
"""Process stream with windowed aggregation."""
for message in self.consumer:
event = message.value
# Extract timestamp and create window key
timestamp = event['timestamp']
window_key = self.get_window_key(timestamp, window_size=60)
# Update window aggregate
if window_key not in self.windows:
self.windows[window_key] = {'count': 0, 'sum': 0}
self.windows[window_key]['count'] += 1
self.windows[window_key]['sum'] += event['value']
# Emit windowed aggregate
self.producer.send(self.output_topic, {
'window': window_key,
'avg': self.windows[window_key]['sum'] / self.windows[window_key]['count'],
'count': self.windows[window_key]['count']
})
def get_window_key(self, timestamp, window_size):
"""Get window key for tumbling window."""
return int(timestamp / window_size) * window_sizeService Mesh
What is Service Mesh?
- Infrastructure layer for service-to-service communication
- Handles service discovery, load balancing, encryption, authentication
- Popular: Istio, Linkerd, Consul
Key Components:
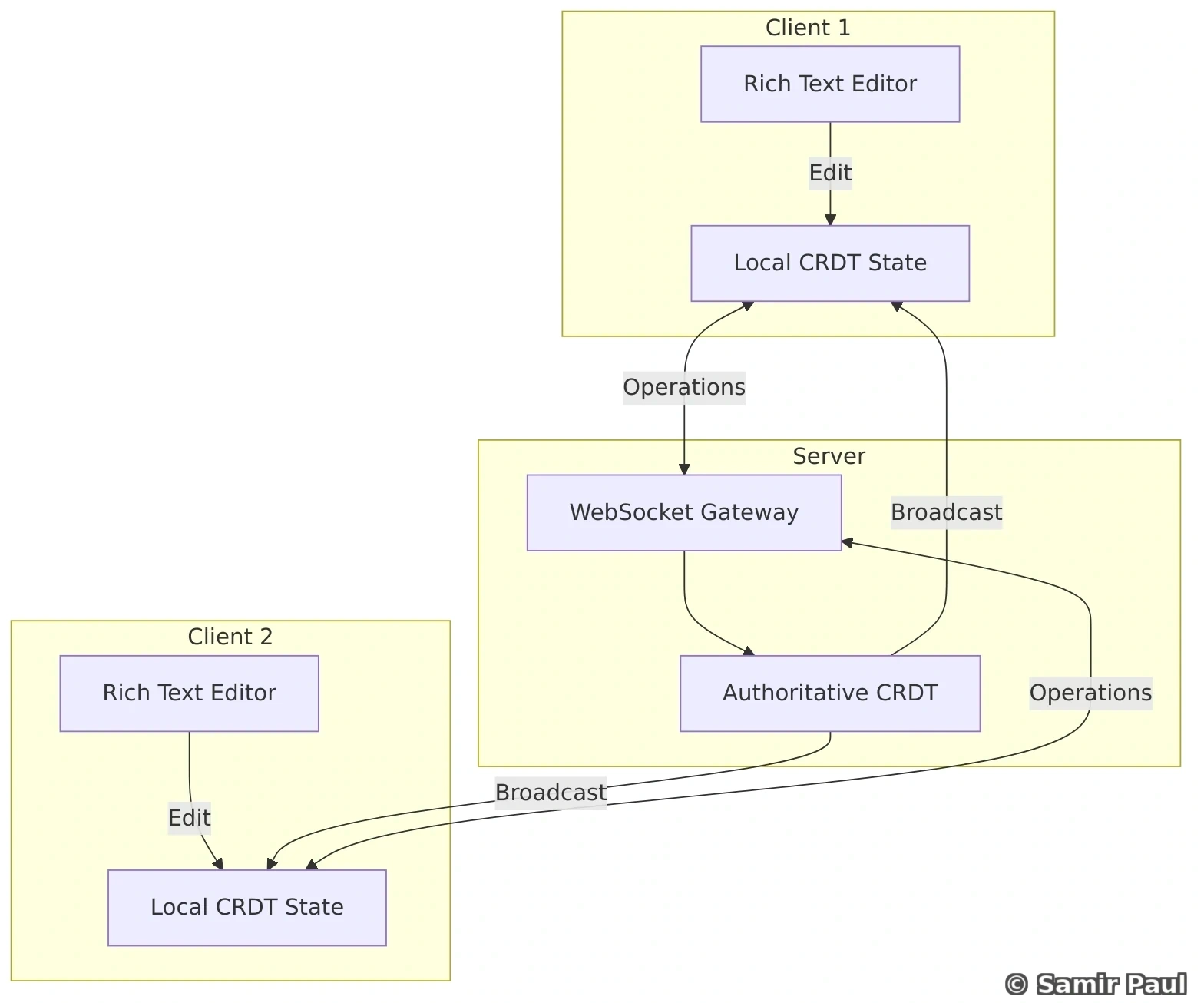
Benefits:
- Automatic retries and circuit breaking
- Mutual TLS encryption
- Distributed tracing
- Traffic shaping and routing
Distributed Logging and Tracing
Distributed Tracing Architecture:
import uuid
from datetime import datetime
class Span:
def __init__(self, trace_id, span_id, parent_span_id, operation_name):
self.trace_id = trace_id
self.span_id = span_id
self.parent_span_id = parent_span_id
self.operation_name = operation_name
self.start_time = datetime.now()
self.end_time = None
self.tags = {}
self.logs = []
def set_tag(self, key, value):
self.tags[key] = value
def log(self, message):
self.logs.append({
'timestamp': datetime.now(),
'message': message
})
def finish(self):
self.end_time = datetime.now()
def duration_ms(self):
if self.end_time:
return (self.end_time - self.start_time).total_seconds() * 1000
return None
class Tracer:
def __init__(self, service_name):
self.service_name = service_name
self.spans = []
def start_span(self, operation_name, parent_span=None):
"""Start a new span."""
trace_id = parent_span.trace_id if parent_span else str(uuid.uuid4())
span_id = str(uuid.uuid4())
parent_span_id = parent_span.span_id if parent_span else None
span = Span(trace_id, span_id, parent_span_id, operation_name)
span.set_tag('service.name', self.service_name)
self.spans.append(span)
return span
def inject(self, span, carrier):
"""Inject span context into carrier (e.g., HTTP headers)."""
carrier['X-Trace-Id'] = span.trace_id
carrier['X-Span-Id'] = span.span_id
def extract(self, carrier):
"""Extract span context from carrier."""
return {
'trace_id': carrier.get('X-Trace-Id'),
'parent_span_id': carrier.get('X-Span-Id')
}
# Usage example
tracer = Tracer('api-service')
# In API handler
def handle_request(request):
# Extract parent span context
parent_context = tracer.extract(request.headers)
# Start span
span = tracer.start_span('handle_api_request')
if parent_context['parent_span_id']:
span.parent_span_id = parent_context['parent_span_id']
span.trace_id = parent_context['trace_id']
span.set_tag('http.method', request.method)
span.set_tag('http.url', request.url)
try:
# Process request
result = process_request(request, span)
span.set_tag('http.status_code', 200)
return result
except Exception as e:
span.set_tag('error', True)
span.log(f"Error: {str(e)}")
raise
finally:
span.finish()Popular Tracing Systems:
- Jaeger (Uber)
- Zipkin (Twitter)
- AWS X-Ray
- Google Cloud Trace
Anomaly Detection Systems
Statistical Anomaly Detection:
import numpy as np
from sklearn.ensemble import IsolationForest
class AnomalyDetector:
def __init__(self):
self.model = IsolationForest(contamination=0.01) # 1% anomalies
self.trained = False
def train(self, historical_data):
"""Train on historical metrics."""
# historical_data: array of [cpu, memory, latency, error_rate]
self.model.fit(historical_data)
self.trained = True
def detect(self, current_metrics):
"""Detect if current metrics are anomalous."""
if not self.trained:
raise ValueError("Model not trained")
prediction = self.model.predict([current_metrics])
# -1 = anomaly, 1 = normal
return prediction[0] == -1
def get_anomaly_score(self, metrics):
"""Get anomaly score (lower = more anomalous)."""
return self.model.score_samples([metrics])[0]
# Usage
detector = AnomalyDetector()
# Train on normal data
historical_data = np.array([
[50, 60, 100, 0.1], # [CPU%, Memory%, Latency ms, Error%]
[55, 62, 105, 0.12],
[52, 58, 98, 0.09],
# ... more normal samples
])
detector.train(historical_data)
# Check current metrics
current = [95, 90, 500, 5.0] # High CPU, memory, latency, errors
if detector.detect(current):
print("Anomaly detected! Alert the team.")Section 49: References and Further Reading
📚 Essential Books
“Designing Data-Intensive Applications” by Martin Kleppmann
- The definitive guide to distributed systems
- Covers replication, partitioning, transactions, consensus
“System Design Interview” by Alex Xu (Vol 1 & 2)
- Practical interview preparation
- Real-world system designs
“Database Internals” by Alex Petrov
- Deep dive into database storage engines
- LSM trees, B-trees, replication
“Designing Distributed Systems” by Brendan Burns
- Patterns for Kubernetes and containers
- Microservices architectures
“Site Reliability Engineering” by Google
- SRE practices from Google
- Monitoring, incident response, automation
🌐 Engineering Blogs
Recommended Reading:
Netflix Tech Blog: https://netflixtechblog.com/
- Microservices, chaos engineering, CDN
Uber Engineering: https://eng.uber.com/
- Geospatial systems, real-time data processing
Meta Engineering: https://engineering.fb.com/
- Scale challenges, distributed systems
Twitter Engineering: https://blog.twitter.com/engineering
- Real-time systems, graph databases
LinkedIn Engineering: https://engineering.linkedin.com/
- Data infrastructure, Kafka
Airbnb Engineering: https://medium.com/airbnb-engineering
- Microservices, ML infrastructure
Pinterest Engineering: https://medium.com/@Pinterest_Engineering
- Visual search, recommendation systems
Dropbox Engineering: https://dropbox.tech/
- Distributed file systems, sync
Spotify Engineering: https://engineering.atspotify.com/
- Event-driven architecture, ML
Instagram Engineering: https://instagram-engineering.com/
- Photo storage, feed ranking
📝 Important Papers
“The Google File System” (GFS)
- Distributed file system fundamentals
“MapReduce: Simplified Data Processing on Large Clusters”
- Batch processing framework
“Bigtable: A Distributed Storage System”
- NoSQL database design
“Dynamo: Amazon’s Highly Available Key-value Store”
- Eventual consistency, consistent hashing
“The Chubby Lock Service”
- Distributed locking and coordination
“Spanner: Google’s Globally-Distributed Database”
- Globally consistent transactions
“Kafka: a Distributed Messaging System”
- Log-based message queue
“Raft Consensus Algorithm”
- Understandable distributed consensus
🎓 Online Courses
- MIT 6.824 Distributed Systems (Free on YouTube)
- Grokking the System Design Interview (educative.io)
- System Design for Tech Interviews (Udemy)
- Distributed Systems by Chris Colohan (Coursera)
🛠️ Tools and Frameworks
Databases:
- PostgreSQL, MySQL (SQL)
- MongoDB, Cassandra, DynamoDB (NoSQL)
- Redis, Memcached (Cache)
- Elasticsearch (Search)
Message Queues:
- Apache Kafka
- RabbitMQ
- AWS SQS/SNS
- Google Pub/Sub
Infrastructure:
- Kubernetes (Container orchestration)
- Docker (Containerization)
- Terraform (Infrastructure as Code)
- Prometheus + Grafana (Monitoring)
Load Balancers:
- NGINX
- HAProxy
- AWS ELB/ALB
- Google Cloud Load Balancing
💡 System Design Patterns Summary
| Pattern | Use Case | Example |
|---|---|---|
| Load Balancing | Distribute traffic | NGINX, HAProxy |
| Caching | Reduce latency | Redis, CDN |
| Sharding | Scale database | Hash-based, Range-based |
| Replication | High availability | Master-Slave, Multi-Master |
| Rate Limiting | Prevent abuse | Token bucket, Sliding window |
| Circuit Breaker | Fault tolerance | Netflix Hystrix |
| CQRS | Separate read/write | Event sourcing |
| Event Sourcing | Audit trail | Kafka, EventStore |
| Saga | Distributed transactions | Choreography, Orchestration |
| Bulkhead | Isolation | Thread pools, Process isolation |
🎯 Interview Preparation Checklist
Fundamentals:
- ✅ CAP theorem
- ✅ Consistency models
- ✅ Load balancing algorithms
- ✅ Caching strategies
- ✅ Database indexing
- ✅ Sharding and partitioning
Advanced Topics:
- ✅ Distributed transactions
- ✅ Consensus algorithms (Paxos, Raft)
- ✅ Consistent hashing
- ✅ Rate limiting
- ✅ Monitoring and alerting
- ✅ Security best practices
System Designs:
- ✅ URL shortener
- ✅ Twitter/social media
- ✅ Chat system
- ✅ Video streaming (YouTube)
- ✅ E-commerce platform
- ✅ Ride-sharing service
- ✅ Food delivery system
- ✅ Search engine
- ✅ Notification system
- ✅ Collaborative editor
🔗 Online Resources
- System Design Primer (GitHub): github.com/donnemartin/system-design-primer
- High Scalability Blog: highscalability.com
- ByteByteGo: blog.bytebytego.com
- InterviewReady: interviewready.io
- System Design Daily: systemdesigndaily.com
📊 Key Metrics to Know
| Metric | Value | Context |
|---|---|---|
| L1 cache reference | 0.5 ns | CPU cache |
| L2 cache reference | 7 ns | CPU cache |
| RAM reference | 100 ns | Main memory |
| SSD random read | 150 μs | Storage |
| HDD seek | 10 ms | Storage |
| Network within datacenter | 0.5 ms | Internal |
| Network between continents | 150 ms | Global |
| Read 1MB from RAM | 250 μs | Sequential |
| Read 1MB from SSD | 1,000 μs | Sequential |
| Read 1MB from HDD | 20,000 μs | Sequential |
End of System Design Complete Guide
Remember: System design is about trade-offs. There’s no single “right” answer—only solutions that better fit specific requirements and constraints.
Good luck with your interviews and building amazing systems! 🚀